 Ari
AriI made a scrapper script in python to download full-res manuals from Serv L1b à la Sci-Hub and turn them into PDF
Access the manuals from ServLib.
This is for educational purposes on how to find and archive data. Who the heck would need the manual for a KX-FT33LA Thermal Printing Fax Machine
The code is quite explained, but you can direct any questions by submitting an issue or messaging me at @AriZoneVibes :
You can find the file in my GitHub
You will need to have python installed on your computer.
Once installed, run the following commands to install the libraries needed to run the script
requests - Used to make HTTP requests. Will ask the website for the image.
pip install requests
pyFPDF - Library for PDF document generation. We will use it to take the downloaded images and place them into a pdf
pip install fpdf
Obtaining the link
As an example I'll be using the manual for KX-FT33LA Fax Machine, browsing through Firefox
Access the manual, right-click over the page/image and click "Inspect Element".
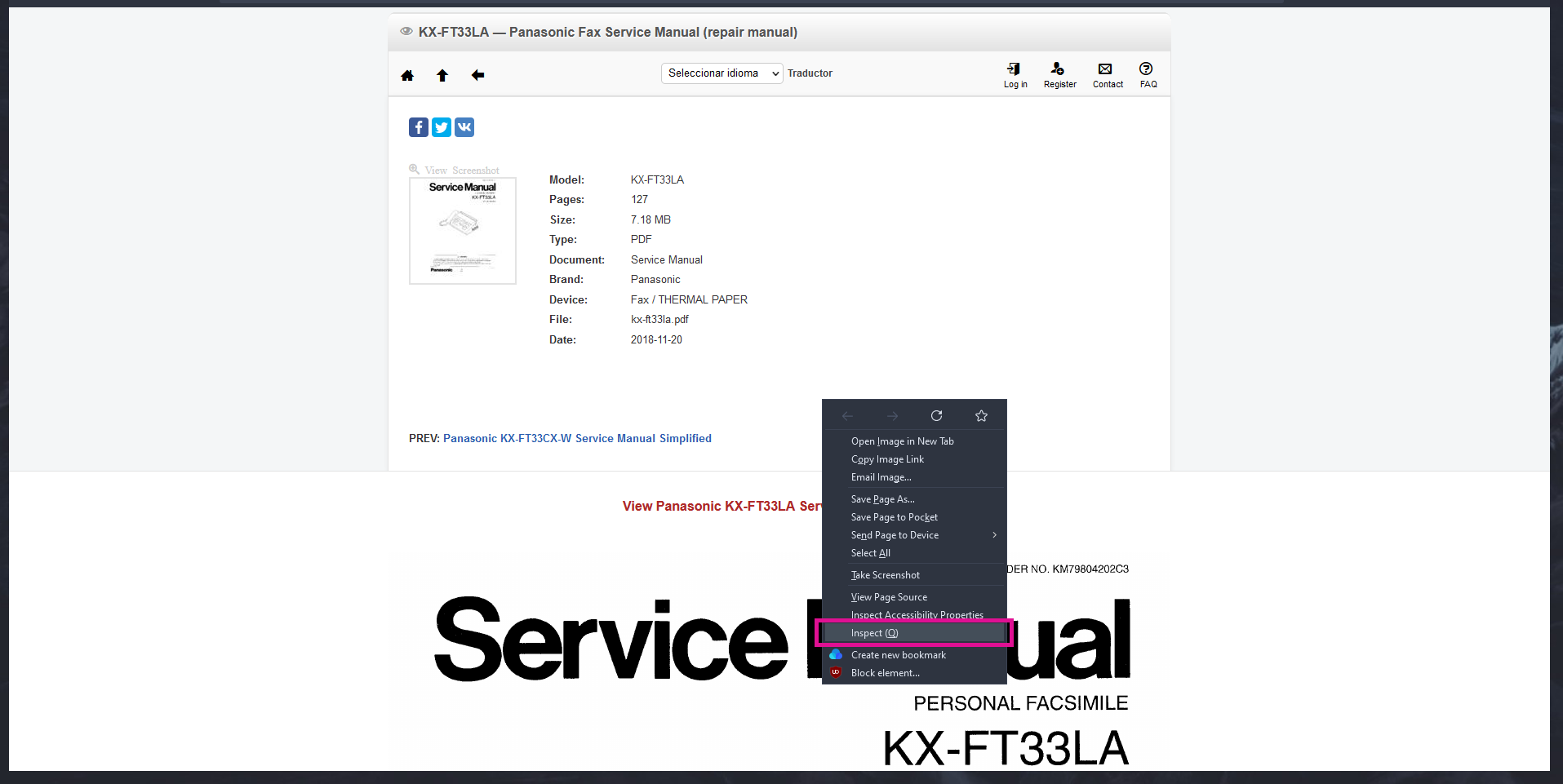
On the developer console, go to the upper menus and press "Network". (It might ask you to reload)
Browse for the .PNG files on the list that shows up. Hover over it and should show a thumbnail. Confirm it's from the manual you are browsing and click.
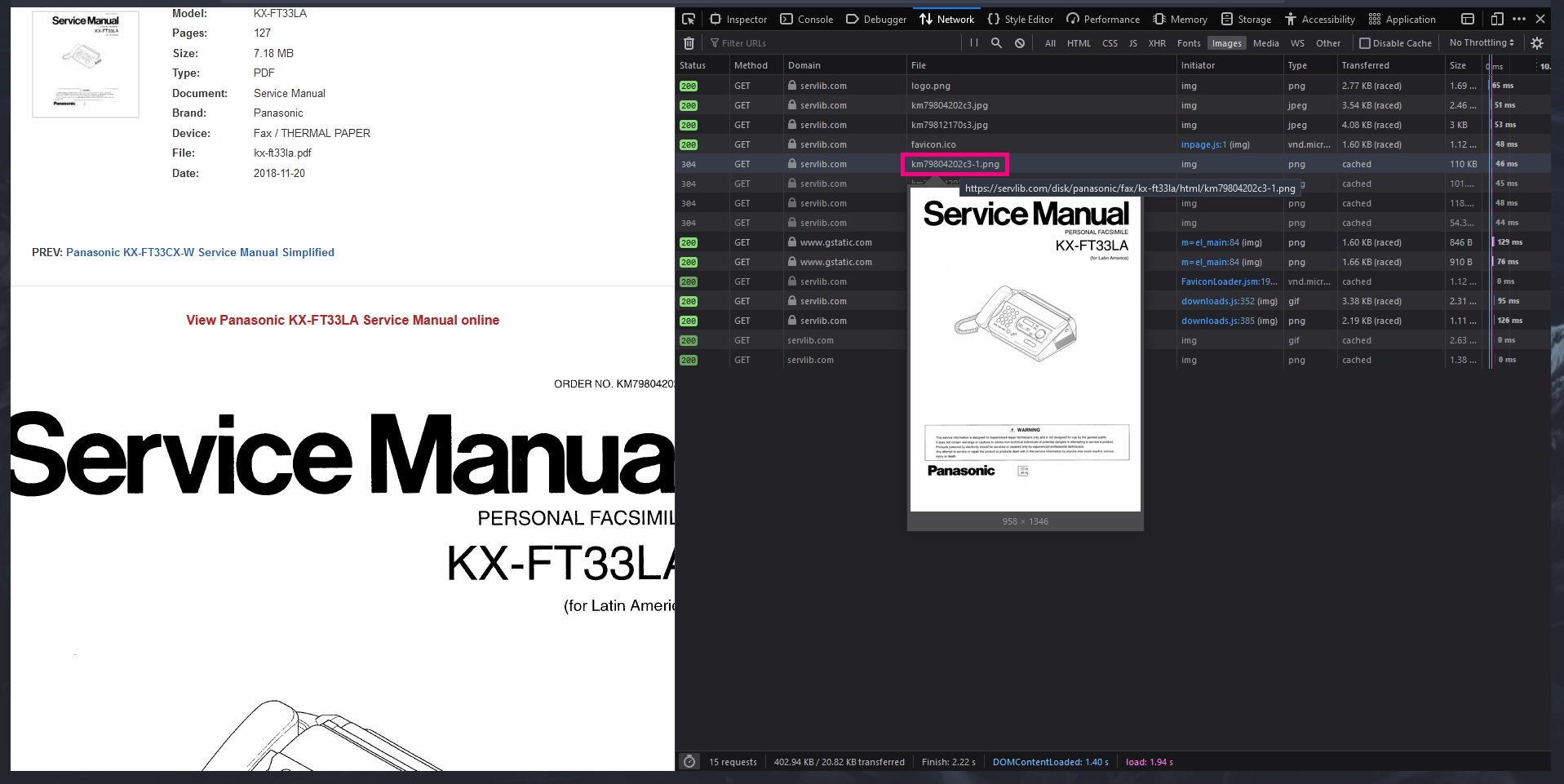
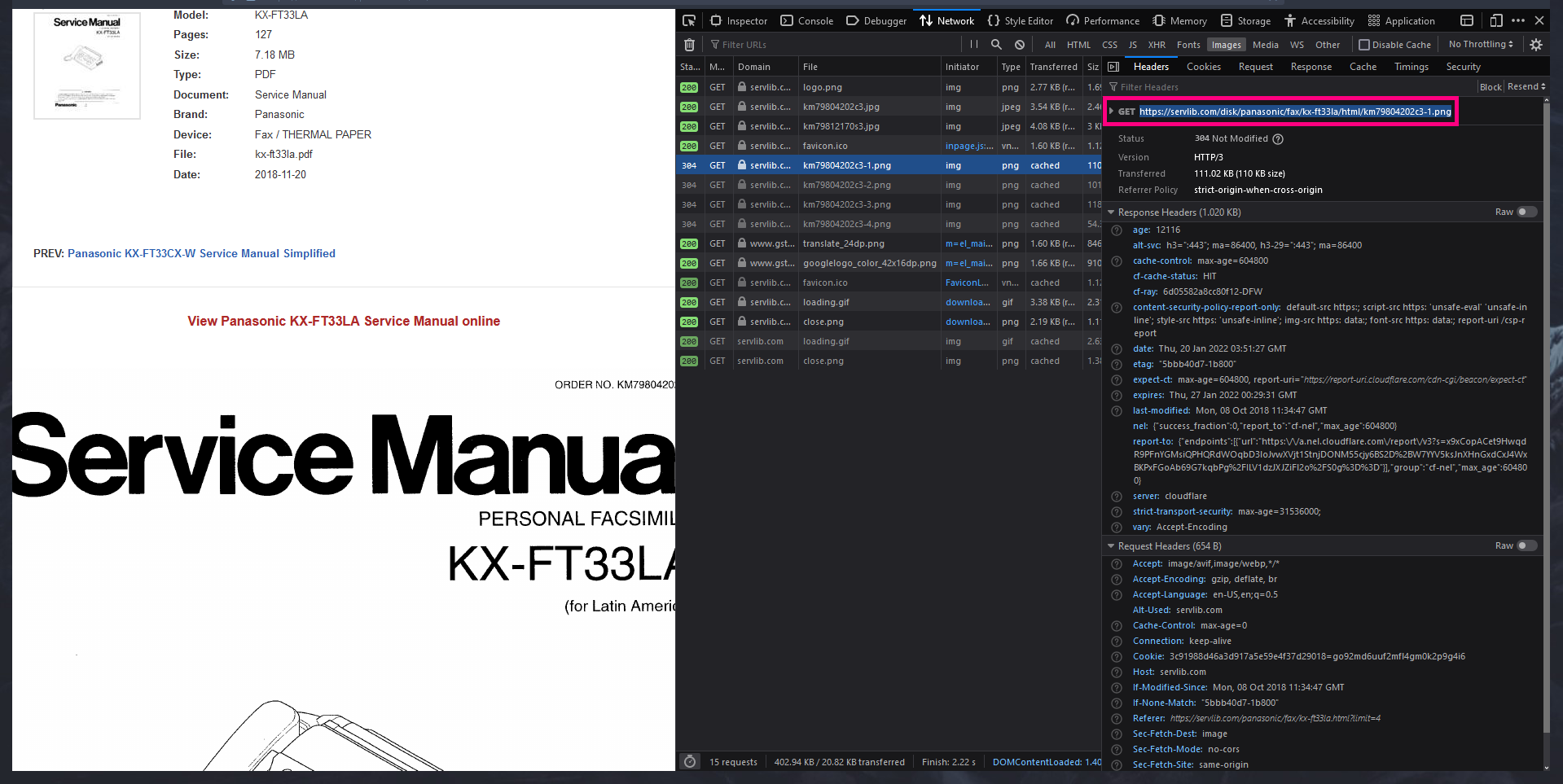
Another view should open. Copy the link after GET and continue, we will now work on the script.
Script
Open Scrapper.py file in your favorite text editor. Modify the settings according to the pages you need and if it should make a PDF file from all the pages.
#Settings Url = "https://servlib.com/disk/panasonic/fax/kx-ft33la/html/km79804202c3-1.png" #Url you got on the previous step, should look like: https://servlib.com/disk/panasonic/fax/kx-ft33la/html/km79804202c3-1.png StartPage = 1 #First page to export EndPage = 127 #Last page to export MakePdf = True #If will export the final file as PDF
The last page value is as indexed on the website, not on the manual itself.
Save the file and open a terminal in the location where you want your files stored. Lastly, run the script. Will display the progress as the images are downloaded.
python3 Scrapper.py
If you want to learn more about how the script works you can find information on the comments inside the Scrapper.py file
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.