 Yann Guidon / YGDES
Yann Guidon / YGDESAfter a week of thinking about all the aspect of this "AMBAP", I realise that it is much more than what I thought.
It started as a toy idea that needed to be convenient, conceptually minimalist yet self-sufficient for making a reasonably RISC-y machine.
To my surprise, along the way, it brings a really minimal critical dapatath. This translates in raw speed. This thing can go fast and I'll see how fast I can go with it, either with relays, germanium or silicium, ECL or TTL :-)
Each bitslice contains all the necessary elementary parts of a computer : you can make it with the usual gates AND, OR, XOR, MUX and latch. It is not just educational : it also reduces the burden of the design and analysis of the ALU and register set. Design for one bit and you have the behaviour of all the bits, no uncertainty !
But there is more to this approach, which brings a new perspective and more appeal. The bitslice point of view has reduced the absolute critical datapath to this of the adder's carry chain. This means that it is the only aspect to optimise and the rest can be organised around it.
This is a major thing for ASICs. In integrated circuits (CMOS), wiring delays are as prominent as gate delays. So this single optimisation criterion becomes a natural geometric constraint. The high-speed part (the adder) becomes the center of the unit, to keep wires short, and the other gates are litterally spread around this core.
Since a circle is highly symmetrical and all the bits are identical, the design is extremely simple and all you have to design is one slice, not like a slice of bread but a slice of pie :-)
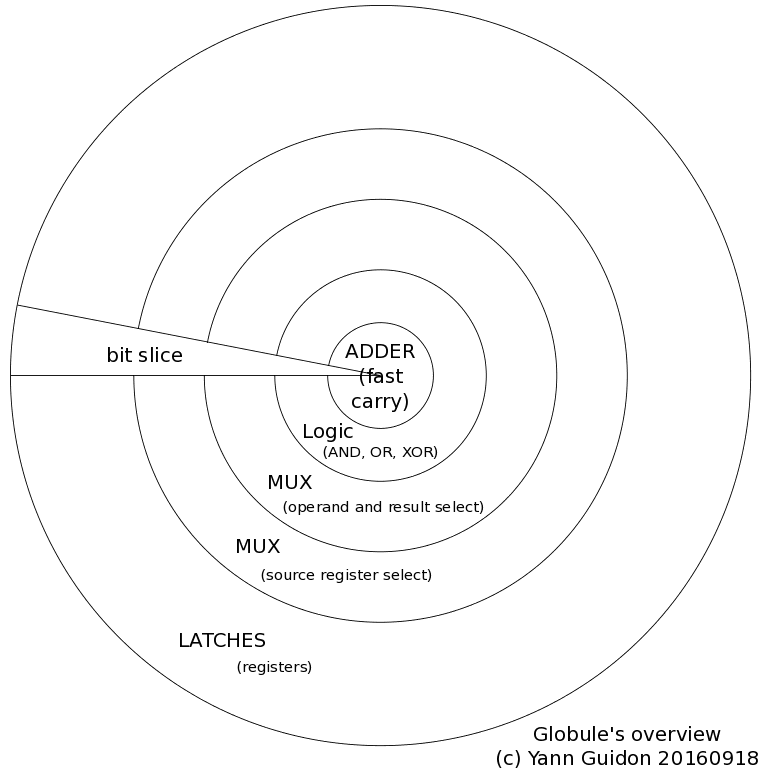
Asymptotically, when the number of bits increases, the angle of the pie slice nears 0 and becomes almost flat.
Another remark is that this also works naturally well with fanout trees : there are many control signals to broadcast throughout the whole unit and the centrally symmetric design is perfect!
Of course, I still have to analyse how to optimise the adder's datapath. @roelh has provided some important insight in the comments of the project :-)
But so far, I can analyse the design with relays, transistors, ICs, and I have suitable FPGA to test the integrated version. I still use the old ProASIC3 because its granularity is close to the logic gates we use, giving a pretty accurate feeling of what would happen in a full custon ASIC.
I wasn't aiming at speed but it's so fast I can't go any faster. Maybe add a pipeline gate here or there. It is so minimalistic that it's worthless to include pipeline bypass. More complex operations (multiply and barrel shifter) must be performed by external units, in multi-cycle fashion.
The big issue remains: the control lines, with many very high fanout, consume power and wires.
Now, since the datapath is looking totally different, I found a name for the ALU+REG-datapath: "Globule". In a given implementation, you could use one or several globules for increased ILP :-)
There are many benefits of the approach I am developing now. They will heavily influence the design of the #YASEP Yet Another Small Embedded Processor and #F-CPU. But more than that: you can just forget about the canonical RISC pipeline of Patterson and Hennessy. Just design one bit, copy-paste-rotate, and you have your datapath. All the fun stuff will now be relegated to designing your instruction set and scheduling :-)
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.