 ReVision
ReVisionMy concept is to break language in to 4 groups of 8 phonemes. Additional sounds would be created by combining these like you would colours, for example the word 'of' would begin with the 'o' sound, and 'us' would begin with the 'u' sound, but the vowels in the word 'boot' would trigger both the 'o' and 'u''.
My example of how the channels are broken down.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Soft consonants Quiet | C/S(+ch/sh) | F/Ph/Gh/J | H | Th | W | Y | * | * |
| Soft consonants Loud | L | M | N | R | V | X | Z | * |
| Hard consonants | B | C/K/Q | D | G | J | P | T | * |
| Vowels | A | E | I | O | U | * | * | * |
*denotes spare channels, which would probably be assigned later, or used as a modifier like an accent.
The output box would be fed via a serial stream at a suitable speed that could be determined by experiment, but as fast speech is 10 syllables per second, then a sample rate of 50 phonemes per second should be the bare minimum.
If the signal running as 1 bit per phoneme then each sample would be 32bit uncompressed, with each phoneme type being represented by 2 hexadecimal digits
in this instance the word 'wigwam' would be
00001000 00000000 00000000 00000000 #08000000 W
00000000 00000000 00000000 00100000 #00000020 "I"
00000000 00000000 00010000 0000000 #00002000 "G"
00001000 00000000 00000000 00000000 #08000000 W
00000000 00000000 00000000 10000000 #00000080 "A"
00000000 01000000 00000000 00000000 #00400000 "M"
As a scripted file, in the manner of standard subtitle files each line starts as follows...
hh:mm:ss.mms
hh is hours
mm is minutes
ss is seconds
mms is milliseconds
so the above script would be...
00:00:00.00 #08000000
00:00:00.10 #00000020
00:00:00.20 #00002000
00:00:00.30 #08000000
00:00:00.40 #00000080
00:00:00.50 #00400000
00:00:00.55 #00000000
the last part being return to silence.
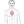
Possible pattern of contact points.
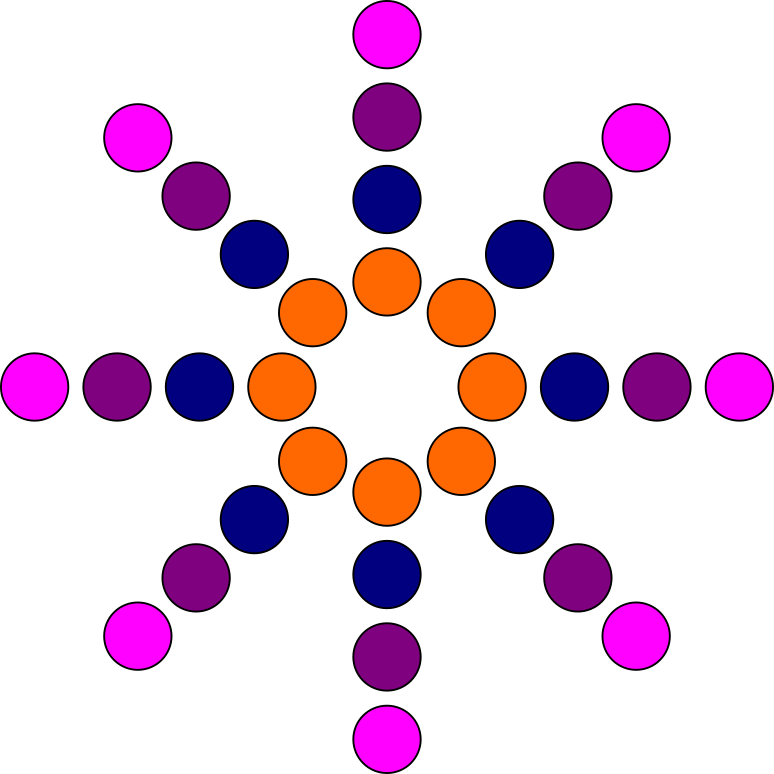
Improved pattern of contact points.
Any thought would be appreciated.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.