 Nick Bild
Nick Bild![]()
Gemini Project
Gemini Project demonstrates a method to create a functionally identical copy of software using deep learning. The software to be copied is not needed (neither the source code, nor the binary); only prior input/output data is required.
The copy operates exactly like the original software, but uses none of the original source code or proprietary algorithms. It is de novo self-programmed software.
See a working example here.
Overview
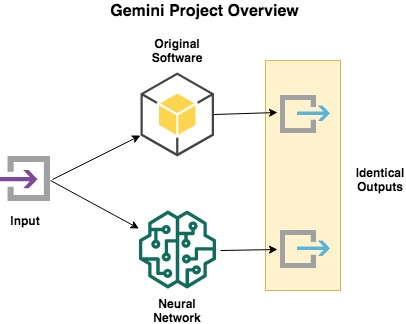
I have constructed a deep feed-forward neural network that can be trained on an input/output data set from an existing application. The training process generates a model that recreates the function of, but is implemented in a completely different way than, the original software.
Uses
This method can be used if the original software has been lost, but prior data exists. A functional copy of the missing software can be created from the data alone.
It would also be very easy to port software to different platforms, even if the source code has been lost. You need that Apple II software running on your iPhone? That's possible.
It hasn't escaped my notice that this method could also be used to clone proprietary software in an effort to circumvent restrictions in the software license, or avoid paying the original developer. I don't know the legality of doing this, but it does not seem ethical, and I do not endorse using the method for such a purpose.
Scope
The current implementation will work to recreate deterministic applications (i.e. some set of inputs generates a set of outputs repeatably). The current method would not work for applications with stochastic elements, or if the outputs are dependent on additional sources of state (e.g. saved data on a disk, a hardware timer, etc.). I think some of these limitations could be overcome with additional research and data sources (e.g. reading disk and memory data into the model), but was not the initial goal of this project, and may be computationally infeasible for a few more years.
Training
I trained an eight layer feed-forward neural network. Understanding that a user of the software may not have a vast amount of I/O data from the original software available, I trained on a very modest data set of only 500 inputs. For more complex applications, I anticipate a significantly larger data set would be needed.
Original Software
I wrote a small, but not entirely trivial, application to prove the concept (black_box.py). I automatically generated a training set of 500 inputs and outputs with generate_data.py.
Neural Network
The model was implemented in PyTorch (train.py). The deep neural network was trained for ~162K epochs and resulted in the model gemini_161960_96.0.model.
The training had a tendency to get "stuck" on local minima while trying to learn the non-linear aspects of the original software and required lots of fiddling with the learning rate. I tried various adaptive scheduling mechanisms to overcome the problem, but due to the stochastic nature of the initial conditions and parameter updates, nothing made the corrections at the right times. To solve the problem, I used Human-Assisted Learning Rate Adjustment (yes, I just made that up).
The algorithm would read the desired learning rate from a text file every 100 epochs, allowing me to update it as needed. It was very hands on, but it worked well. It allowed me to "rock" the learning rate back and forth a bit to find better parameters and push the training error down -- somewhat analogous to rocking a car stuck in snow to break free.
AWS
I trained on g3s.xlarge instances at Amazon AWS, with Nvidia Tesla M60 GPUs. The Deep Learning AMI (Ubuntu) Version 23.1 image has lots of machine learning packages preinstalled, so it's super easy to use. Just launch an EC2 instance from the web dashboard, then clone my github repo:
git clone https://github.com/nickbild/gemini.git
Then start up a Python3 environment with PyTorch and...
Read more »

 Keith
Keith
 GOTO50ai
GOTO50ai
 Gonçalo Nespral
Gonçalo Nespral