 Michael Gardi
Michael GardiYesterday I finally got the UI, camera, and OCR pieces of TMD-2 all working together. Here is a short video where I "scan" the State Transition Table tiles with the Pi camera into the UI using Tesseract OCR to determine the symbol in each "cell".
This is running on my Raspberry Pi 4 but I am using RealVNC to capture this video.
One thing you will notice is that the process is not particularly fast. Sigh. I am using the pytesseract library to interface with the underlying OCR engine. I am calling the engine once for each cell because tesseract does not work well with tables. Under the covers, pytesseract "executes" the tesseract engine for each call, essentially using the command line interface. It works well but with significant overhead.
I had hoped to switch to the tesserocr which integrates directly with Tesseract's C++ API using Cython. With it you only invoke tesseract once and use the same instance for making all of your calls. Unfortunately I could not get this to work. Just loading the library in my environment cased a segmentation fault.
So what happened when I clicked on SCAN? First the Pi Camera took the following picture of my state table panel.
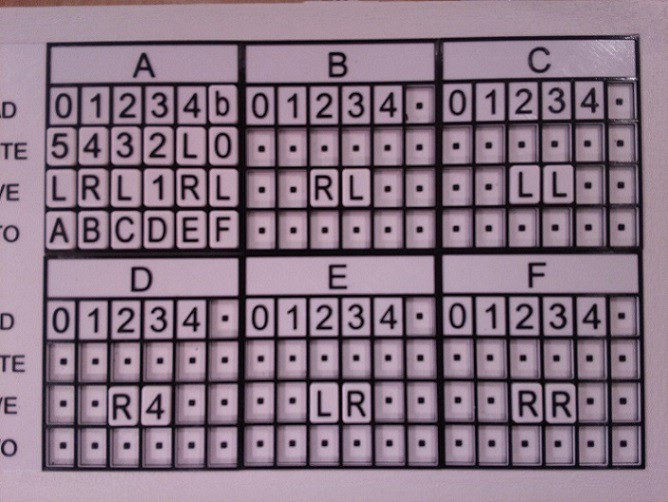
Note that this does not represent a Turing program, I just added some tiles to the panel for testing purposes. This image is used as the background for the Scan dialog so that the user can isolate the state table part with the "rubber band" rectangle. Now I could have figured out this bounding box for the table with some clever programming, and I have done this in the past, but the techniques were error prone enough that I ended up using the "rubber bands" as a backup anyway, so I though in this case I would just "cut to the chase" as it were.
When the user clicks START, the bounding box is used to create a "cropped" image that is passed to the OCR code.
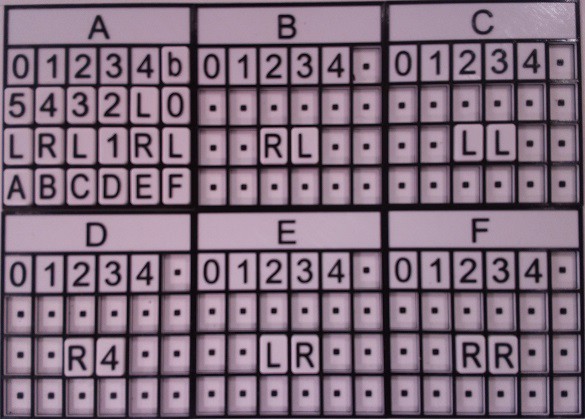
Notice that the bounding box doesn't have to be perfect, but the edges in the photo should not be too skewed for good OCR fidelity. The image processing pipeline that has been mentioned in previous logs has changed a little. I starts the same with a conversion from color to greyscale.

Then I do a contrast equalization step.
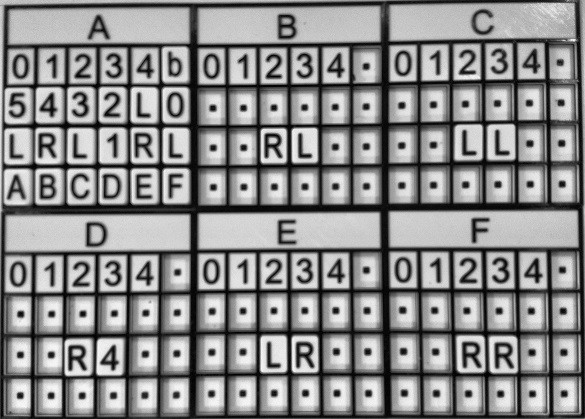
The equalized image is converted to binary. As has been mentioned, the table borders are removed by applying a single white color "flood fill" to them. I'm amazed at how well this works.

And finally a dilation is applied to the image to reduce noise.

At this point, in my previous trials, I would apply some edge detection and contouring to determine the bounding boxes for each of the tile symbols. Now however, because I know that the bounding box for the table has been well defined, I can just calculate the positions of each cell with reasonable accuracy. Without the borders, there is enough white space around the symbols to provide a good margin of error. So I just go ahead at this point and OCR the cells. As each cell is recognized, the value is passed back to the UI for display.
Once all of the cells have been recognized, the state table in the UI looks like this.
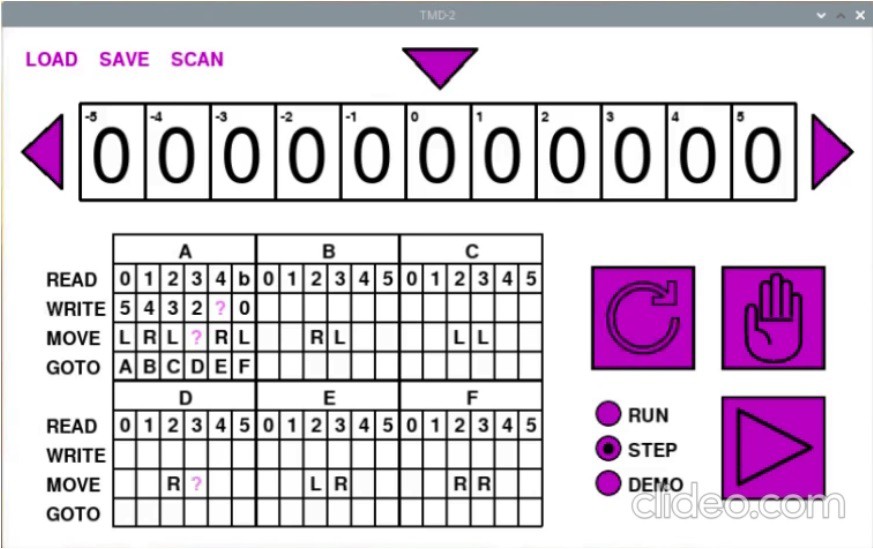
Notice that some of the cells have a purple ?. When loading the cell values, I do a reasonableness check on each. If a symbol does not belong in the cell based on the allowable row values, the ? is shown instead. This is what we see for the L in A-4-WRITE, the 1 in A-3-MOVE, and the 4 in D-3-MOVE. This can happen if the user places a tile in the wrong row, or if the OCR engine fails to identify the a symbol correctly. At this point the user can correct the errors in the UI, or fix the cells on the panel and rescan.
I have updated github with the new and modified files. Note that the Tmd2Console application will still run stand-alone without needing a camera or OCR.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.