The deep scrubs turned up a few more repairable inconsistencies until a few days ago when they grew concerning. It turned out that one of the OSDs had unexplained read errors. Smartctl showed that there were no read errors recorded by the disk, so I initially assumed it was just the result of a power failure. It became obvious that something was physically wrong with the disk when previously clean or repaired PGs were found to have new errors.
As a result I've marked the suspect OSD out of the cluster and I have ordered a replacement drive. The exact cause of the read errors is unknown, but since it is isolated to a single drive, and the other OSD on the same RPi is fine, it's most likely just a bad drive.
Ceph is currently rebuilding the data from the bad drive, and I'll post an update once the new drive arrives.
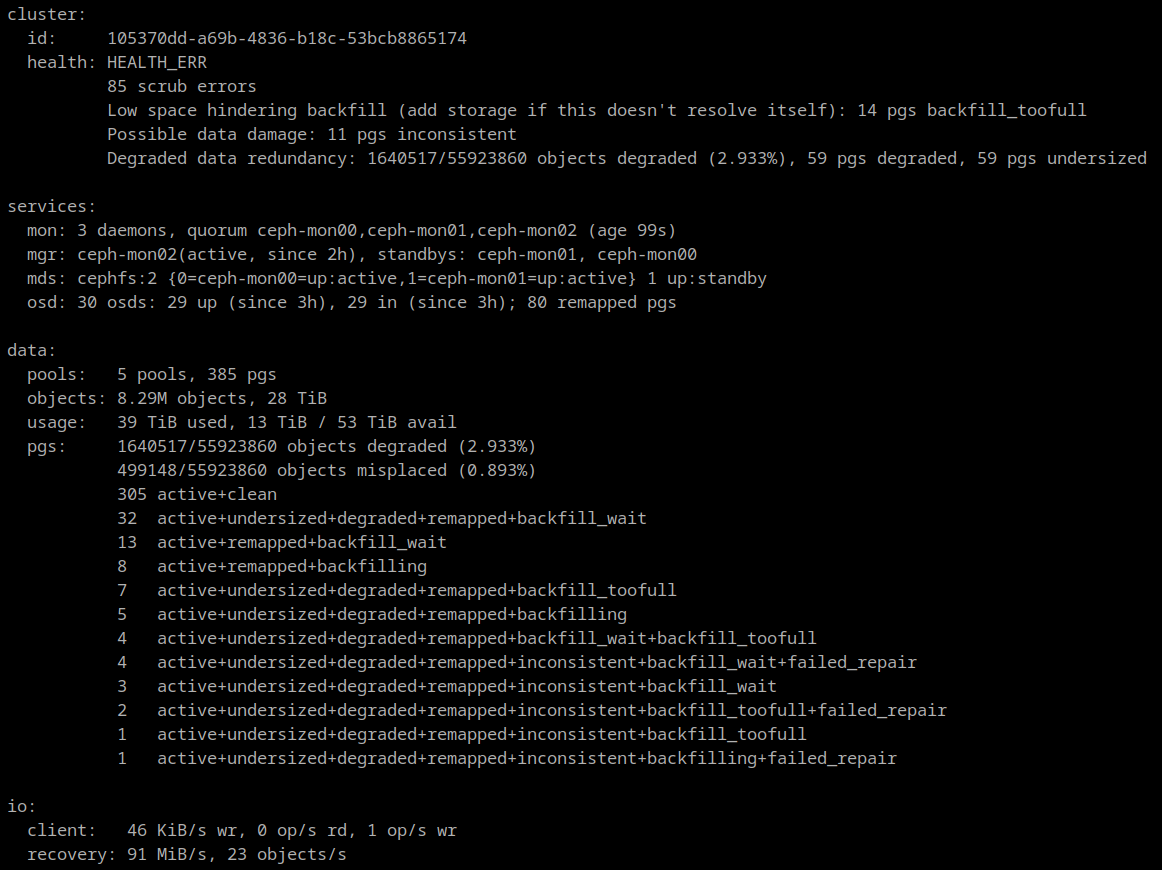
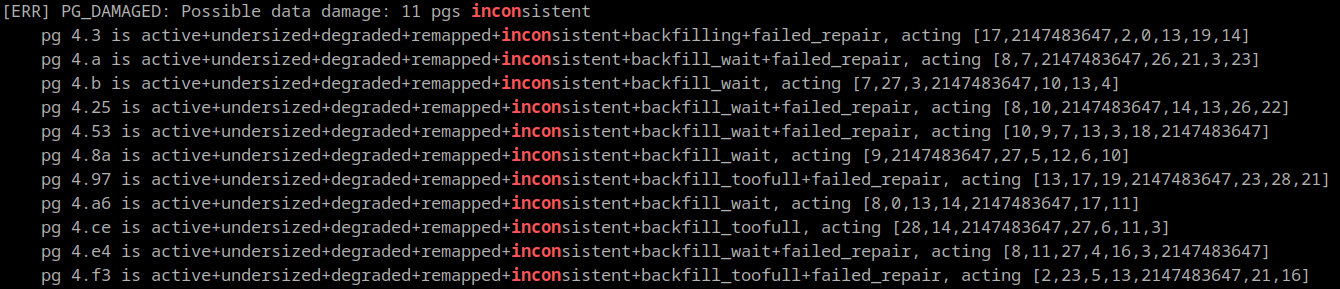 The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.