 Chris Combs
Chris Combs
One of the most fun parts of building Maelstrom has been getting ~35 machines to speak to each other. In a setting with solid infrastructure, perhaps I would use WiFi. Art galleries aren't always happy about this idea. I also wasn't thrilled about the machines possibly getting Internet access; in my perfect world, they would be completely isolated from wider networks.
I have worked with Nordic NRF24L01+ radios in other projects and decided to use them in Maelstrom. These radios accept 32 bytes of data and let you, as a developer, "press send and walk away" while they handle the mechanics of retransmission, error checking, etc.
They have other, interesting properties, like a five-byte "pipe" identification scheme that (in radio firmware) lets you ignore messages on the same channel that are not intended for a given client. And it's possible to set up a multicast network. I chose this approach for Maelstrom, using a common "message bus" with target device identifiers baked into the data payload. So all the radios are reading and writing from a common channel, at a rate of a message every few seconds (with some exceptions).
There are additional complexities with this, particularly when sourcing NRF24L01+ radios on a budget. Some of the modules sold today are using mostly-compatible clone parts. One, in particular, clones the datasheet very well--one signal described by Nordic in their own datasheet is flipped in practice in actual Nordic devices, and the clone devices cloned the datasheet instead of the real device behavior… making them incompatible in practice with real devices.
In my perfect world, I'd be able to keep each radio listening both on a group channel and on an individual address. I wasn't able to get this working across my mix of radio modules. I ended up using Pipe 1, as recommended by the RF24 documentation, to listen to just the multicast channel, and encoding an individual address into the message types that need it.
What data is shared over the radio?
I wanted to have visitor data literally being shared among the machines. A given datum is observed by one particular Maelstrom node and it shares it to two others. Each of them, if they successfully receive it, can choose to share it to two others, themselves. A given node's output generally shows the most recent datum it received. In this way, a given rumor (datum) can quickly spread among the Maelstrom network.
It exhibits an "echo chamber" effect in real time, with some facts growing in prominence and other facts being suppressed over time. After a few minutes all of the machines might be repeating the same thing back to each other.
It's very important to me that visitor data not be retained for longer than 15 minutes. So each internal radio transmission includes an expiration time, along with the data, the visitor ID (and color--it's a 6-digit hex code, as used in HTML/CSS). If a node receives a radio transmission with an implausible expiration date, it throws it out.
There are also some "housekeeping" transmissions sent among the nodes--to wit:
How do the nodes know which other two nodes to send their data towards?
This is the fun part. So, if all the machines always functioned perfectly, I could set this per machine in advance and call it a day. This would lead to a boring structure where a given machine always shared its data with the same two machines, and so on, but it would work fine. More like a rushing river than a truly chaotic environment.
The problem is that in the real world, these computers and radios don't function perfectly. Some radios in particular seem to drift out of frequency or something, causing them to stop "hearing" after many hours or days. I can reset them every so often, but I can easily imagine a scenario where a few particular nodes fail and the entire installation becomes unresponsive.
That would not be good! So, I built a system to dynamically build a directed graph of all responsive Maelstrom nodes and renegotiate it as needed as nodes appear or disappear.

It works something like this:
- Each node emits a "hello!" every five seconds or so.
- Each node keeps track of how many other nodes it can hear, and tracks this over time, computing a "signal strength."
- The "hello!" I mentioned also includes a mention of how many nodes it can hear well. So each node is really saying, "hello! and I can hear 5 nodes well."
- After powering up, each node waits to hear if a "leader" has been elected. It waits a staggered amount of time.
- If not, it calls an election, sending a special message to the multicast channel.
- Each node votes for whichever node it thinks is best, scoring by that node's signal strength. So it votes for whoever can hear the most nodes, essentially. (there is a special case of "over-listener" where a radio receives lots of garbled transmissions and thinks it hears hundreds of ghosts; I exclude this case a special way.)
- The votes are sent back to the multicast channel, and everybody listens.
- Each node decides for itself who won, sorting by node number in case of a tie.
- If a node decides that it won, it emits a "Leader!" declaration.
- If a second node thinks that it won and hears about a leadership dispute, it calls a second election; this nearly always resolves quickly due to other nodes' previous determinations.
- The leader node listens for as many other nodes as possible and computes a directed graph, using networkx.
- It attempts to connect each node to two downstream nodes and two upstream nodes. It makes a second pass and overloads some nodes to ensure a minimum 2 up/down for each node.
- Once a graph is computed, a graph version number is assigned. The graph is transmitted in a series of multicast messages.
- A given node listens only for itself and expects two nodes. If it doesn't receive them within a timeout window, it requests the graph shard for itself with a request sequence number.
- It retransmits this request as necessary, incrementing the request sequence number.
- If the request sequence number gets above a certain threshold, peer nodes assume that the leader node cannot hear the request.
- Peer nodes retransmit the request.
- If a node senses that its downstream nodes are not in range, it declares them a "bad peer" and emits a special message.
- The leader node listens to this, decimates the graph (by which I mean removes 10% of connections) and removes the connection between Peer X and Badpeer, and reweaves the missing connections to generate a new graph.
- If this approach fails it will rebuild the graph from scratch as needed.
The hard parts have been working around these failure cases:
- A node can transmit but not receive
- A node can receive but not transmit
- Node X can't hear Node Y
- Node X can't hear Leader Node but can hear other nodes
- Leader Node can't hear Node X but can hear other nodes
- A node is receiving lots of garbled messages
- A node is sending lots of garbled messages
One interesting aspect to all of this is that as someone trying to replicate rumormongering in device format, I don't necessary want perfect message transmission. I like when the machines are playing "Telephone," sharing a typo-ridden version of a fact instead of the real thing.
To help with this, I don't apply any extra CRC or error correction in my Maelstrom software. I do leave hardware CRC enabled at 16 bits, and throw away messages that are obviously badly structured--but if a given message turns "Christopher" into "Chrisjrote," to me, that's just part of the fun.
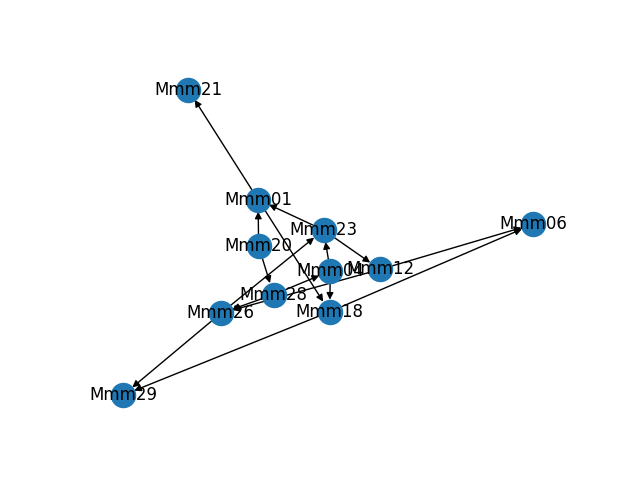
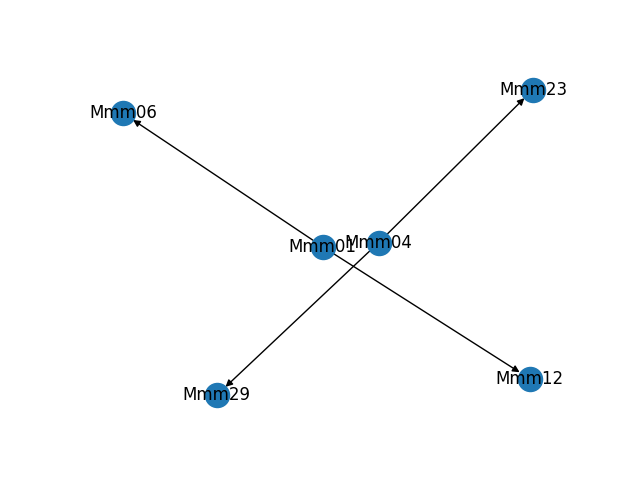
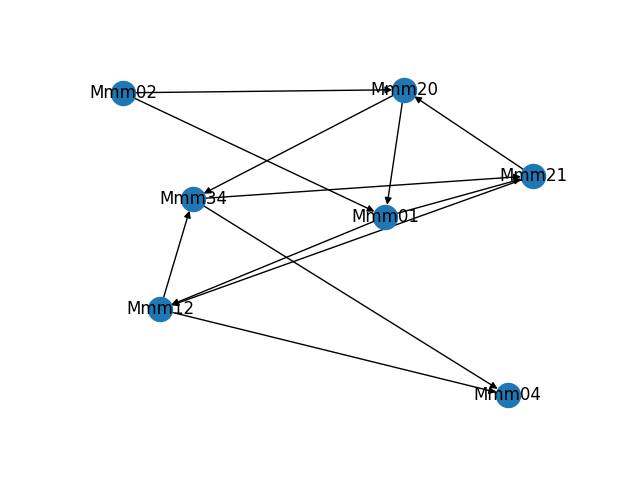
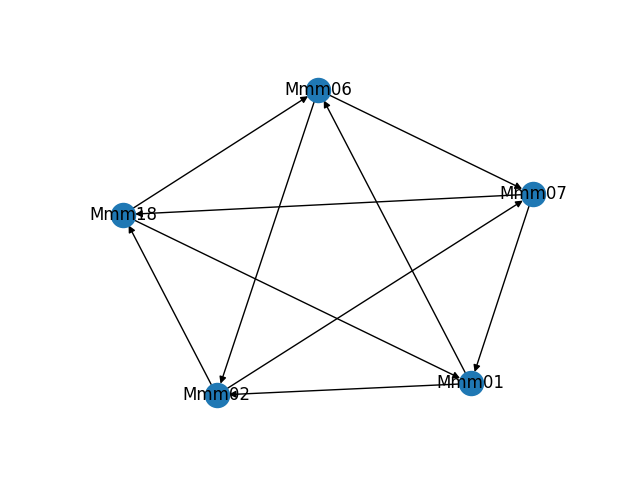
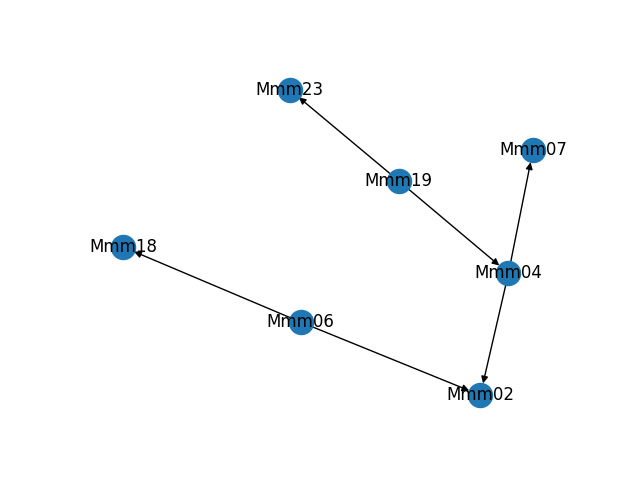
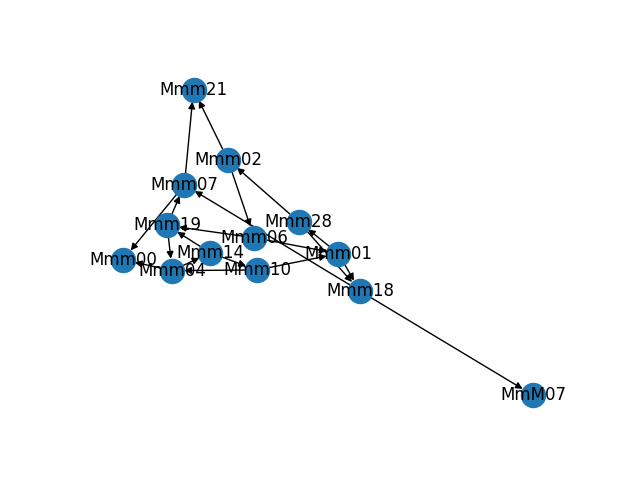
As part of building and troubleshooting all of this, I have an internal diagnostic tool that outputs the graph in visual form. Sometimes it makes fun shapes. As a bonus, here are some of the weirder graphs it's formed.
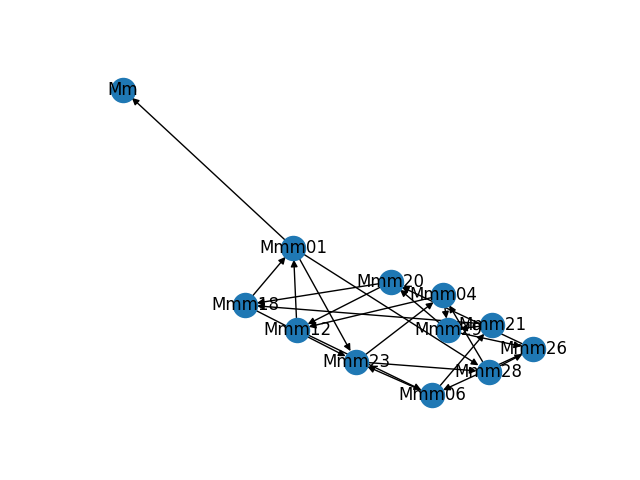
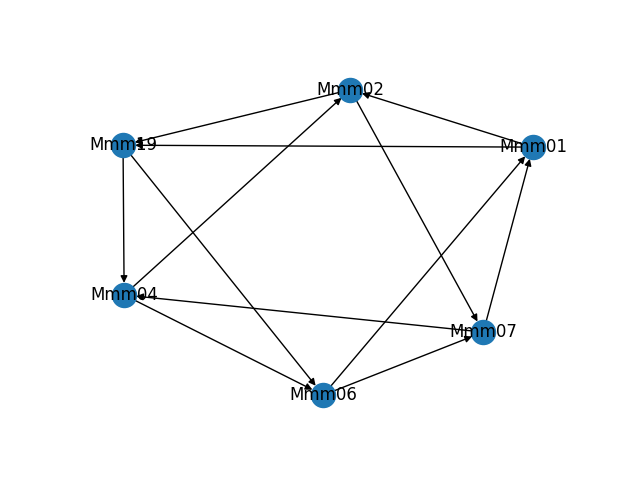

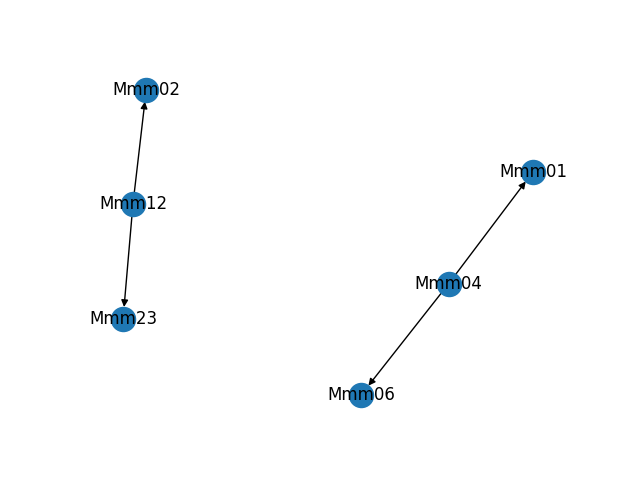
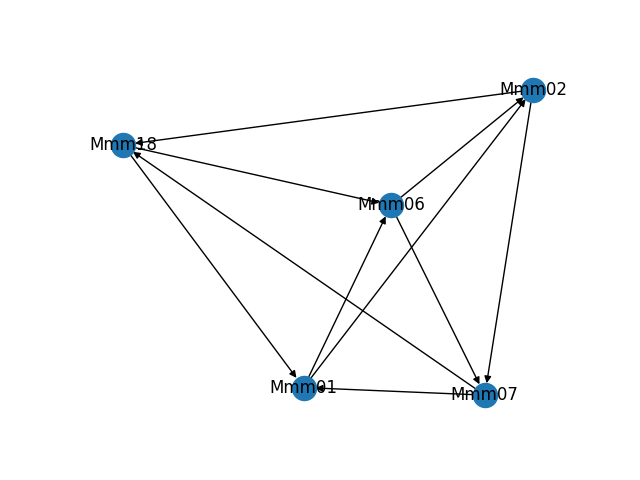
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.