 3drobert
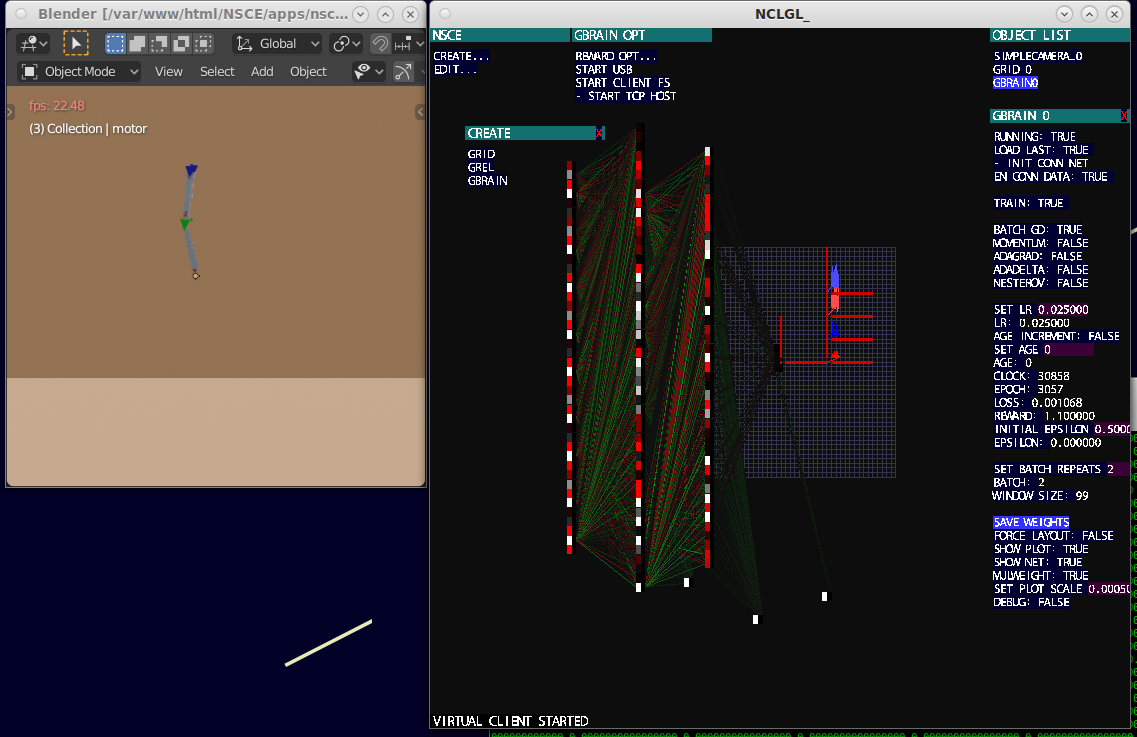
3drobertMany more enhancements, important corrections, oversights, refactorings... and realizing that another things I needed is a long training and seeing the reward plot specially.
By the moment it's looking good and seems that learn correctly instead of unlearning :D

Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.