 lion mclionhead
lion mclionheadAfter extracting just 1 category with truckcam/coco_to_yolo.py, there has to be a data.yaml file to point pytorch at the training data.
train: ../train_person
val: ../val_person
nc: 1
names: ['person']
the training step was done in /root/yolo/yolov5/
source YoloV5_VirEnv/bin/activate
python3 train.py --data data.yaml --cfg yolov5s.yaml --batch-size 8 --name Model
yolov5s.yaml is the model & they say it's the simplest. All the models are in the models directory. They're just text files which describe the neural networks.
This would take many years to finish without CUDA, so some effort is required to get CUDA working. It doesn't work by default. To debug it, we have to limit the size of the dataset by setting max_objects in coco_to_yolo.py
The 1st step is using the right version of CUDA. This one required 11.2
The 2nd step is reducing the amount of GPU memory required. The lion kingdom reduced the batch-size to 4 to get it under 2GB.
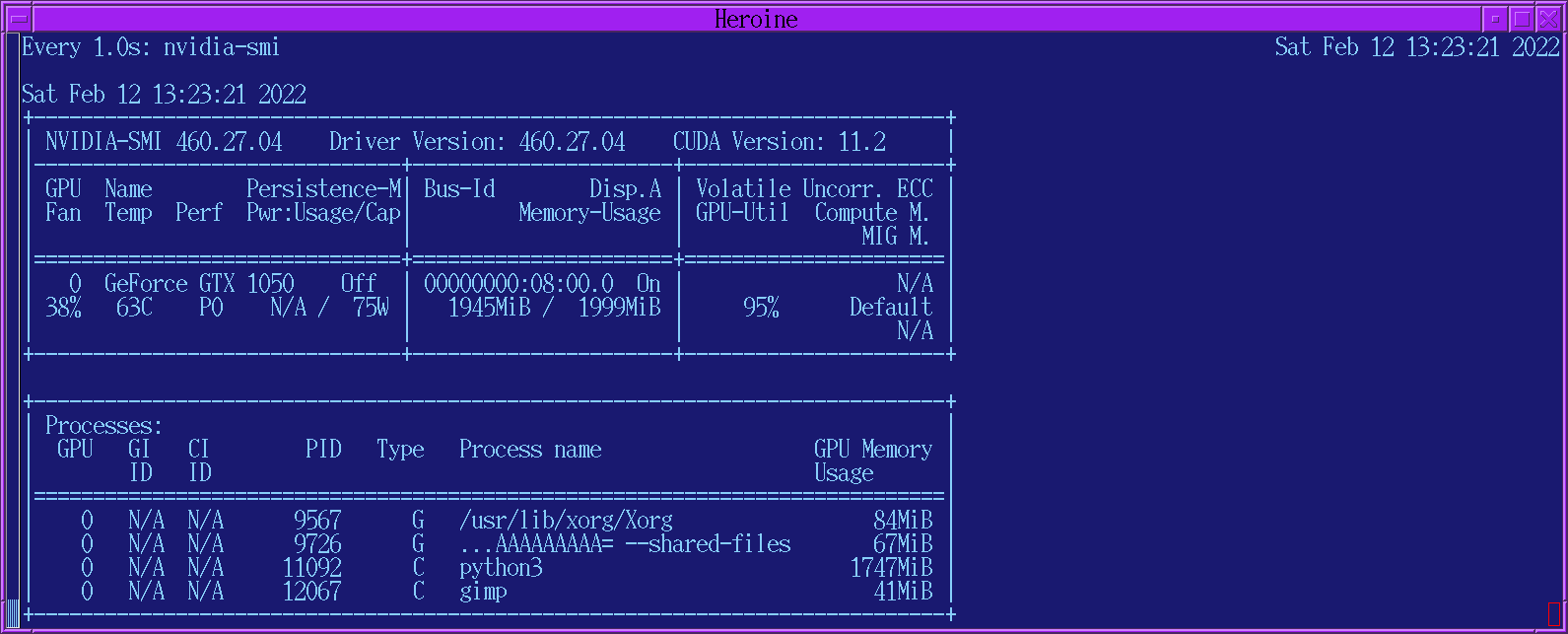
Not sure if it preallocates the memory. Watch a 4K video & it's all over.
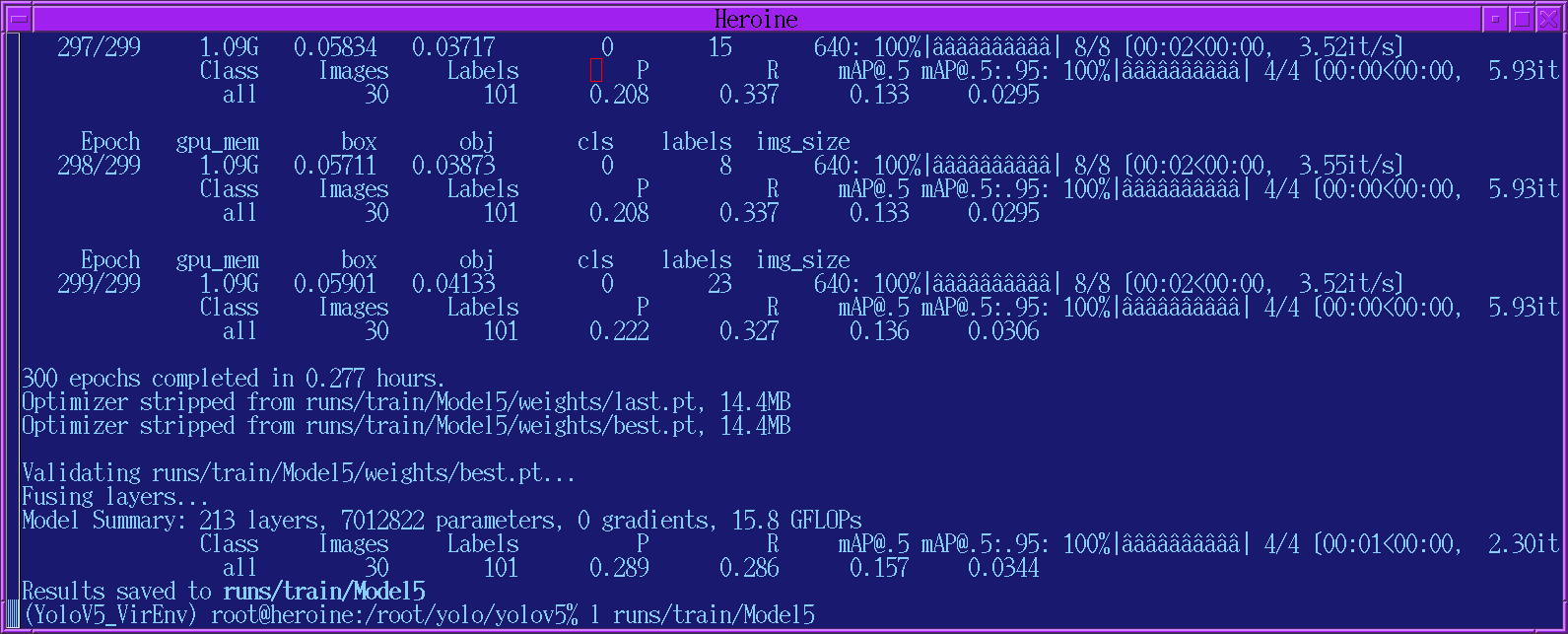
Even with 100 objects & what they term the very simplest model, it took 15 minutes. Then, it created some collages of validation tests on scenes from the 1990's. It's supposed to use the train* files for training & test against the val* files.

It's almost like the bounding boxes in the training set are offset in the top left.
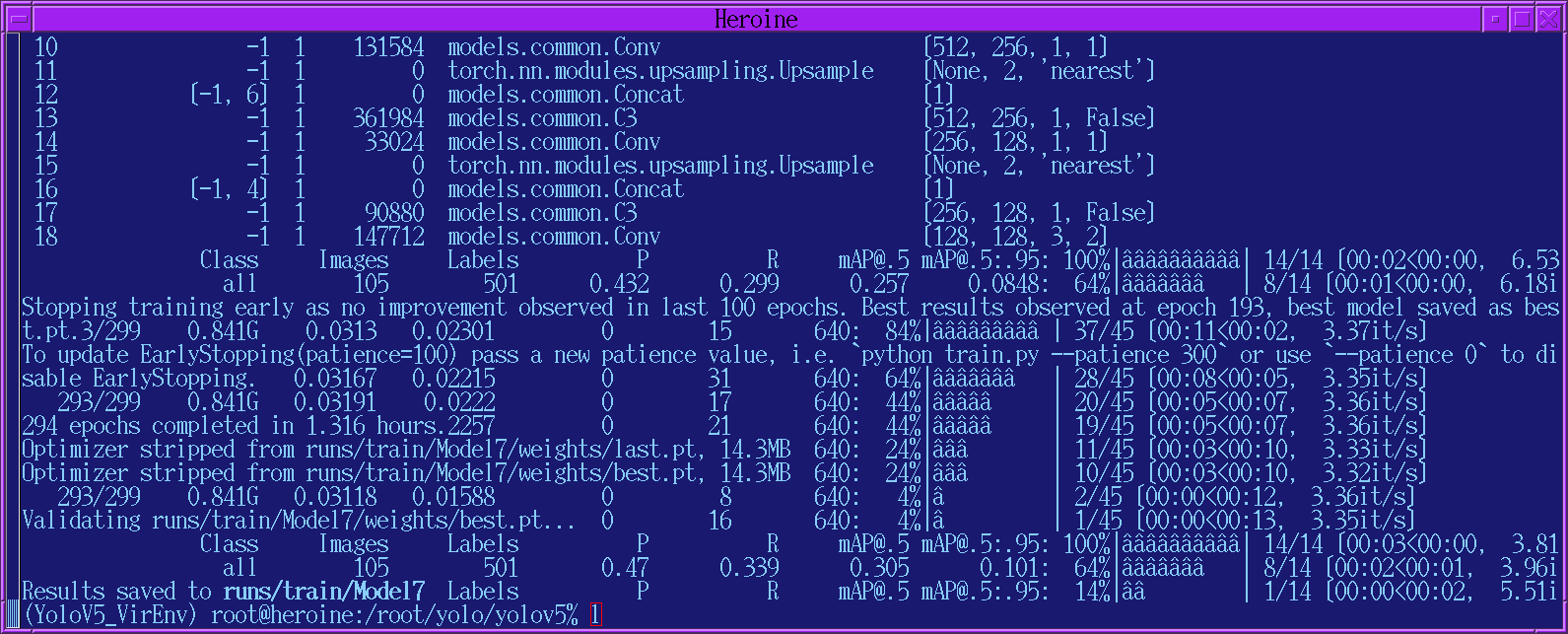
A 500 object run took 80 minutes on a GTX1050 with 2 Gig. It said it ran 293 epochs but saved the model from epoch 193. It basically detects the peak model & waits for 100 more epochs before quitting. The validation tests were just as bad.

In the train_batch files, the labels were all over the place.

2 discoveries were the .txt files need to contain the center x, center y, width, height in fractions of the image size & you have to delete all the .cache files in order to change the data set. There's no way to get that without downloading the complete 1G example data set for YOLOV5 & reviewing the validation output. The annotation formats are heavily protected bits of intellectual property.

Much better results from 100 objects. Not good enough for a pan/tilt tracker because it doesn't detect any body parts, but it might be good enough to replace face detection for panning only.

1000 objects took 2 hours to train on a GTX 970 with 3 Gig. It gave roughly the same results as 100 objects. Suspect spending several years on 1 million objects would do no good. YOLOv5 may be good enough to not need a lot of training or the model may not be big enough to store any more data.
A biologically derived model that detects just the humans instead of the mane subjects in the photos seems like a lonely animal, but it's what tracking cameras are for. Ben Heck would train it to detect just cats. The neural network can't reproduce so it's not alive.
The next step is converting the output into a format for https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi
The pytorch output goes into a best.pt file in /root/yolo/yolov5/runs/train/*/weights
There is a script for converting best.pt into tensorflow lite format: /root/yolo/yolov5/export.py
python3 export.py --weights runs/train/Model.../weights/best.pt --include tflite --img 640 --int8
Sadly, this didn't produce the metadata required by https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi. It's not obvious that YOLOv5s would ever be a drop in replacement for efficientdet_lite0 or that it would be as fast. Based on anecdotes, conversion from pytorch to tflite isn't officially supported & all the conversion scripts are diabolical hacks.
The next step is to try to use the efficientdet_lite0 model maker described in
This is based on a modern notebook style program https://github.com/freedomwebtech/tensorflow-lite-custom-object
It can do the training on a Goog cloud server with a better GPU, but it'll cost you. You can also cut & paste it into a local python script. The annotation files are in an XML format with only a video example given.
Another model maker program
https://www.tensorflow.org/lite/tutorials/model_maker_object_detection
uses a CSV file with the labels & image filenames, but provides no examples. Suspect the annotation formats are obfuscated to keep people from using goog's dataset with pytorch or the COCO dataset with tensorflow. Pytorch is funded by facebook while tensorflow is funded by the goog.
The tensorflow process is a lot more centralized than digging up a dataset from the COCO archives & running pytorch. There is a much larger database of images on the goog https://storage.googleapis.com/openimages/web/index.html
& the tools are provided to make a custom dataset. It doesn't seem possible to run a model maker on a goog cloud server, making it load its own dataset directly from openimages. The dataset has to be copied to a goog drive because it has to be reloaded for every epoch.
Surprisingly, most of the datasets already built are aimed at self driving cars while there are no datasets for just humans.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.