 Petoi
PetoiLearn how to use a voice control module for Raspberry Pi with Petoi Bittle — a palm-sized, open-source, programmable robot dog for STEM and fun. - by Friende Peng, intern engineer at Petoi in 2021 summer.
Things used in this project
Hardware components
-
OpenCat Bittle
- Raspberry Pi 3 Model A+
- Mini USB Microphone
- Petoi - USB Adaptor
Software apps and online services
OpenCat, an open source robotics quadruped framework
-
Raspberry Pi Raspbian
- Arduino IDE
Story
Introduction
Petoi's Bittle is a palm-sized, open-source, programmable robot dog for STEM and fun. Bittle can connect with Raspberry Pi and can be easily extended. The goal was to develop a real-time voice control module for Bittle and command Bittle to do some actions.
Demo Video
Voice Control Petoi with USB Adapter & MacBook Pro
Voice Control Petoi with Raspberry Pi Model 3 A+
Abstraction
The conclusion is that I use VAD(Voice Activity Detection) + DTW + Vosk
Use Python to record
I used PyAudio at the beginning, but it is an old library. So I used Sounddevice and Soundfile instead.
Command/Key Words Recognition
From a functional point of view, the methods to do this can be divided into:
- Speech to Text. And then look up the commands in the text. One good thing is that this can be combined with NLP applications but this is an overkill for Speech2Text.
- Use acoustic features to do analysis and detect commands.
DTW (Dynamic Time Warping) (Used)
This belongs to the second category and it's similar to template matching. DTW can calculate the cost to match one piece of audio with template audio. We can pick the audio with the lowest cost. This method does not need training and is also applicable even if you want to add new commands. The bad thing is that the calculation is time-consuming. But at least the command audios are short in time and we can find ways to eliminate the silence and extract MFCC(Mel-frequency Cepstral Coefficients) feature.
CNN for Command/Key Word Recognition
This is a demo Speech Command Recognition with torchaudio — PyTorch Tutorials which is done by PyTorch Official. But we need to re-train the model when we have new commands coming in.
Voice Activity Detection
I was inspired by a blog Audio Handling Basics: Process Audio Files In Command-Line or Python | Hacker Noon. The blog mentions that we can eliminate the silence part of an audio recording according to the short-term energy of audio data. A Python library called librosa provides some functions for doing that.
Speech Recognition
I tried some open source methods:
Offline recognition, provides lightweight tflite models for low-resource devices.
Requires 16bit 16KHz mono channel audio. A new version supports Chinese.
I tested it by using non-strip and stripped audios with both large and small size models but it did not do well. For example:
- 起立 -> 嘶力/成立
- 向前跑 -> 睡前跑
- 向前走 -> 当前走
So I tested it again using English:
- Hey Bittle
- Stand up
- Walk forward
- Run forward
I have used 16 recordings for now. An empty result is shown when it encounters OOV(out of vocabulary) words. "Bittle" would be recognized as "be to". After silence elimination, some results have changed from wrong to correct, and some have changed from correct to the wrong (this may be due to the reduction of the silence between the pronunciation of words).
16 English Tests, 9 were correct &16 Chinese Tests, 3 were correct.
It does not have lightweight models and the models are near 900MB. It's too big for a Raspberry Pi.
It provides multiple ways such as using Google/MS Api. The only one method to offline recognition is no longer being maintained.
Vosk provides offline recognition and light-weighted models for both Chinese and Chinese. The documentation is not complete.
A test result for the Chinese model
Non-strip Correct----------|----------Stripped Correct----------|----------Total correct 16/21----------------------------|-----------16/21--------------------------|-----------32/42
Prepare environment
Simple Version (Run on Pi):
bash rpi_simple.sh
Complete Manual
1. Enter Pi's terminal:
sudo apt-get update && sudo apt-get upgrade
2. Install portaudio:
sudo apt-get install make build-essential libportaudio0 libportaudio2 libportaudiocpp0 portaudio19-dev libatlas-base-dev
3. Create a new virtual environment with python==3.7.3 and activate it.
- If you use venv:
spython3 -m venv /path/to/environment
4. Install Scipy. Download the wheel file
spython3 -m venv /path/to/environment
Make sure you download the one with cp37-cp37m-linux_armv7l in its name.
5. Install librosa:
- Deactivate the environment and then:
sudo apt install libblas-dev llvm llvm-dev export LLVM_CONFIG=/usr/bin/llvm-config
- Activate the environment and then: Note: The correct version number of llvmlite can be found at pypi. You should determine according to the llvm version installed by the first command above. Same for numba's version.
pip install llvmlite==[correct version number]
pip install numba==[correct version number]
- Download and unzip librosa source code. Then cd into the directory.
python setup.py build
python setup.py install
Example for version number: llvm==7.0.1 corresponds to llvmlite==0.32.1 and numba==0.49.1.
6. Install the remaining dependencies.
pip install -r requirements_pi.txt
7. Download vosk model. Download vosk-model-small-en-us and vosk-model-small-cn. The former is for English(US) and another one is for Chinese. Both of them are small and portable models.
8. Current codes use English Model for default, download and extract the model. Move the folder you just got into ./models. Make sure the folder name is the same as vosk_model_path in your config.
Run
1. IMPORTANT: Let terminal enter my_vosk and input:
python main.py
2. You can skip the recording step. A pre-recorded file is saved at ./recordings/template_1.wav A file with raw in its name means the wave file has not been stripped(silence) yet.
3. Finetune the threshold for wakeup recognition. In config.yml, the value is now 0 for easy debug. After "开始监听(start listening)", check the console for DTW.normalizedDistance. For example:
- Before you say the "wakeup word", the value is between 115-125;
- After you say the "wakeup word", the value should decrease. Maybe between 105-117.For this case, you can set threshold as 120(strict) or 115(not so strict).
4. You should go into command recognition after waking up Petoi. There are many pre-defined commands in cmd_lookup.py. You can say "stand up", for example.
5. If you want to use Chinese model(similar for other languages):
- Unzip the Chinese model and put the folder into ./models Set the vosk_model_path in config.yml.
- Set the cmd_table in config.yml as below:
cmd_table:
package: my_vosk.common.cmd_lookup
table_name: cmd_table_cn
build_dict: build_dict_cn
Logic
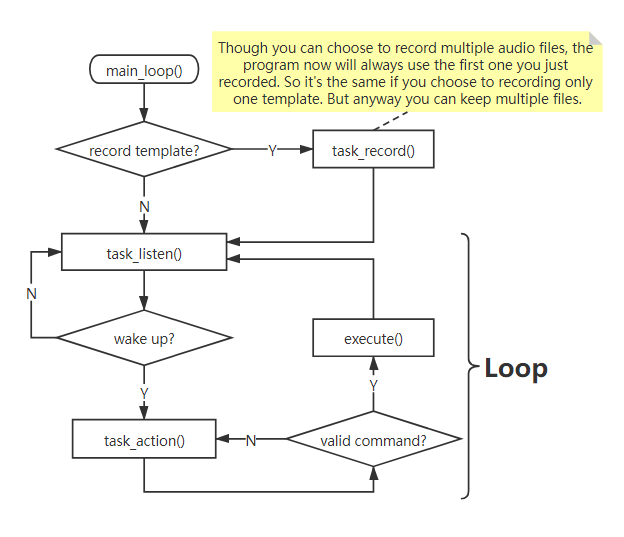
Code
Github Repository
This is a voice control module for Raspberry Pi with Petoi Bittle.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.