 glgorman
glgormanFurther integration of my 25-year-old C++ port of the '70s vintage Eliza program into the Pascal compiler is moving along nicely. The original code had an important step, referred to as conjugation - wherein words like myself and yourself, or you and I would be swapped. Yet, after realizing there are similarities to this process, and what goes on in the C/C++ preprocessor, I decided to rename the function pre_process, for obvious reasons - since that is one of the directions that I want this project to be headed. So even though I have no desire to learn APL, there is still some appeal to the notion that perhaps an even better ELIZA can be done in just one line of something that conveys the same concepts as APL, as if there is any concept to APL at all.
void ELIZA::pre_process (const subst *defines)
{
int word;
bool endofline = false;
char *wordIn, *wordOut, *str;
node<char*> *marker;
process.rewind();
while (endofline==false)
{
word = 0;
marker = process.m_nPos;
process.get (str);
endofline = process.m_bEnd;
for (word=0;;word++) {
wordIn = (defines[word]).wordin;
wordOut = (defines[word]).wordout;
if (wordIn==NULL)
break;
if (compare (wordIn,str)==0) {
marker->m_pData = wordOut;
break; }
}
}
}
Thus, with further debugging, I can see how a function like this should most likely be moved into the FrameLisp::text_object class library, since in addition to being generally useful for other purposes, it also helps to try to eliminate as many references to objects of char* type in the main body of the program as possible, with an eye toward having an eventual UNICODE version that can do other languages, emojis etc. Which certainly should be doable, but it can turn into a debugging nightmare if it turns out to be necessary to hunt down thousands of char and char* objects. Thus, I have created my own node<char*>, node_list<char*> and text_object classes using templates, for future extensions and modifications.
Thus, even though ELIZA is kind of broken right now, and is being debugged, this pretty much embodies the simplicity of the algorithm:
text_object ELIZA::response ()
{
int sentenceNum;
text_object result, tail;
char *str = NULL;
node<char*> *keyword, *tail_word, *last_word;
process = textIn;
pre_process (conjugates);
return process;
keyword = find_keyword ();
sentenceNum = currentReply [key];
currentReply [key]++;
if (currentReply[key]>lastReply[key])
currentReply[key] = firstReply [key];
result = replies [sentenceNum];
node<char*> *marker = process.m_nPos;
if (keyword!=NULL)
tail.m_nList.m_nBegin = marker;
else
tail = "?";
tail_word = result.findPenultimate (str);
result.get (str);
result.peek (str);
if (strcmp(str,"*")==0) {
last_word = tail_word->m_pNext;
delete last_word;
tail_word->m_pNext = NULL;
result.m_nList.m_nEnd = tail_word;
result.append (tail);
result.append ("?");
}
result.m_nPos = result.begin();
return result;
}
Yep, maybe the ELIZA algorithm, with the right text processing libraries just might only take about 40 lines or so of code, with no APL needed or desired. Now testing just the pre-processing part yields some interesting results. Making me wonder if at least for that part of English grammar analysis, that part of natural language processing is completely solvable.
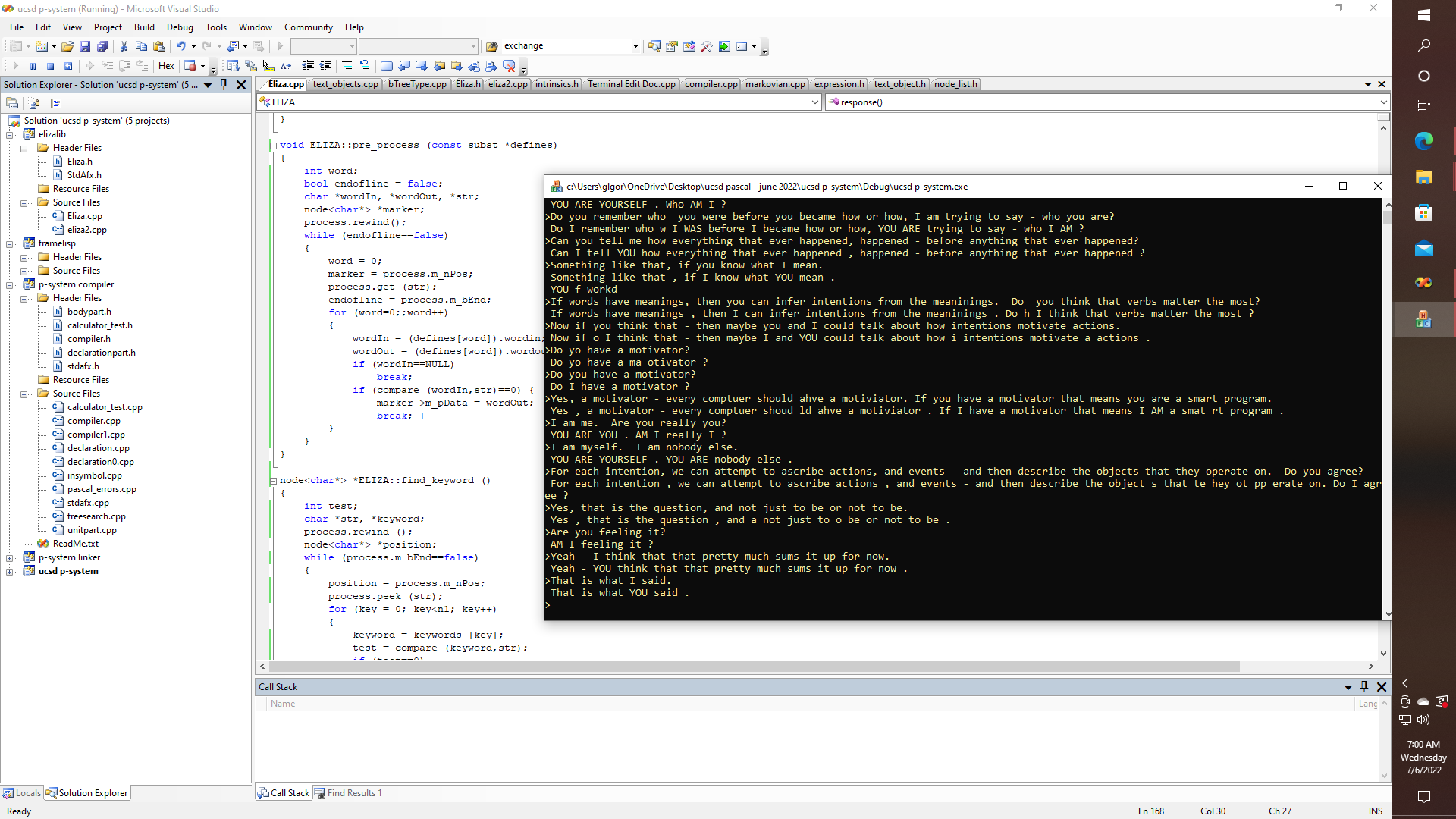
Interesting stuff. Plenty of stuff to do as of yet. Yet converting Pascal to C, or C to LISP, or LISP to FORTH might turn out to be much easier than it sounds at first blush - even if I meant to say - converting Pascal to C, and C to LISP, and LISP to FORTH, and so on.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.