 glgorman
glgormanWell, sort of - this is going to be a LONG journey - but things are starting to move very quickly as of late. Writing code is like that - months go by and NOTHING gets done - then in a couple of weekends I write a few thousand lines of code. This should be fun after all.
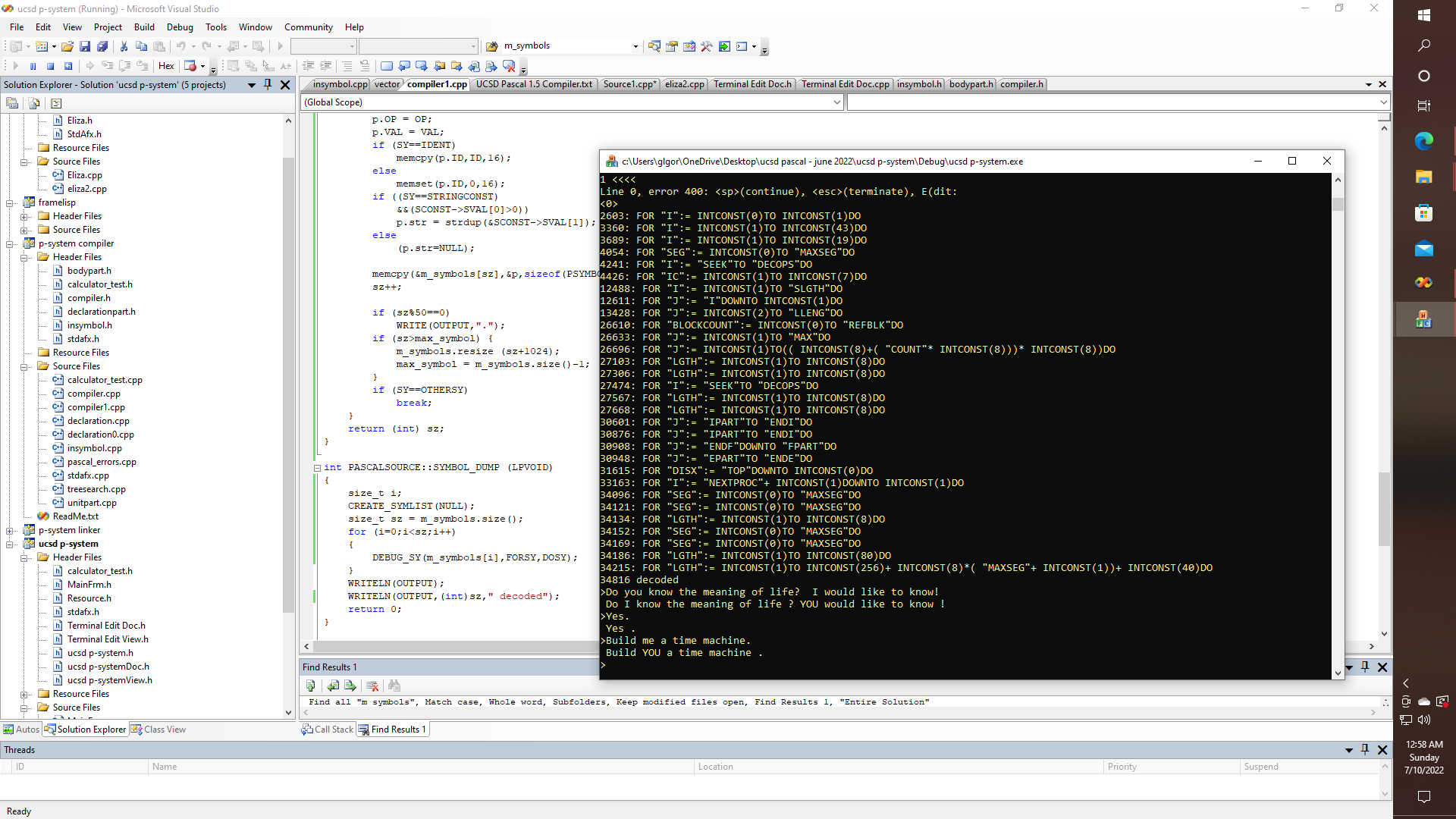
As if figuring out how to write a completely independent lexer, that works as good as, or better than the original wasn't enough work to do - then there is the notion of how to create ASTs (abstract syntax trees) that not only work with PASCAL, with C/C++, and yet also with standard English grammar, which might contain dialog, or it might contain commands like "KILL ALL TROLLS!", or "Build me a time machine". Oh, what fun.
int PASCALSOURCE::SYMBOL_DUMP (LPVOID)
{
size_t i;
CREATE_SYMLIST(NULL);
size_t sz = m_symbols.size();
for (i=0;i<sz;i++)
{
DEBUG_SY(m_symbols[i],FORSY,DOSY);
}
WRITELN(OUTPUT);
WRITELN(OUTPUT,(int)sz," decoded");
return 0;
}
Yet isn't it nice to contemplate being able to search a project for every FOR statement or every IF-THEN, or to make a list of all of the procedures in the source, to be better able to make sure the conversion is going correctly? Yet why not search "The Adventures of Tom Sawyer" for every reference to whitewash preceded by or followed by fence, or paragraphs that contain the name Injun Joe, and cave or caves in either same, the preceding or the following sentence, paragraph, or context? Seems like a daunting task, but is it? Maybe, or maybe not.
So, let's throw another log on the fire, and do it not with string manipulating functions like strcmp, strcpy, etc., but with abstract functions that can operate on, and transform text objects, whether they are in the form of pure ASCII strings, or tables, or linked lists, or vectors connection maps that link tree structures where the individual nodes of the subtrees point to linked lists or vectors of tokenized, and possibly compressed input which might in turn reference tables of dictionary pointers.
Writing, or re-writing a compiler is quite a chore. Having some interesting code analysis tools makes things a LOT more interesting.
Now, back to killing trolls, and inventing time travel?
Not, quite yet. Let's suppose that we are analyzing real DNA, then one way of doing THAT involves lab techniques that involve things like restriction enzymes, centrifuges, HPLC, CRISPR, DNA chip technology, etc. All so that we can later look at a genome, among other things, and have some way of doing something like "Find sequences that have CATTAGGTCTGA followed by ATCTACATCTAC or something like that, with whatever else might be in the middle. Like if we had a partial analysis of some fragments of a real protein that we want to learn more about, and we need to find out where in some three billion base pairs that might be encoded, even if that is also in fragments, which might be subjected to later post-translation editing.
Something like this looks VERY doable.
DEBUG_GENE ( genome, "CATTAGGTCTGA" , "ATCTACATCTAC" );
Just in case that sort of thing might be useful to someone.
Suffice to mention, also, that if you have been programming long enough, then you know what it is like to sprinkle your code with 1000's of TRACE statements, or trying to pipe debugging information to a logfile with fprintf statements, and all of the hassle that goes into creating the format strings, setting up and cleaning up buffers for all of that, and so on. When PASCAL does it so nicely - like this --
WRITE (OUTPUT,' ',SYMBOL_NAMES2[p.SY]);
WRITE (OUTPUT,'(',p.VAL.IVAL,')');
Letting us use the PASCAL-style WRITE and WRITELN functions, which are perfectly happy to accept strings, characters, integers, floats, etc., and without needing all of the Sanskrit.
This brings me back to LISP since it is so easy to imagine something like this:
for_statemtns = CONS(MAPCAR(DEBUG_SY(m_symbols,FORSY,DOSY)));
That is to say, instead of simply writing out the debugging information, we could re-capture the snippets from the token stream and then construct the new meta-objects in such a fashion, to make them more suitable for additional processing, as if wanted to re-parameterize the FOR statements from a Pascal program, to be able to convert them to C/C++ style for statements, just not with a statement converter that is written explicitly to convert for statements. but which works more like regex in PERL, where if we could find snippets that need conversion, then we could more easily offer regex snippets that are appropriately sanitized (where was I reading out that?), on the one hand, yet while remaining perfectly capable of working with other data types, like actual DNA sequences, that is to say - without loss of generality.
Thus, when contemplating how digital DNA might work, in the context of so-called deep learning neural network models, it should now become more clear how the interaction between traditional programming and deep learning might result in several orders of magnitude improvement in the computational effectiveness, that is so as to address not just the inefficiency of contemporary efforts at A.I.
Now for whatever it's worth, let's take a look at how well ELIZA does, at least at first blush at converting the definition of the pascal RECORD type contained in the original compiler source code to C or C++. Obviously, this is neither C or C++, nor is it Pascal, but it does look interesting. Obviously, some kind of TYPEGLOB_REORDER(A,B,C,...) might come in use here if we wanted to figure out how to convert this nightmare, entirely within the framework of the C/C++ preprocessor, i.e., with nothing more than #defines and the other stuff that the pre-processor allows. Yet, I don't think that that is necessary, and I am not trying to turn the preprocessor into a standalone compiler, translator, bot engine, or whatever. Suffice to say that it is sufficient for me to know if someone else could get Conway's game of life to run in one line of APL and if yet someone else could get a Turing complete deterministic finite automata to run within Conway, and if Tetris will run in the C++ preprocessor using ANSI graphic character codes, etc., then it pretty much follows that someone could probably shoe-horn Conway into the pre-processor, and then write a program that runs under Conway, that accepts a collection of statements according to some grammar, which we might call "A", and transmogrifies it according to some set of rules, such as might be referenced according to some set ["Q","R","S"...], and so on, so as to transform "A"->"B". Yeah, Yeah, Yeah, Yeah. Or so the theory goes, insofar as context-free grammars go.
struct STRUCTURE
{
ADDRRANGE SIZE;
FORM STRUCTFORM;
union
{
SCALAR : ( union ( SCALKIND : DECLKIND )
DECLARED : ( FCONST : CTP ));
SUBRANGE : ( RANGETYPE : STP ;
MIN , MAX : VALU );
POINTER : ( ELTYPE : STP );
POWER : ( ELSET : STP );
ARRAYS : ( AELTYPE , INXTYPE : STP ;
union ( AISPACKD : bool )
TRUE : ( ELSPERWD , ELWIDTH : BITRANGE ;
union ( AISSTRNG : bool )
TRUE :( MAXLENG : 1 .. STRGLGTH )));
RECORDS : ( FSTFLD : CTP ;
RECVAR : STP );
FILES : ( FILTYPE : STP );
TAGFLD : ( TAGFIELDP : CTP ;
FSTVAR : STP );
VARIANT : ( NXTVAR , SUBVAR : STP ;
VARVAL : VALU;
)
};
Actually, now that I think about it, I don't think that I particularly like context-free grammars. Contextuality is actually good! We need contextuality. Yet, as was discussed earlier, one way to try to trick the pre-processor into capturing parameters to function and procedure declarations might be to sometimes redefine the semicolon at the end of a line or statement, temporarily as in "#define ; ));" so as to in effect add a closing parenthesis to other substitutions, like "#define UNTIL } while (|(" which does some of the work for converting REPEAT... UNTIL blocks, but it needs help with captures and closures. Yet with code, and not a lot of code, we can do this:
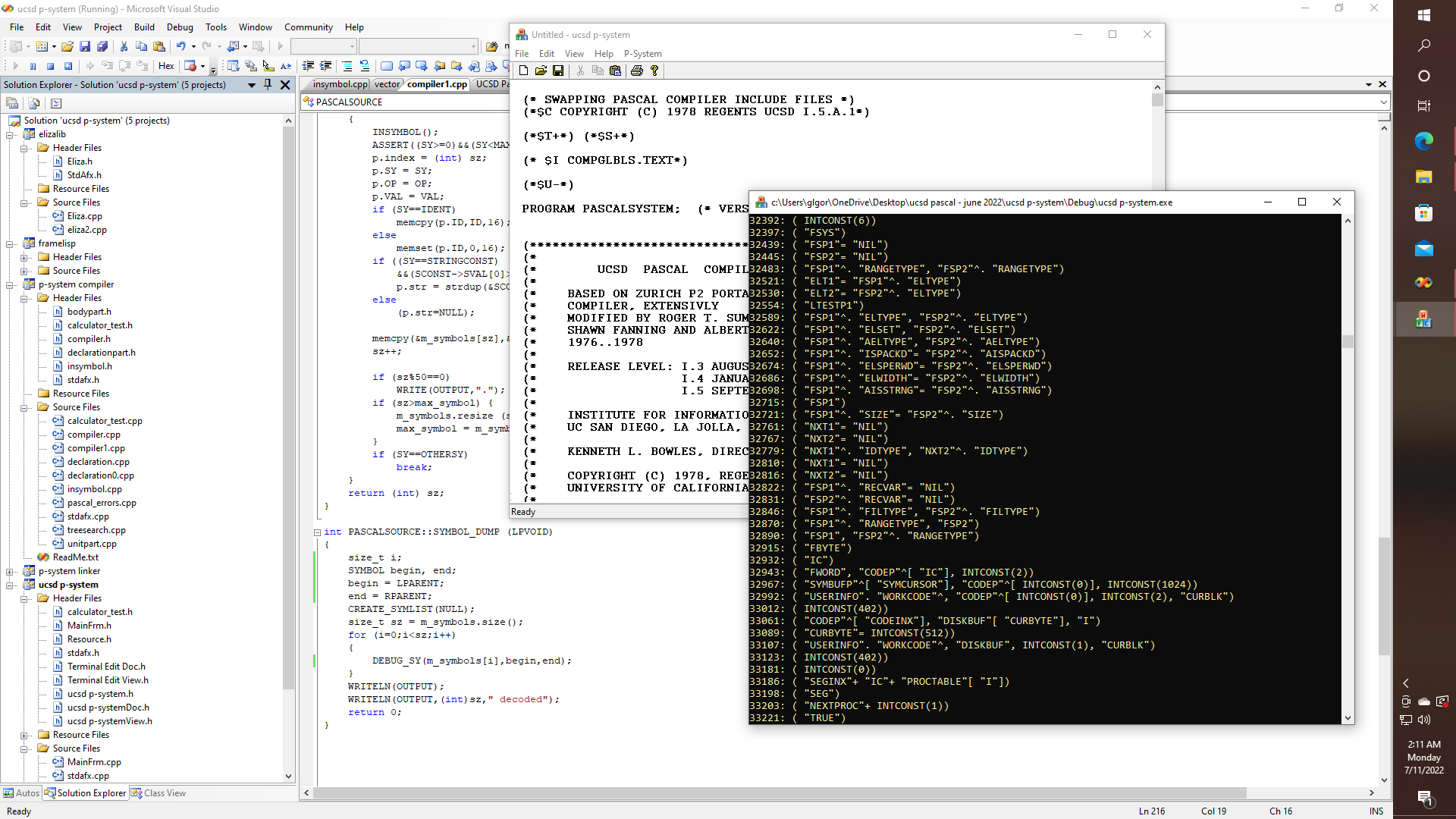
Now we are running our DEBUB_SY function with variables, instead of const parameters. - and we have specified that we are interested in capturing globs or whatever might be found in between sets of parentheses. With LOTS of work yet to be done. Yet here we have a potentially very interesting, and yet very simple solution to the problem of providing principles of capture and contextuality within the same method, even while providing a method that should work, or be easily extensible to work in even more general cases.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.