 EK
EKIn order to detect the urchins, object detection will be used. The model will be running on a Raspberry Pi with a Pi cam. Information about this will be sent back to the microcontroller (ESP32-WROOM) via UART. 3W RGB LEDs will be beside the camera to illuminate the surroundings underwater. All of these electronics are housed inside of the hull, which sits on top of the device’s chassis.
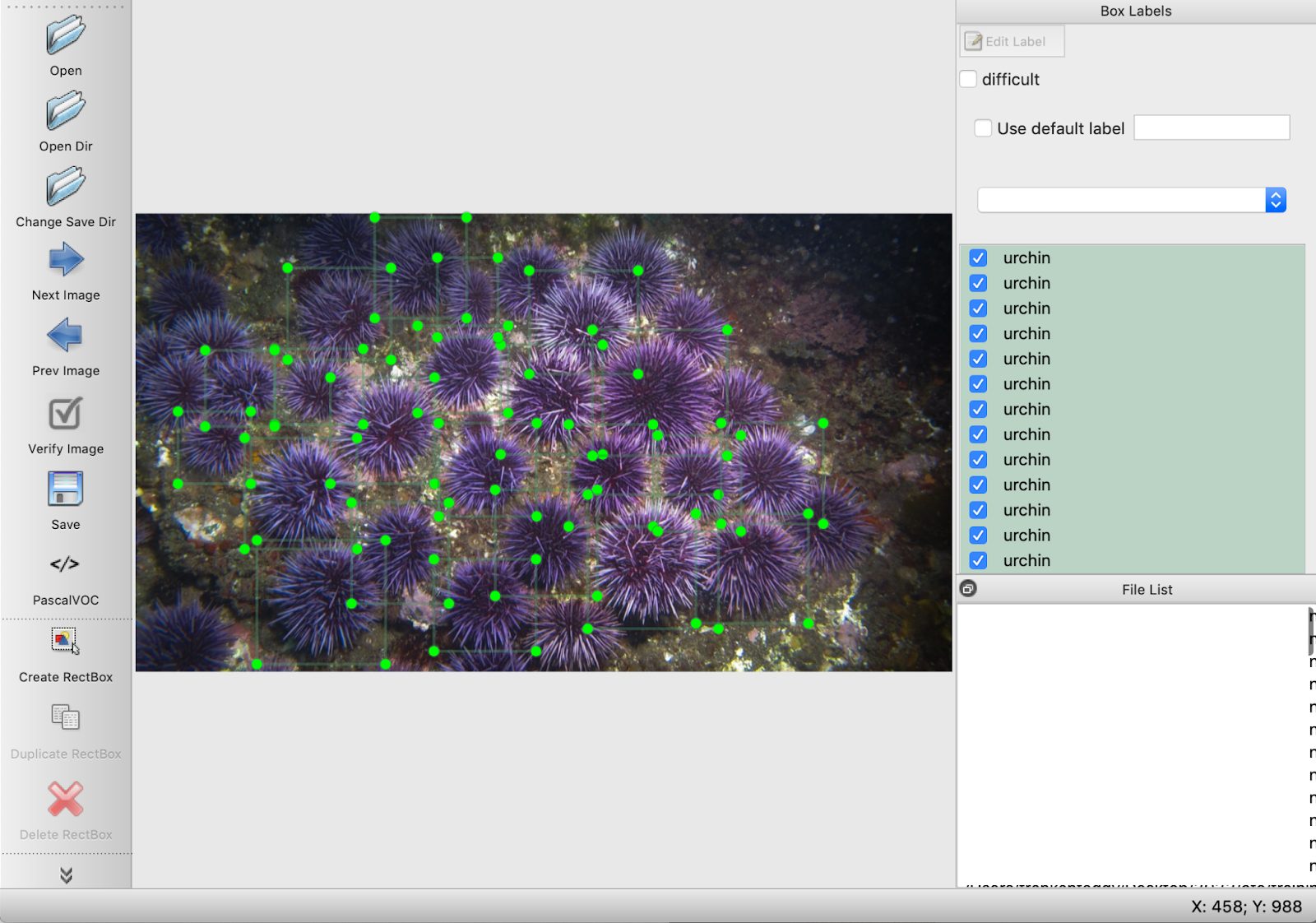
Object detection allows for counting multiple urchins in a single image, giving the position and dimensions. This count of urchins would eventually be used to help audit and track where there are less than 2 urchins per square meter, indicating it is a prime location for kelp forest restoration efforts.
To accomplish this, the task is divided into multiple parts:
- Dataset collection and tagging
- Training and testing
- Running on the device
- Analysing results in the real world setting
This log covers step #1 and the start of step #2.
A list of objects of interest was created:
- Purple sea urchin
- Fish
- Kelp holdfast
- Kelp stipe
- Kelp blade
- Kelp float
- Ground
These are the elements in kelp:
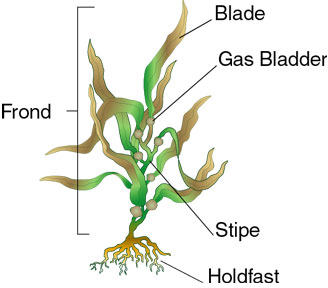
To test the concept, urchin would be the first object that is trained. In the future, as more data is collected on the device, the additional list items can be trained.
For the first round of training images need to be collected. The images were collected manually from searching the internet. Although a scraper could be used, it could have negative consequences such as being blocked, which I did not want to risk.
The process was as follows:
- Search purple sea urchins on Google Images
- Follow the results that were interesting
- Save the images into /train or /validate or /test
- Remove duplicates with same file name
- Convert .webp to .jpg
- Run a program to detect visually similar images
- Change width to be 1200 px maximum for /train and /validate
- Change filenames to be image-NNN.jpg
- Annotate with LabelImg
To detect the visually similar images and remove duplicates, Duplicate File Finder (https://nektony.com/duplicate-finder-free) and PixCompare (https://www.lakehorn.com/products/pixcompare/) were used.
If the width or height exceeded 1200 px, this was resized to 1200 px using an AppleScript with Automator (https://discussions.apple.com/thread/253308106). There could be other ways of doing this, such as with Python.
Check if any files are named .jpeg and change them. See the files with this command:
ls -d *.jpeg
Renaming the files to be sequential was also completed using Automator. Another way of doing so would be with a bash script.
LabelImg was installed and run to label all the images. Commands:
sudo pip3 install labelimg
labelimg
By annotating urchins in many different settings and angles, it will help the model.
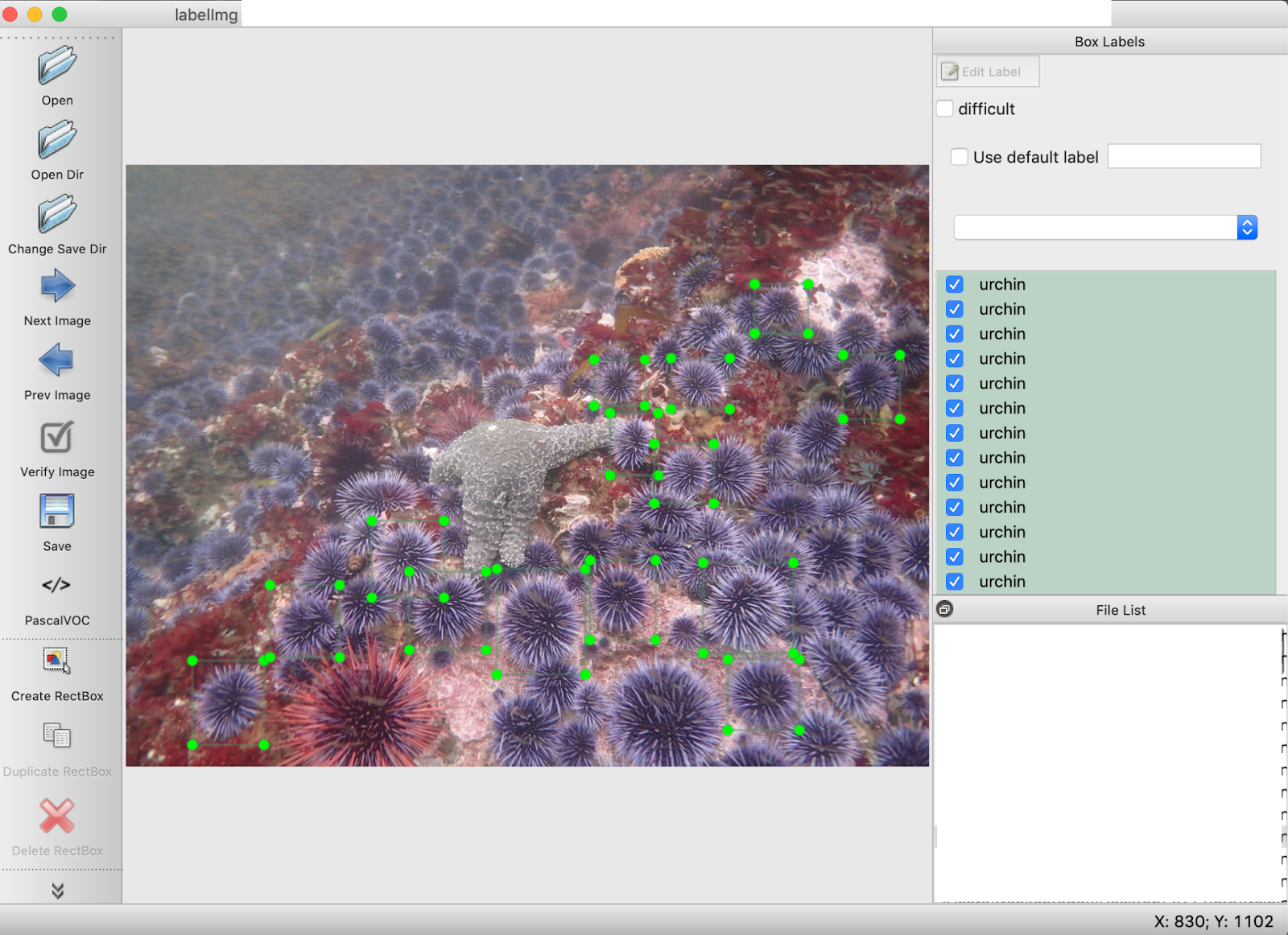
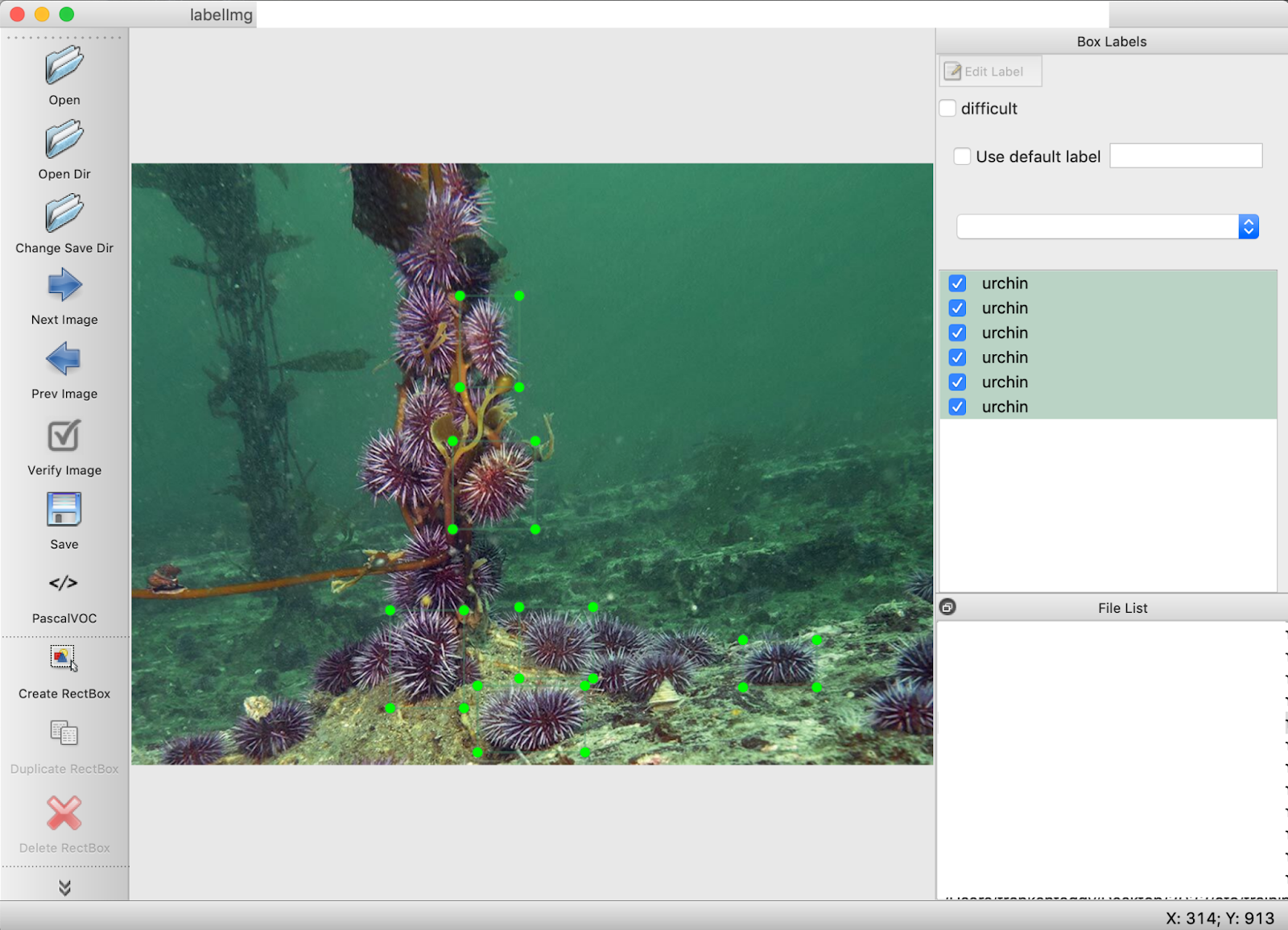
Total images = 108. This was divided up into 68 images for train, and 40 images for validate.
Edge Impulse object detection was used to train the model quickly. In order to convert the annotated images from LabelImg to Edge Impulse’s format, I wrote a Python script:
https://github.com/RobotGrrl/OtterForceOne/blob/main/Scripts/labelimg_to_edgeimpulse.py
The script worked, as demonstrated by the bounding boxes on the image:

Here’s a look at preliminary testing on the model.
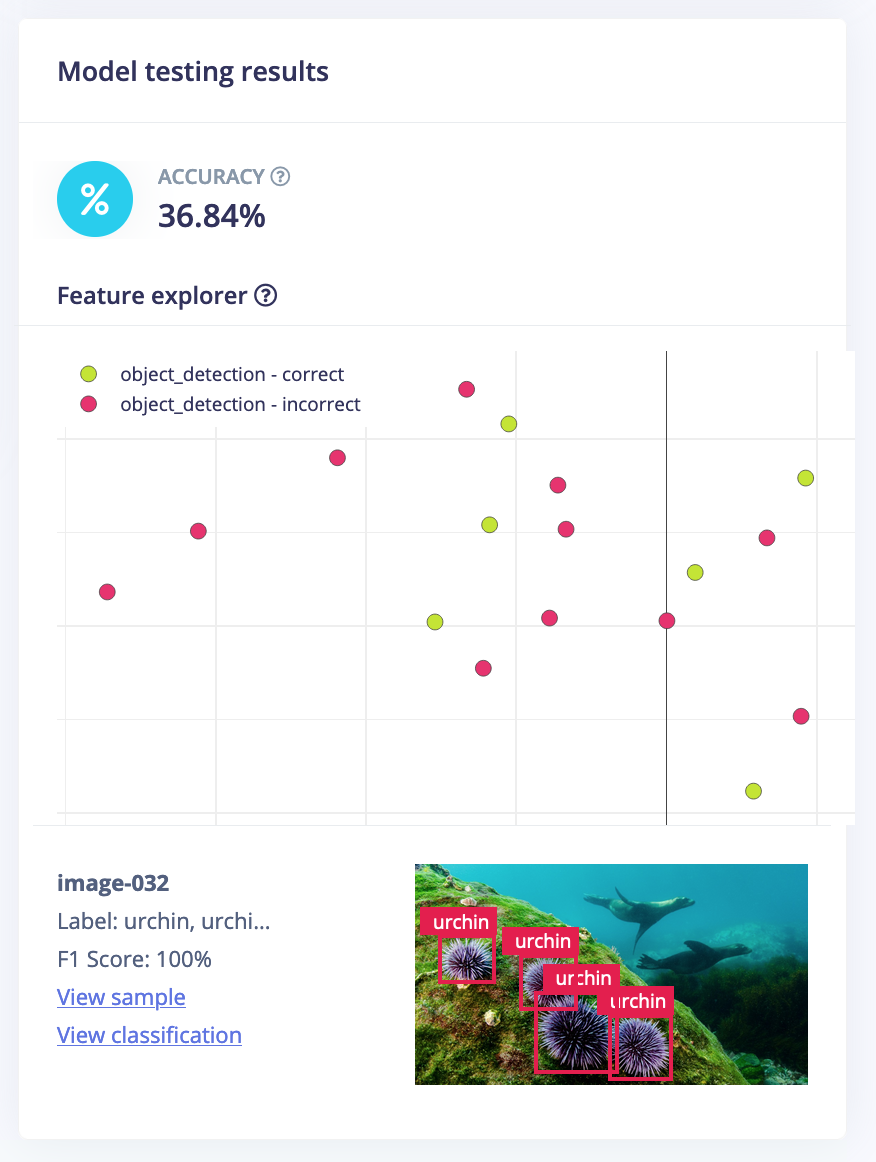
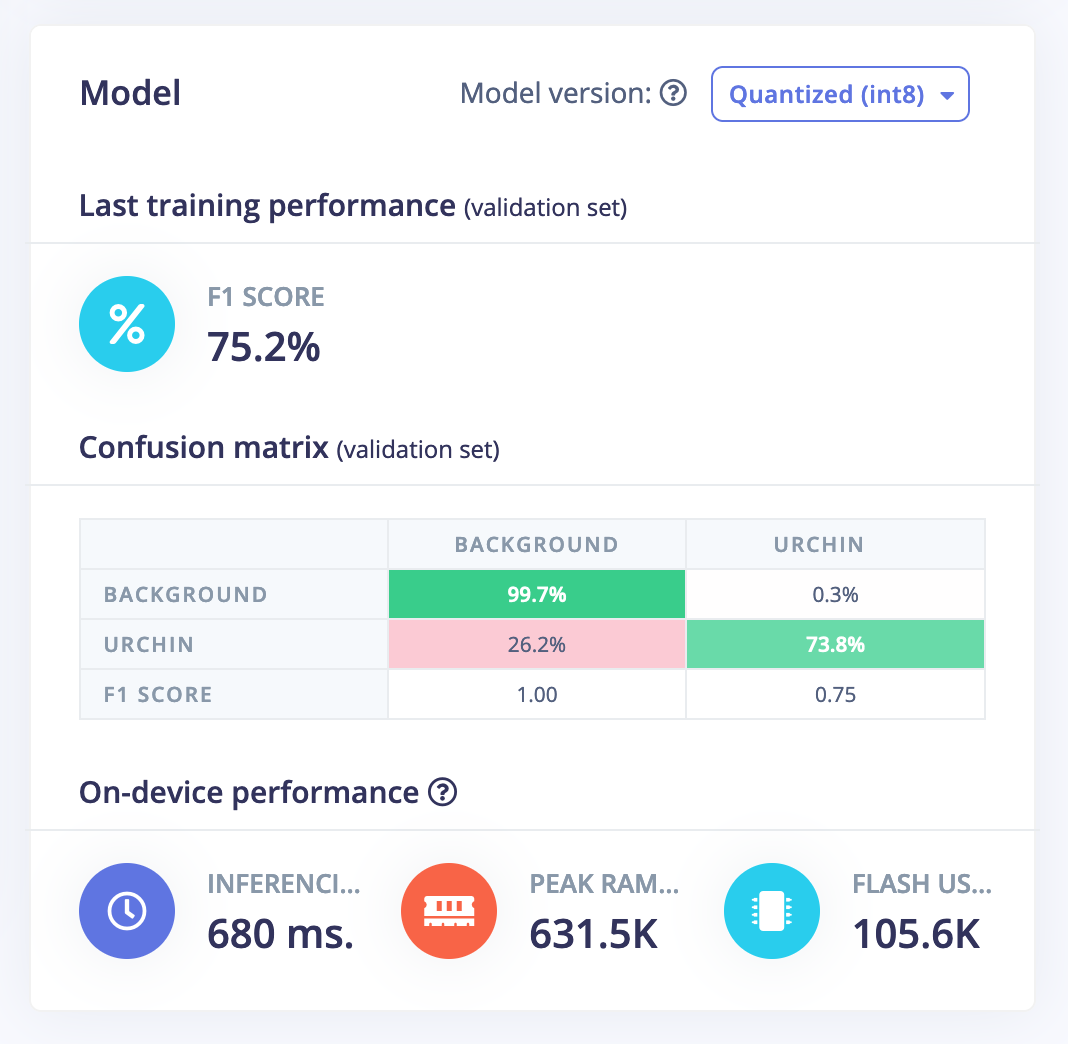
Further investigation is needed, as indicated by this table.
Next steps will include training the model again, using @Evan Juras ‘s (https://hackaday.io/Edje13) Colab Python notebook found here:
There is more information on the repository here: https://github.com/EdjeElectronics/TensorFlow-Lite-Object-Detection-on-Android-and-Raspberry-Pi
Onwards!
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.