 thpoll
thpoll
Actually, I planned to write much earlier about the language layer, but the draft never finished itself ;)
From the spreadsheet color scheme above, you can see that I support 10 languages at the moment. Of course at some point I would like to be able to download any language to the keyboard on demand maybe via the HID interface. Then, there would be no need to use a hard-coded lookup table. However, for this even more needs to be done on the software side and today I will focus on how it works at present.
Maybe the main reason why you are looking at the PolyKB is not language, but program context dependent keyboard functions? Don't worry, I think this is not too much different from the language layer. Let's call it the program or context layer, which would be just another lookup (table) to display a customized text or icon, if there is a function defined for that key. So if your focus is function and not language, please just take it as a template that can be also applied to the program context.
Easier Data Handling
Organizing the language lookup table (lang_lut) in source became an unmanable mess after 3 languages, so I started working with an xlsx spreadsheet, which indeed makes things much easier.
Let's look at the following example:
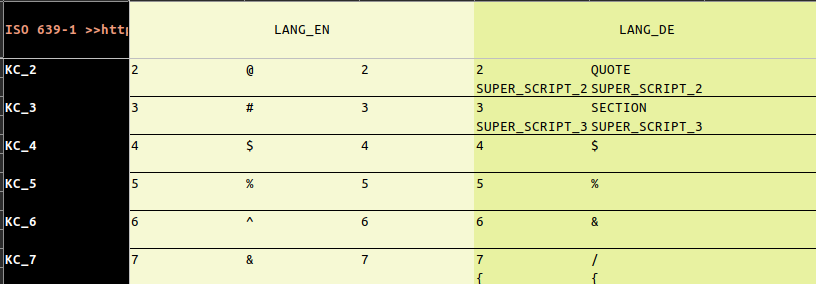
Each language has 3 columns. The first is what's usually displayed on the display, the second when pressing shift and the third, when caps lock is on in case it differs from the second (when pressing shift) case.
This is not uniform! For an english US layout the number keys turn back to numbers when caps lock is turned on (while the letter stay upper case of course), for a german keyboard the wild cards will stay active and behave just like the letters (and therefore there is no entry in the LUT).
Additionally there is a second row for each key to display what the key does together with ALT (GR):

While there is nothing for the US layout, you can see that there is an additional glyph for almost every number key in case of French or Spanish.
Translate the LUT to code
To get the xlsx file into C++ source code I use cog: https://nedbatchelder.com/code/cog/
That's a way to use Python code which is inlined in C++ comments and transform marked sections with that code.
Python is quite handy here because there are libs to do almost anything (including spreadsheet data access).
An example to get all defined languages (lang/lang_lut.h):
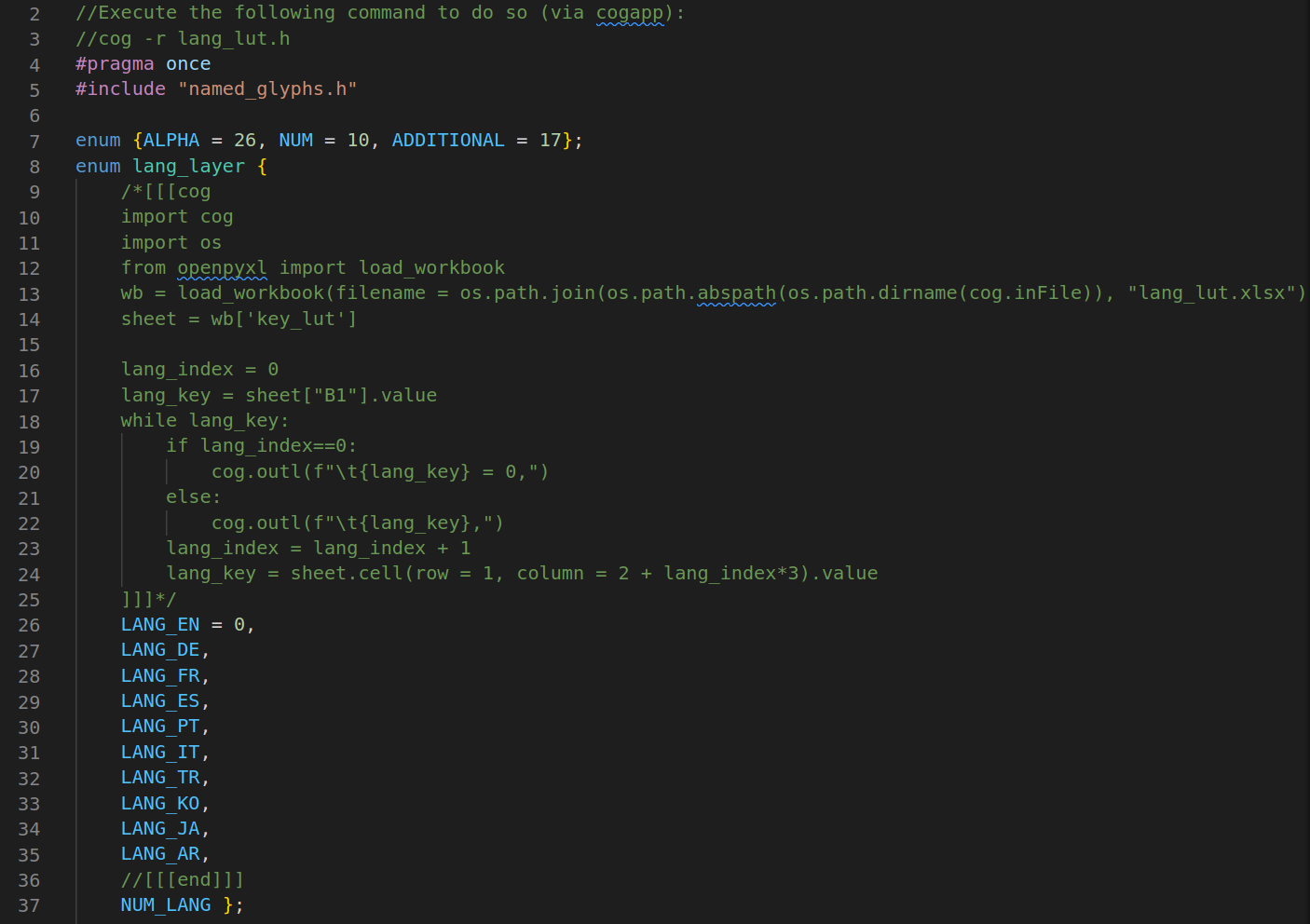
Everything between /*[[cog ... ]]]*/ and //[[[end]]] is generated. Just for the available languages, the effort doesn't pay off. It is an example. The python code that generates the LUT for the glyphs isn't much longer and it generates around 600 lines of code (in lang/lang_lut.c), which exactly why I use cog.
Apart from that it makes it very easy updating multiple code pieces at once. A new entry in the spreadsheet is enough and also dependent code will be updated:
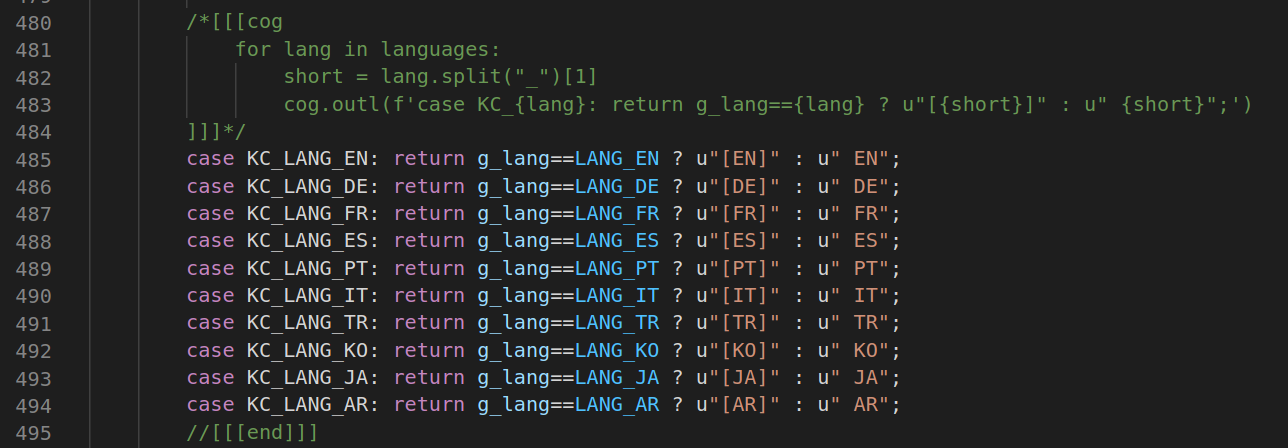
That's very handy!
Cog needs to be executed to update the code sections and so I have a little script to run cog on all source files with Python code parts:
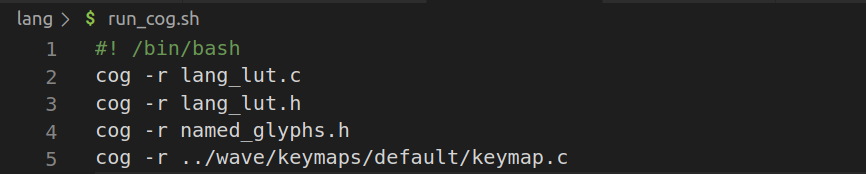
There is still much more work ahead to make this work in a more dynamic way, also for the program context, but let's do everything step by step!
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.