In this log entry I document a refresh of my backend's operating system installation, that I needed to do recently. For the first time, I used docker to setup the CUDA/tensorflow/tensorrt stack and it turned out to work very well for me.
The reason for the refresh was that some days ago, the operating system installation in my backend system turned into a state in which I could not run the lalelu application any more. A central observation was that nvidia-smi showed an error message saying that the nvidia driver is missing. I am not sure about the root cause, I suspect an automatic ubuntu update. I tried to fix the installation by running various apt and pip install or uninstall commands, but eventually, the system was so broken that I could not even connect to it via ssh (probably due to a kernel update that messed up the ethernet driver).
So, I had to go through a complete OS setup from scratch. My first approach was to install the cuda/tensorflow/tensorrt stack manually into a fresh ubuntu-22.04-server installation, similar how I did it for the previous installation one year ago. However, this time it failed. I could not find a way to get tensorrt running and it was unclear to me which CUDA toolkit version and tensorflow installation method I should combine.
Description of the system setup
In the second approach, I started all over again with a fresh ubuntu-22.04-server installation. I installed the nvidia driver by
sudo ubuntu-drivers install
The same command with the --gpgpu flag, that is recommended for computing servers, did not provide me with a working setup, at least nvidia-smi did not suggest a usable state.
I installed the serial port driver to the host, as described in Log #02: MIDI out.
I installed the docker engine, following its apt installation method and the nvidia container toolkit, also following its apt installation method.
I created the following dockerfile.txt
FROM nvcr.io/nvidia/tensorflow:24.10-tf2-py3
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y net-tools python3-tables python3-opencv python3-gst-1.0 gstreamer1.0-plugins-good gstreamer1.0-tools libgstreamer1.0-dev v4l-utils python3-matplotlib
and built my image with the following command
sudo docker build -t lalelu-docker --file dockerfile.txt .
The image has a size of 17.1 GB. To start it, I use
sudo docker run --gpus all -it --rm --network host -v /home/pi:/home_host --privileged -e PYTHONPATH=/home_host/lalelu -p 57000:57000 -p 57001:57001 lalelu-docker
In the running container, the following is possible:
- perform a tensorrt conversion as described in Log #01: Inference speed
- run the lalelu application, including the following aspects
- run GPU accelerated tensorflow inference
- access the USB camera
- interface with the frontend via sockets on custom ports
- drive the specialized serial port with a custom (MIDI) baudrate
Characterization of the system setup
I could record the following startup times
| boot host operating system | 30 s |
| startup docker container | < 1 s |
| startup lalelu application | 11 s |
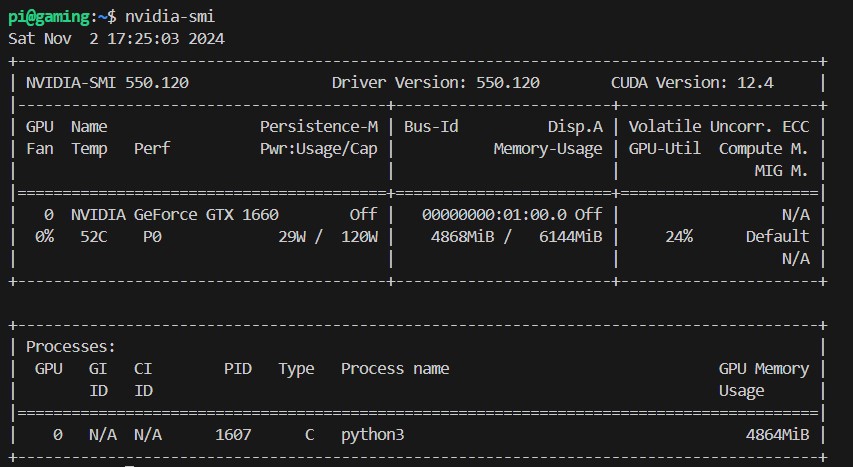
When the lalelu application is running, htop and nvidia-smi display the following

Finally, I recorded inference times in the running lalelu application. The result for 1000 consecutive inferences is shown in the following graph.
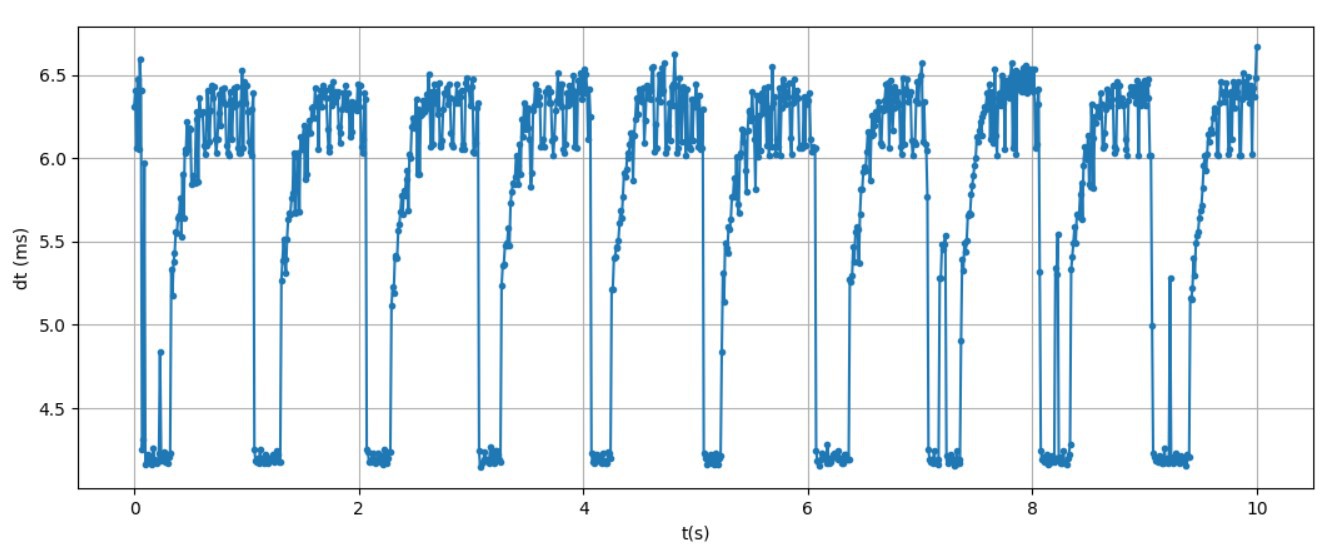
Since the inference time is well below 10ms, the lalelu application can run at 100fps without frame drops.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.