 kasik
kasikI haven't been here for a while but it doesn't mean there was no progress with my project, just not much time to document everything in nice articles. I would love to take part in the contest 2025 Pet Chacks Challenge so I will focus now on description and hopefully soon I will come back here with playing around and with more tutorial style articles.
The last time I made a decent face recognition model both from scratch and with help of Edge Impulse.
In this project I will need to use two models - image recognition and keyword spotting (not to mix with sensor fusion). My arduino nano 33 ble sense has also a microphone, this is why it was selected in the first place - but apparently mine is not working (took me a while to accept it is not me doing sth wrong).
I went on to search for some different hardware - i selected Seed Studio XIAO nRF52840 as both use the same microcontroller.
Ok, now to keyword spotting. For my application I want to be able to react upon the sound of a knock and doorbell. The first step is data gathering - I used mainly FSD50K datasets, where I searched for the variations of: knocking and doorbell sounds. My third class - background had to be robust thus I tried to search for everyday house life sounds. I also made sure to include dog barking (I found even knocking and doorbell sounds with barking) and the sound of dog walking on the floor.
Unfortunately with sounds we cannot go directly to building model as it was with the images - we need to perform some processing first. First step is to ensure that all my data is 1 second long with 16kHz sampling. Next: build a spectrogram which can be considered an audio signal's image representation. To achieve that I ran FFT on every 30ms sample window with a step of 20ms (thus 10ms overlap)
A spectrogram generated this way is not ideal for voice speech recognition because it does not highlight the relevant features effectively. The spectrogram is adjusted to better align with how humans perceive frequencies and loudness on a logarithmic scale rather than a linear one. The adjustments are as follows:
- Frequency scaling (Hz) to Mel scale: The Mel scale filter bank remaps frequencies to enhance their distinguishability and to make them appear equidistant to the human ear.
- Amplitude scaling using the decibel (dB) scale: Since humans perceive amplitude logarithmically (similar to how we perceive frequencies), scaling the amplitudes with the dB scale better reflects this perception.
Time to build the model! Visualization below done with Netron,

And below training results:
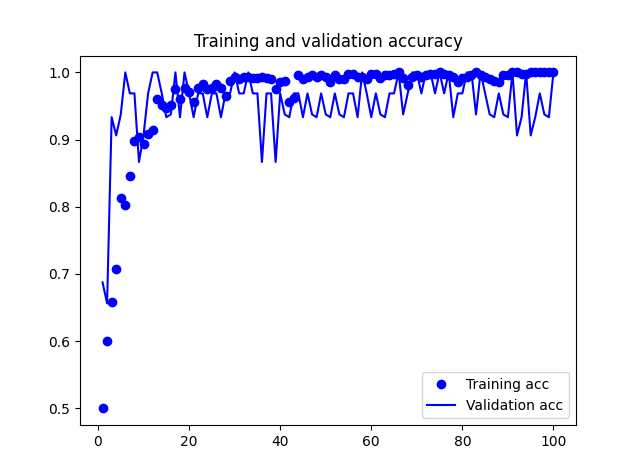
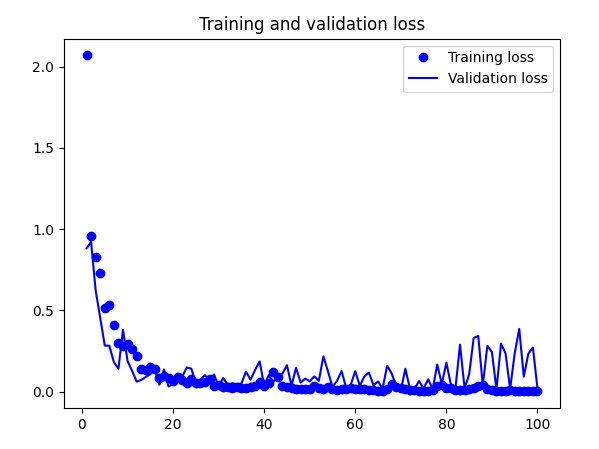
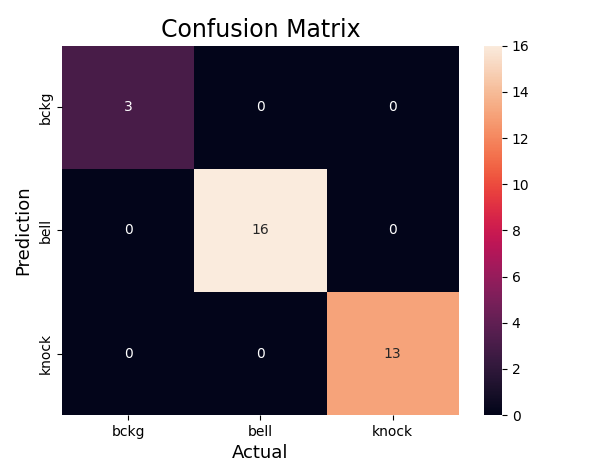
Accuracy of quantized model: 0.9861809045226131
I did the same with Edge Impulse:


Now it's time for the deployment.
Both models did well during tests on the target. However, both struggled with false positives - for example putting a book/mug down was often recognised as knocking. However, I must say it is a fair mistake. There is still some work to be done here, but I believe it is good enough to continue.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.