 glgorman
glgormanI don't know why I never thought about this until now, or maybe I did - but I just wasn't far enough along in my development efforts for it to matter. Yet, like, isn't this all of a sudden - I have an idea. Something that maybe I should follow up on, because I think it is going to turn out to be very useful in transformer land. First, let's take a look at something that I am looking at right now in a debugging session.
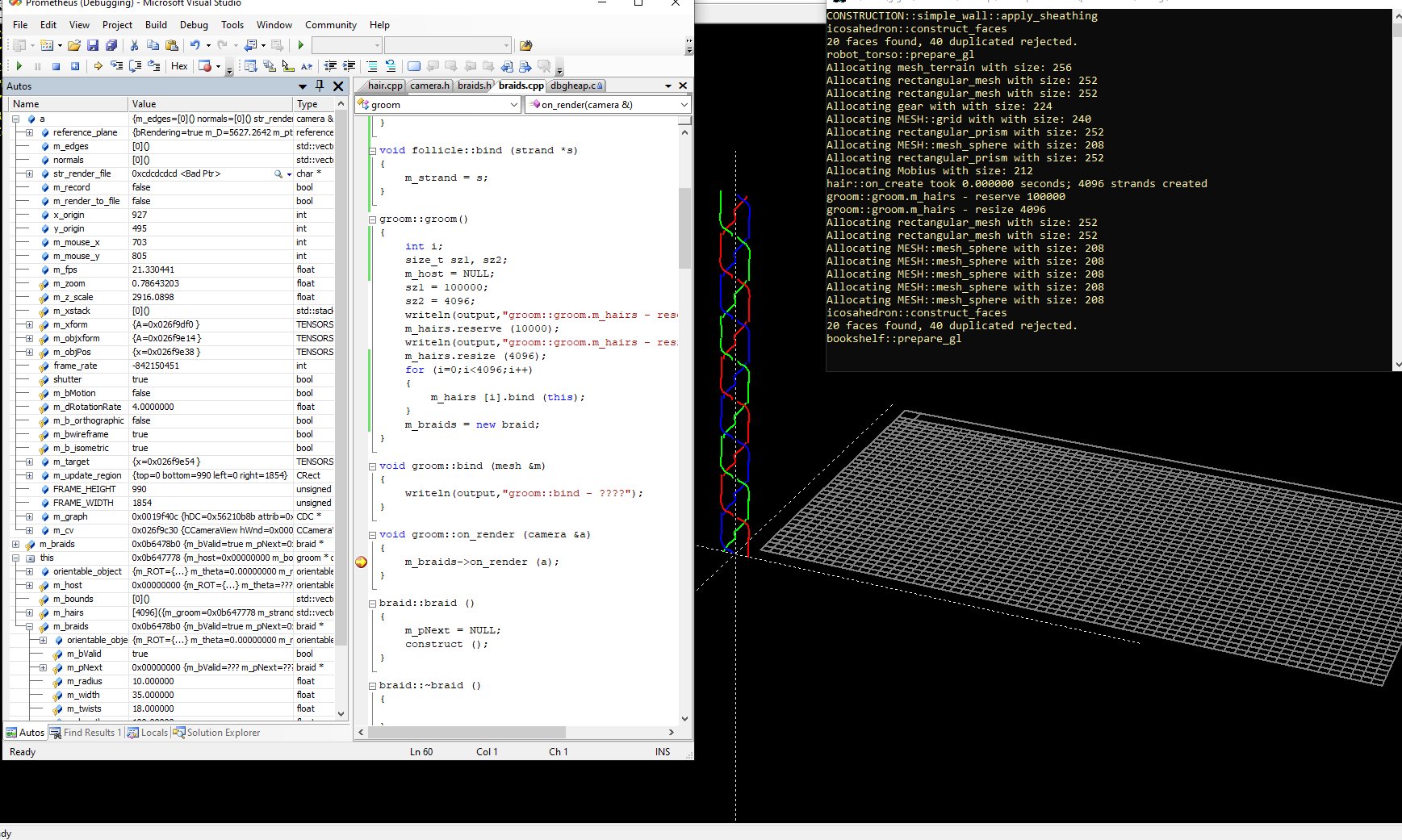
Here, you can see some of the values of some of the member variables associated with the camera class that I use when working with GDI-based stuff in 3D, and one of the things that this lets me do is write code that looks like this:
void twist::draw_strand1 (camera &a, COLORREF c, int i)
{
SETCOLOR _(a,c);
MATH_TYPE theta= 0.0;
MATH_TYPE w = -m_width;
MATH_TYPE m_offset;
MATH_TYPE step_size;
if (i%2==1)
m_offset = -m_width*0.25;
else
m_offset = m_width*0.25;
_vector pos = xyz (theta,i);
pos[0]+=m_offset;
pos[2]+=(m_length*i*0.5);
a.move_to_ex (pos);
step_size = STEP_SIZE;
for (;theta<=360.0;theta+=step_size)
{
pos = xyz (theta,i);
pos[0]+=m_offset;
pos[2]+=(m_length*i*0.5);
a.line_to_ex (pos);
}
}
So the most important part here, I suppose is the ease with which I can simply create objects by drawing in 3D, while doing a bunch of Open GL-like stuff like pushing and popping the necessary object transformations, while in effect generating vertex lists, as well as face and object data in some cases, which then in-turn allows for the creating of obj file like intermediate representations, which can then be played back at will, or saved to a file, or even 3-d printed in some cases. Yet for some reason, until now - even though my MFC application is Multi-Document and Mult-View capable, I have until now only made use of one camera at a time, i.e. when rendering a particular scene - so that in effect I have a CameraView class in MFC that derives from CView, and that in turn allows whichever window it is that is having its OnDraw method called by the framework to translate the 3D view into the final GDI calls for onscreen rendering. Otherwise, the more general conversion of primitive objects into fully GL-compatible objects is still a work in progress.
Yet what would happen if I for a sufficiently complex object, and for such a complex scene that might have doors, windows, mirrors, etc., I then create one camera for each point of view within the scene, or perhaps better still I try binding multiple instances of the camera class to some of the more complex objects themselves. Or, in a so-called "attentional" system, I try to find a meaningful way to bind multiple camera-like objects to the so-called transformers within a generative AI. Maybe this kind of recapitulates the notions of the earliest ideas of the programming language Smalltalk, that is in the sense that not only should you be able to tell an object to "draw itself" - yet obviously,, if I wanted to have multiple regions of braided hair, and each braid or bundle could take "ownership" or at least "possession" of a thread, let's say out of a thread pool, not just for concurrency reasons, but also for code readability and overall efficiency reasons, that is to say - just so long as RAM is cheap.
So, if a "groom" object might be associated with 100,000 hairs, for example, then how does sizeof(camera) affect performance if we bind the camera object to the object instead of to the view?
Testing this code snippet, I find no obvious effects on the program's behavior, other than to learn that the current size of the camera class object is just 504 bytes.
void groom::on_render (camera &a)
{
camera b = a;
size_t sz = sizeof(camera);
m_braids->on_render (b);
}
Now, I don't want to incur the cost of copying the current rendering context every time I want to draw a polyline, but remember, there is a huge advantage to doing this, and it is not just because of parallelism. For example, if an object can do its own occlusion culling within a private rendering context, then that greatly simplifies the management of the BSP-related stuff. Yet in a transformer-based AI that employs a multi-headed attentional system, this might be a critical step, i.e., by optionally binding rendering-contexts, as well as the data that is managed within then, not only to views or realms, but so also to objects, or perhaps transformers. Maybe it is that hard after all?
Naturally, I had to ask Deep Seek what it thinks of this - right!

Well, for whatever it is worth, it doesn't seem to have any insights about anything that I don't feel as if I already know. Yet it is pretty good at summarizing some of the content of this article, on the one hand, and maybe viewing the proposals herein in an alternate form might have some value, as in "Help me write a white paper that might seem of interest to venture capitalists", even if that isn't the question that I asked at all. Still, it's insight about AI implications seems more on target with what I was hoping to see, i.e., "In a transformer-based AI, multiple cameras could act as 'attention heads, ' each focusing on a specific region or object. This could enhance the AI's ability to generate or manipulate 3D scenes with fine-grained control."
At least it is polite.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.