 glgorman
glgormanOr some other snooty remark. Like I said earlier. So, I have started on a C++ class based on the article that I saw about doing neural networks, with genetic algorithms, no less - on an Atari 800XL
class ann
{
protected:
int NH,NN,NP;
int NM, NG;
double DB_INIT, F_INIT;
double F, DB, DF;
double DIST;
double (*m_fptr)(double);
vector<double> x0, y0;
vector<double> U, wb, out;
public:
ann ();
void init (int i);
bool bind (double(*fptr)(double));
void randomize ();
void train(int iter);
void store_solution (int N);
double test (double val);
};
Obviously, there is a lot more of this, but what I really think that I should be doing is to actually put some of the graphics capabilities of my framework to good use. That would be kind of fun to watch in action, of course, whether on a PC or on a classic 8-bit system. C++ is of course, convenient, but maybe I could eventually try this in Apple II Pascal or using Flex-C on the Parallax Propeller P2, just as soon as I figure out what it is that I am actually trying to do with it. Then of course, there is also the task of figuring out how this relates to the land of all things LLM-related. Maybe I should mention a conversation that I had with a chatbot a couple of years ago about the Yang-Mills conjecture since some of that might turn out to actually be relevant, finally - after all of this time.
Maybe I am thinking about the idea that I had about pasting oscilloscope data on the surface of a cylinder, or warping the same data onto a sphere, and then how I realized how easy it is for that to get into either special or general relativity, so that sort of thing could both be a use case for an LLM, insofar as working out the theory, but also a use case for neural network based equation solvers.

So obviously, there is more to this game than just regular tessellation, OpenGL, Cuda or whatever. Yet I am thinking about something else, of course, and that is also the problem of the icosahedron, which tessellates so much more nicely than the sphere, like if we take the icosahedron and subdivide each face into four triangles so that we get an 80 sided polytope, which can, of course, be further subdivided get a surface with, let's say 320 faces, which is pretty close the number of dimples on most golf balls. Interestingly enough.
Thus, in the meantime, I can definitely see some serious use cases for using neural networks of whatever type for some kind of vertex nudging, for example. Yet, as suggested, it could get very interesting when we consider the possible role of LLMs as stated also, either in actual code or in developing the design concept.
Even better if Deep Seek or something similar should turn out to be useful for generating useful models that can not only be run on the desktop but can be trained locally.
In the meantime, however, we can have some more fun with our C++ version of the original genetic algorithm by making some things a bit more generic. I am surprised, for example, that the original BASIC code simply fills an array in a loop by squaring the training values directly. Why not use the DEFINE FN idiom that most BASICS have to define a callable function that takes an argument and then returns a value, just like we are accustomed to in a higher-level language such as C, or even Pascal or Fortran for that matter? Maybe it is just too slow to do in BASIC. Well, that doesn't mean that we can't do this is C++, however.
Let's take a look at two functions, bind and square:
bool ann::bind (double(*arg)(double))
{
m_fptr=arg;
if (m_fptr!=NULL)
return true;
else
return false;
}
double square (double arg)
{
double result;
result = arg*arg;
return result;
}
Now for those who are unfamiliar with the arcane syntax of C/C++ function pointers, I have introduced a variable to the ann class, named m_fpt, which is of course, a member variable in which we can store a pointer to a function, i.e. the address of the function that we want to train on.
int atari::main()
{
int t1,t2;
int iter = 32768;
int n;
ann test;
t1 = GetTickCount();
test.bind (square);
test.init (iter);
for (n=0;n<iter;n++)
{
test.train (n);
}
t2 = GetTickCount();
writeln (output,"Training took ",(t2-t1)," msec.");
return 0;
}
Notice that line of code where it says "test.bind(square)"? That is how I tell the neural network the name of the function that I want to train on, and in this case, square is simply a function that takes a double as an argument and which in turn returns a double. Likewise, I have started the process of breaking out the training loop, so that it could perhaps even be broken out into a separate thread, which could be made callable in the simple, usual way, while at the same time, "under the hood" a message might be passed instead to a waiting thread which would run each iteration, that is to say - whenever it receives a message to do so.
Even if I don't know if the code is working the way that is it supposed to, at least I know that last time I checked function pointers to work in Flex-C on the Parallax Propeller P2, and hopefully they also work in GCC for Arduino.
Now that I think about it, of course, maybe that MoE class, i.e., the mixture of experts class from Deep Seek, shouldn't look so intimidating. Or put differently, if we try to train bigger genetic models, let's say, by using Cuda, then it is going to be essential that we embrace some of the inherent parallelism in this sort of algorithm, as we shall see shortly!
Now, I also need to try using some graphics capabilities so as to be able to watch the whole process while it happens. In this case, changing the number of training points from 3 to 8. and the number of neurons to 16 enabled me to run 32768 iterations in 12250 msec using a single thread on a Pentium i7 in running compiled C++ in debug mode. I added some code to go ahead and dump the neuronal weights each time an iteration results in an improvement over the previously stored best result. Obviously, if improvements in performance are rare enough, especially as the number of iterations increases, then it should be easy to see how this algorithm could benefit from parallelization!
Then I decided to try to use a proper sigmoid function, and that actually seemed to hurt performance. So, I had to introduce some gain parameters to deal with the overall fussy nature of the whole thing. But it is getting a bit more interesting, even without trying to parallelize things yet. Right now, I am trying to run it with 8 neurons but with 16 training points. Obviously, when trying to get a neural network to imitate a simple function like x^2, it should ideally be testable with arbitrary data. Yet, clearly while it is actually quite fussy, it is also quite easy to think of lots of ways to optimize the technique, that is, without completely breaking the ability to get something that can still run on a smaller system.
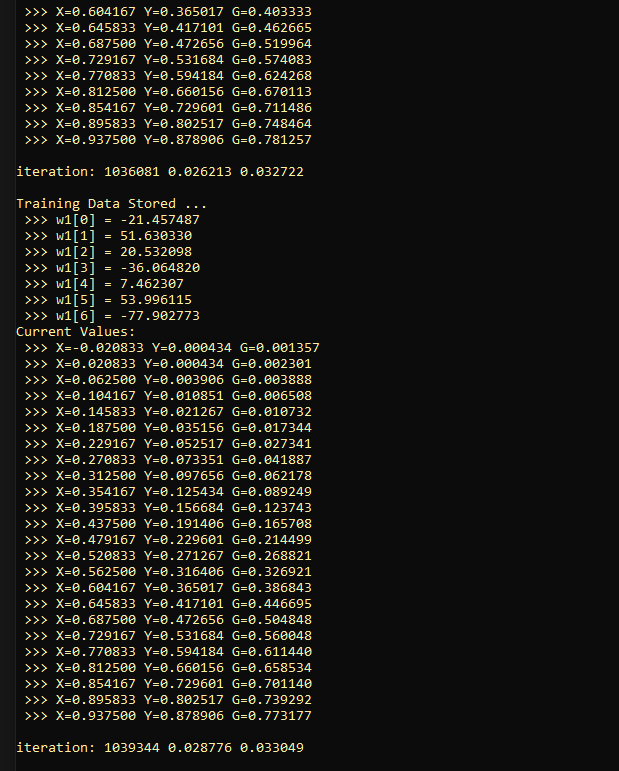
In any case, here is the latest mess, which is actually starting to look like something.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.