 Robert Morrison
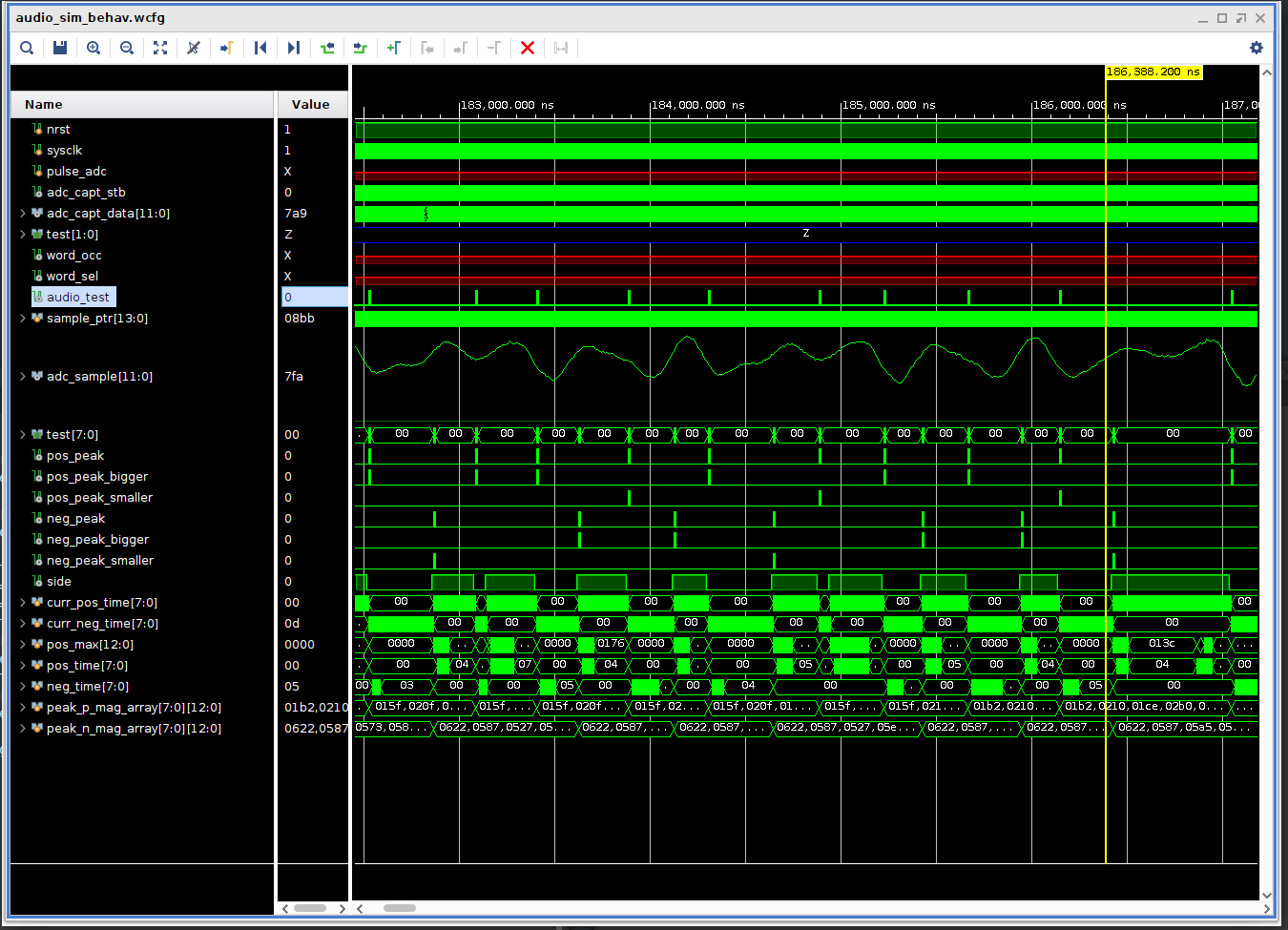
Robert MorrisonI am writing the voice detection code. I set up a nice simulation environment that allows me to visualize the incoming audio and see the analyzed results. This is especially cool because I modified the microphone/ADC diagnostic data converter to also output to an FPGA ROM load file, thus allowing me to simulate what the FPGA will do on actual voice data from the microphone.
Conventional methods for voice analysis use FFT conversion code and AI to train responses. This is extremely compute intensive even for inference generation and isn't really practical for putting into this logic probe hack. Yes, Nicla and similar ilk come close, but I want to try a more directed approach. I am not doing an FFT (even though the FPGA has the capacity to do that). Instead, I am doing a comparative peak detection method which generates recognition codes, sort of like pre-parsing a high level language for compiling efficiency. I will then compare these recognition codes to known valid voice codes to recognize what the microphone hears.
I don't know if this will work, but it's so far doing a nice job of generating unique codes for simple vowel detection. Here's a simulation pic, the test values show when positive and negative peaks are detected and whether the current peak is bigger or smaller than the last one.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.