 Neil K. Sheridan
Neil K. SheridanThis time I used 1000 negative training images from the caltech256 dataset. I only used parts of dataset containing animals (chimps, llamas, gorillas, kangaroos, horses, elks,..) and some landscapes (not urban) this time. These 1000 again being selected pseudo-randomly from the images I had on storage drive from the dataset. I again used only 64 positive images from the earlier caltech dataset. I used hard-negative mining on 50 images this time. That took around 40 minutes on the EC2 (virtual machine) m4.4xlarge instance I was using.
The workflow is:
- extract features from the positive and negative images (2 minutes)
- train object detector (45 minutes)
- hard-negative mining (40 minutes)
- re-train object detector with the hard-negatives (45 minutes)
N.B. If you are using EC2 like me, you can end up with broken pipe in SSH session if the client sleeps during long training sessions :-(
So how would it get on with cows and rhinos this time!? It even detected farmers once last time!
Much more promising results!

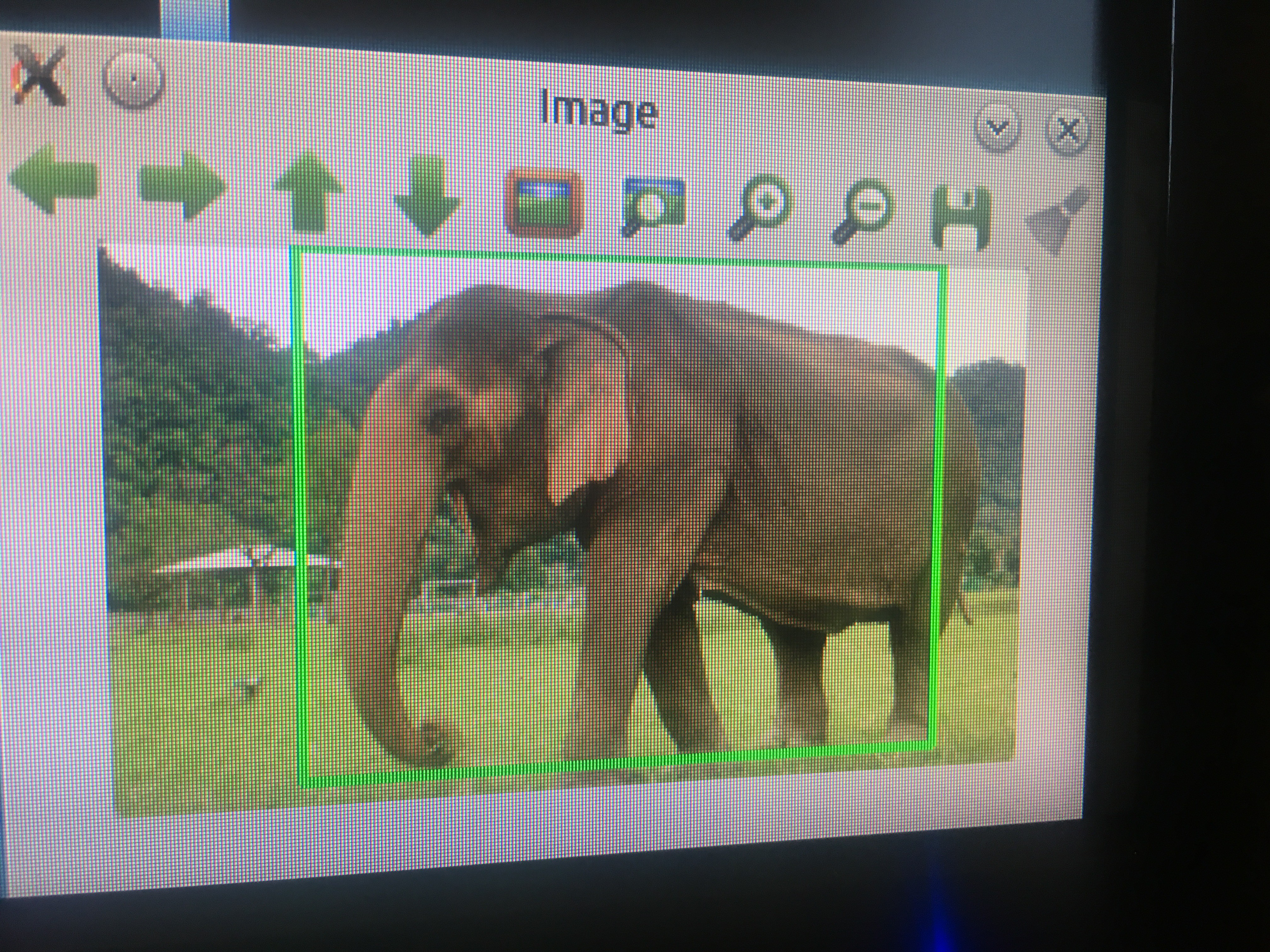

Farmers in fields not detected!

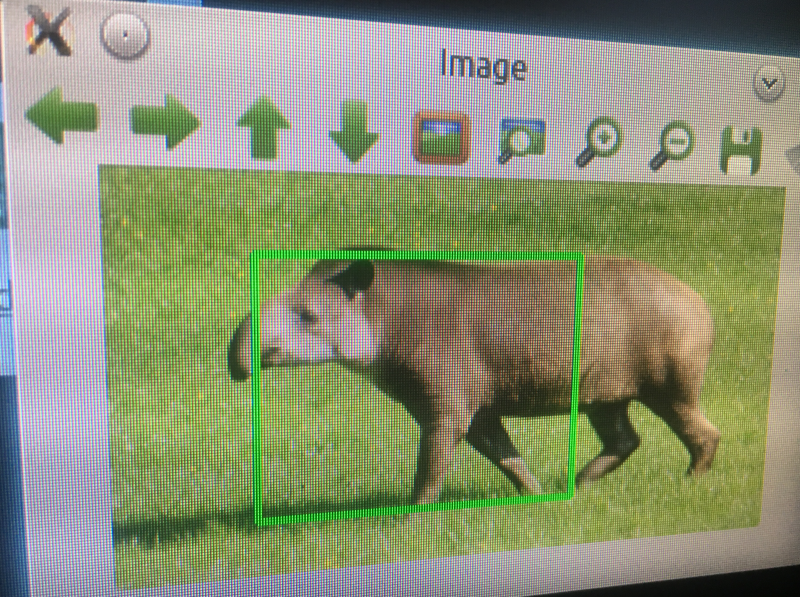
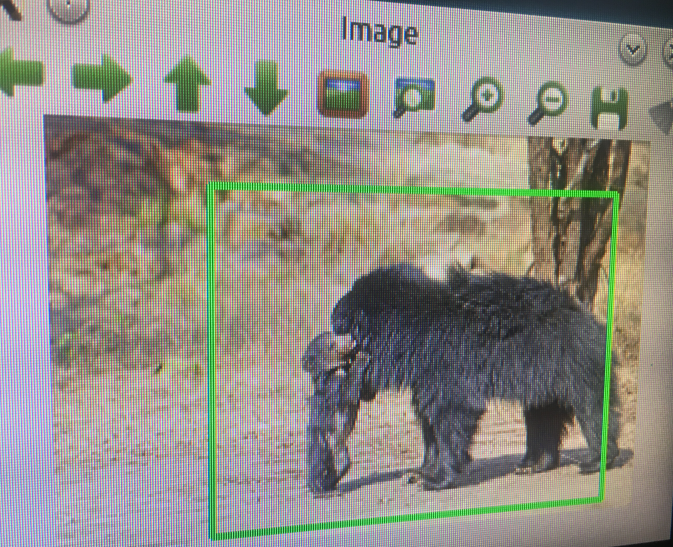
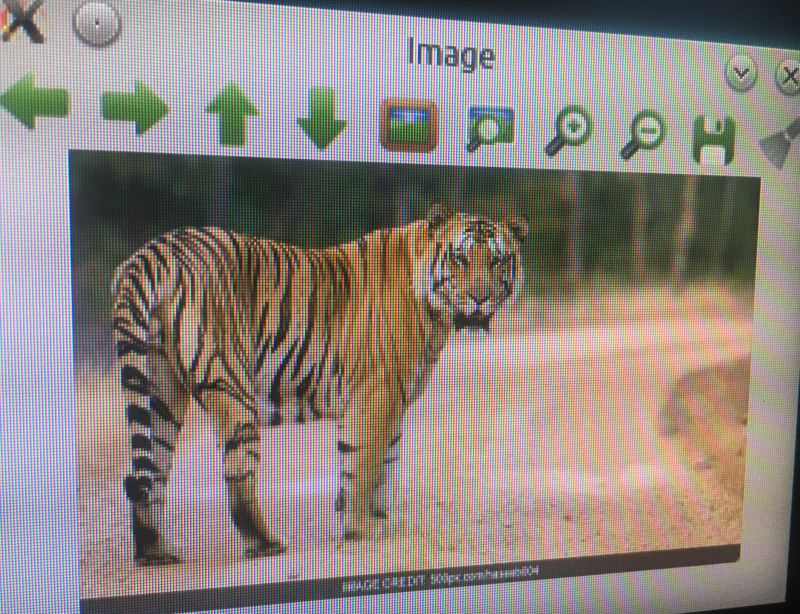
I didn't undertake any stringent testing protocol to gather a percentage of false-positives and false-negatives at this early stage.
The different approach this time was to include primarily animal-based negative training images, increase the negative images used from 700 to 1000, and perform hard-negative mining on 50 vs. 10 images.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.