 zpekic
zpekicI was really curious how the Basic CPU will perform in comparison with classic CPUs of the home computer era and put some effort into optimizing the design with that goal in mind. Based on the benchmark tests, the goal has been only partially achieved. While in some cases the speed up of factor 4 to 8 looks noteworthy, my suspicion is that those Basic interpreters by default work with software - implemented floating point for the benchmark test (haven't explored them in depth), while other group showing more modest gain of 1.5 to 2X are "integer Basic" implementations, and a more fair comparison.
CPU performance optimizations I used:
Clock frequency
A bit of "cheating" going on here - whole design is inside the FPGA which allows it to work at maximum available hardware clock frequency of 100MHz. Most importantly, the "core" RAM (Basic input buffer and program store) can be accessed in 1 or 2 clock cycles (so 10 or 20ns):
writeCore: nWR = 0, if nBUSACK then repeat else return;
readCore: nRD = 0, if nBUSACK then repeat else next;
nRD = 0, MDR <= from_Bus, back;
This would clearly be impossible if the RAM is outside of the FPGA, even on the same board. Depending on the CPU clock and memory speed, one or more wait cycles would need to be added. Anvyl board has a breadboard section, so in future I may move the Basic core memory to a 62256 type device and experiment for example how many wait cycles does a 70ns vs. 120ns memory chip need.
Other limiting factor is I/O speed. Currently, max I/O serial speed is 38400 bps. Sending and receiving 1 byte over such channels takes at least 10-bit times, during which CPU has to wait for the ready signal.
outChar: if CHAROUT_READY then next else repeat; // sync with baudrate clock
if CHAROUT_READY then return else repeat;
FIFO queue on both input and output would help, but their implementation belongs to the Ser2Par and Par2Ser components, not the CPU (except for the trace serial output, but that one is only active up to 4kHz CPU frequency so not much gained there).
Cycle overlap
Basic CPU is a CISC processor, and pipelining is not traditionally their strength. However a very limited opportunity of overlap is used between execute and fetch in few instructions. Note that the fetch cycle has two entry points:
fetch: traceString 51; // CR, LF, then trace Basic line number (in hex, for speed)
fetch1: traceString 2; // trace IL_PC and future opcode
IL_OP <= from_interpreter, IL_PC <= inc, traceSDepth; // load opcode, advance IL_PC, indent by stack depth IL code if tracing is on
T <= zero, alu <= reset0, if IL_A_VALID then fork else INTERNAL_ERR; // jump to entry point implementing the opcode (or break if we went into the weeds)
Most instructions finish their execute cycle and then branch back to "fetch" (no overlap). Few have the opportunity to execute "traceString 51" operation while in parallel doing other operations, and when done can branch to "fetch1" - this is a 1 clock cycle overlap. This could be utilized more, but tracing at the beginning of fetch cycle is very convenient debug tool, so this was an engineering compromise between 2 important goals (troubleshooting and performance).
////////////////////////////////////////////////////////////////////////////////
.map 0x12; // FV (Fetch Variable)
////////////////////////////////////////////////////////////////////////////////
traceString 36; // trace mnemonic
Vars <= indexFromExpStack, if STACK_IS_EMPTY then ESTACK_ERR; // get index (variable name A-Z)
T <= from_vars, ExpStack <= pop1, traceString 51; // T <= Vars(index)
ExpStack <= push_TWord, goto fetch1; // push onto stack, go to 2rd fetch entry point as we overlapped 1 cycle
Parallel operations
Basic CPU uses "horizontal microcode" with fairly wide control word of 80 bits:
- Microprogram execution control: 5 bits to select 32 conditions, 9 bits to branch to "THEN" case, 9 bits for "ELSE" - total of 23 bits, conceptually 1 field
- "direct fields" that provide immediate data for the microinstruction being executed: 11 bits, 5 independent fields
- "register fields" define the transfer of data into the registers at the end of current microinstruction - 46 bits in 22 fields
In theory, all 28 fields could independently specify an operation in parallel, so that all components within the CPU work in parallel. Obviously, Basic CPU is far from this ideal goal. Execution control is by definition engaged in every microcycle, but in average only 1 or two others. One of the better ones is this one:
directByte = ' ', writeCore(InlEnd, from_microcode), InlEnd <= inc;
Following operations are being executed in same clock cycle:
- MAR register is loaded with value from InlEnd register
- MDR register is loaded with immediate value carried in the directByte field
- InlEnd register is incremented
- Microprogram counter is loaded with the address of "writeCore" routine, while the return stack pointed by microprogram stack pointer is loaded with current address + 1 (subroutine call can be done in 1 clock cycle due to design of the control unit)
4 operations, far cry from the 20+ possible. Interestingly, the MCC compiler could easily provide static microcode effectiveness analysis by counting the average parallelization (not currently implemented). Even better would be during runtime, when microinstructions executed more would carry more weight in the metric.
Algorithm optimizations
Copying 1 byte in the core memory takes 5 clock cycles:
//--- copy Y bytes in Core memory from S to R ---
copyCore: T <= from_S, if Y_ZERO then return; // bail if no bytes left to copy
readCore(T);
T <= from_R;
writeCore(T, same);
//traceALU();
alu <= copy_next, goto copyCore; // Y--, R and S incremented / decremented based on direction
It is easy to see how this could be collapsed to 3: allow the MAR register to be loaded directly from S and R registers, instead of going through T. Turns out this optimization would be costly (addition of 1 control bit to the microcode control word width) and also not necessary: memory copy is only used when inserting lines into the program, which happens in command mode (usually human interaction) and would not speed up the Basic program.
However there are some other places that impact execution speed and I tried to optimize them:
- Signed division: 18 cycles typically (set up, 16 iterations, sign correction)
- Binary to BCD conversion: 1 + 16 max (set up, up to 16 iterations but bail when only zeros remain in the source binary number)
- Signed multiplication: 1 cycle (using the combinatorial multiplier in the FPGA)
- Other arithmetic operations: 1 cycle
(actual instruction times are longer due to stack push / pop overhead, tracing etc.)
GOTO cache
This component is the single most significant perf accelerator. Depending on structure of the program, up to 2-3X faster runs with GOTO cache on. The reason is easy to see. Structure of Basic program is as follows:
- 0 to n (limited by core memory size) lines / statements:
| Line number | statement text, ASCII as entered | 0x0D |
| 2 bytes, 1 word in big endian format | n bytes | 1 byte |
- 2 consecutive bytes of 0x00 (or one word with value 0)
In order to execute GOTO / GOSUB, whole memory must be searched from beginning, first reading and checking the word (for target number match), then all bytes following until 0x0D (carriage return) and then continue until:
- found and execute the jump / subroutine call
- found line number 0 (end of program) - report an error
A simple 1-way, 32-entry direct-mapped cache allows avoiding this traversal and providing the address of the target statement start leading to a dramatic perf improvement.
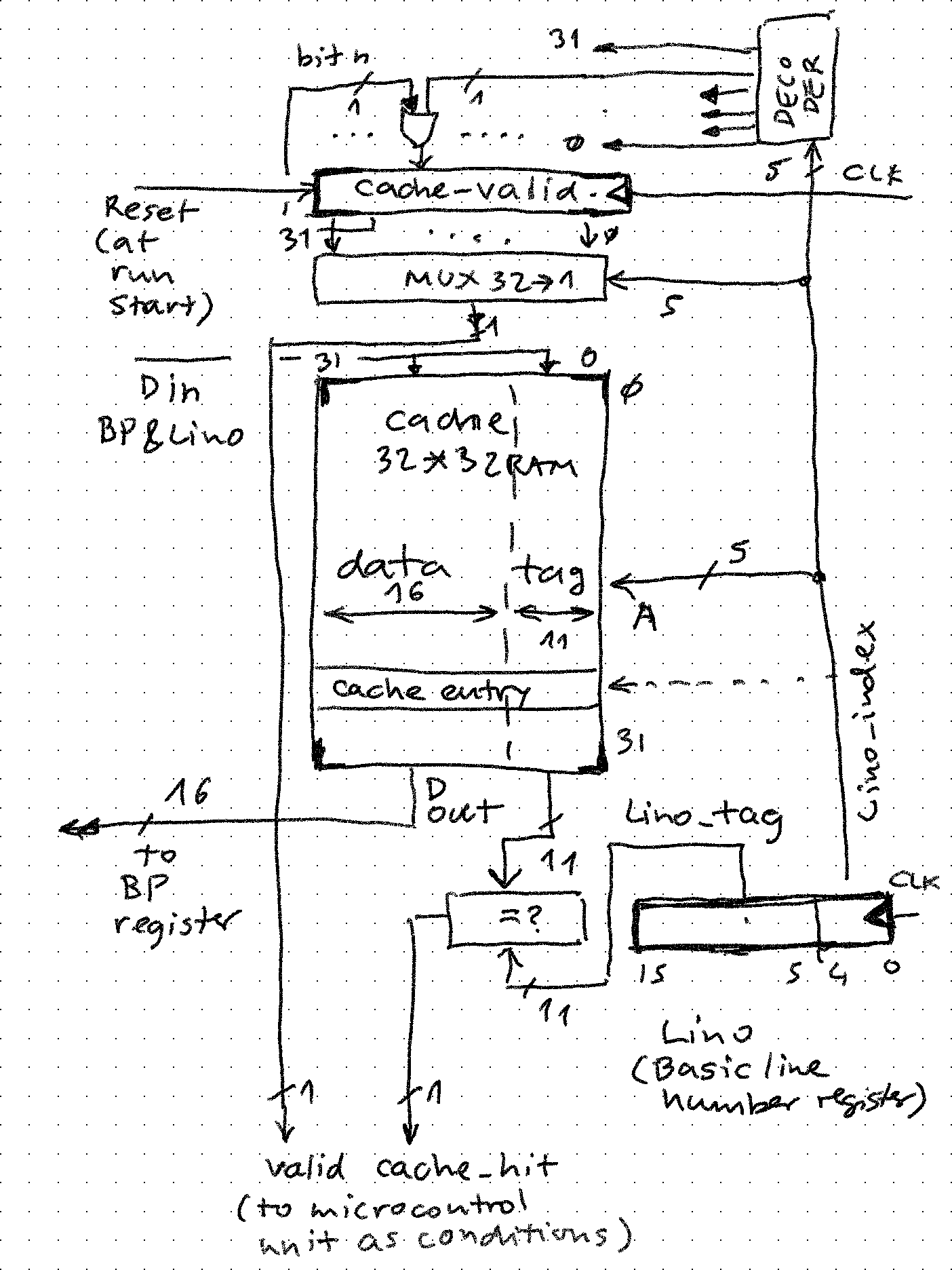
How does it work:
- 32 bit cache_valid register is cleared when Basic program starts to run (condition detected by hardware by checking the before / after value of Lino (line number register). If it goes from 0 to !0, reset
- Target line number for a GOTO is pulled from stack and lands in Lino register
- Last 5 bits of Lino are used to look up the valid bit in cache_valid (simple 32 to 1 MUX) and the entry in the cache (address presented to 32-word cache memory). For example in case of GOTO 100, 5th bit and 5th entry in cache would be selected
- Each entry (frame) contains data and tag. Tag is compared with upper 11 bits of Lino (value of 0b11 in case of GOTO 100), and if same cache_hit condition arises. Following cases are possible:
- valid = 0, hit = 0: entry is free, microcode looks for statement 100 and if found stores BP (address found) and upper 11 bits of Lino into the entry. cache_valid bit is flipped to 1. We pay the price of search for statement 100 now but not again (compulsory cache miss)
- valid = 0, hit = 1: same as above, there was junk data from previous Basic program run
- valid = 1, hit = 0: this entry has already been occupied by some other GOTO. For example in simple cache like this (no associativity, no purge) if GOTO 900 were executed first, it would take the entry and sit there until end of program (conflict miss)
- valid = 1, hit = 1: skip looking for beginning of statement 100, load BP with cache data (cache hit)
Microcode needs to just examine these two conditions and take proper path:
////////////////////////////////////////////////////////////////////////////////
.map 0x16; // GO (GOTO)
////////////////////////////////////////////////////////////////////////////////
traceString 45; // Trace mnemonic
IL_PC <= XQhere, if STACK_IS_EMPTY then ESTACK_ERR; // IL_PC <= XQhere, check stack
alu <= R_fromStack, ExpStack <= pop2;
T <= from_R;
Lino <= T, if R_IS_ZERO then NOPROG_ERR; // once Lino is set, CACHE_HIT and CACHE_VALID are meaningful
// traceLino;
if CACHE_VALID then go_cvalid;
// INVALID: the cache entry is free, find target and store in cache (and stay there until end of run)
findLino(Prog_start);
alu <= cache_store, goto fetch; // cache[Lino(4:0)] <= Lino & BP, cache_valid[Lino(4:0)] <= 1
go_cvalid: T <= Cache_Data, if CACHE_HIT then next else go_cmiss;
// VALID HIT: pick it up and use it
BP <= T, goto fetch;
// VALID MISS: other GOTO already used the entry, no attempt to kick it out, take the perf penalty
go_cmiss: findLino(Prog_start);
goto fetch; Given the impact of cache on performance, I may in future improve the cache by implementing some of the well-known cache design choices:
- Add associativity (simply the entry for GOTO 100 can go to 2, maybe 4 slots instead of 1)
- Add purge policy (each entry has some time to live, or miss count after which it gets replaced - imagine GOTO 100 taking the entry first, but then later GOTO 900 is executed in a loop thousand times - it would be beneficial for address of 900 be stored in the cache)
- Possibly split GOTO and GOSUB caches - simplest but provides benefit only for programs with subroutines
- Any combination of the above
Implementing proper cache would require measuring hits/misses during runs of various benchmark programs. Implementing such hardware is easy but devising and running such programs isn't. Right now, I am happy with 3 blinkenlights:
- cache empty - green LED
- cache not empty - yellow LED
- cache full - red LED
-- GOTO cache
cache_empty <= '1' when (cache_valid = X"00000000") else '0'; -- all 32 entries free
cache_full <= '1' when (cache_valid = X"FFFFFFFF") else '0'; -- all 32 entries used
cache_entry <= cache(to_integer(unsigned(Lino_index))); -- data/tag cache entry pointed to by Lino
cache_hit <= '1' when (cache_tag = Lino_tag) else '0';
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.