 zpekic
zpekicWhile in it original form it can already be useful (esp. for embedded apps), the original Tiny Basic interpreter is very rudimentary and is lacking many features. During the same time, another Tiny Basic version emerged. It was a classic interpreter (no intermediary code) but had a bit bigger feature support.
With some minor tweaks, I was able to largely close the gap. What is missing:
- Multiple statements on same line (there is limited support: only in run mode, and only after INPUT, LET, POKE, PUSH, POP statements. FOR/NEXT must be own statement, PRINT already uses ":", and for GOTO / GOSUB / RETURN makes little sense as they "jump" and not continue execution)
- Logical operators in assignments
- Specifying field length when printing values
On the flip-side:
- TB executed on Basic CPU is >5x faster than same Basic code on classic Tiny Basic interpreter on 8080 (35s vs. 197s both running at 25MHz)
- Better handling of control codes (all ASCII control codes can be embedded in the print string using ^, including CR (^M))
Here is the list of new capabilities and how they were implemented. Depending on the feature, changes were needed in any of the code layers (interpreter or microcode), or in hardware itself (Basic CPU)
Basic feature | Interpreter | Microcode | CPU |
| NEW | added to parser and execute as CLEAR Note that neither CLEAR nor NEW clear the variables or Basic memory. A "POKE 129, 100" usually restores a program if there was one | - | - |
| FOR v=from TO end [STEP step] | added to parser right after LET (for speed, more frequently used statements should be parsed out first). Interpreter just gets the variable name (must be A..Z, array elements not allowed), from and end value. If STEP is not given, default of 1 is pushed on stack and then then new instruction FS is executed. | FS first checks if Vars_Next is populated. If yes, it means that this an iteration, therefore var = var + step, var > end must be executed. If no, means FOR must be set up with var = start, var > end. If FOR loop must be terminated, there are two cases: (1) pointer to NEXT exists, just go there and find first instruction after (2) pointer to NEXT is not set, so search for matching NEXT and then continue with case (1) | Added CPU instruction 0x25 (FS) - there is a Vars_For field for each variable |
| NEXT v | added to parser after FOR. Interpreter checks for presence of variable name A..Z (implicit NEXT with no variable name is not allowed) and then executes FE instruction. | FE first ensures FOR has been executed for this variable (if not, that is clearly an error), and then puts the pointer in Basic text of this NEXT statement in the Next field. Branching back to FOR is easy because Vars_For contains the line number. | Added CPU instruction 0x26 (FE), there is a Vars_Next field for each variable |
| INPUT "prompt" | Check for double quote before expression, and if found print out verbatim, then continue | - | - |
| multiple LET v=expr1, v=expr, v=expr... | Modified LET to check for presence of comma after each variable assignment, and loop if present. | - | - |
| @(index) array | Added in LET command (left side) and expression evaluation (right side). This way it appears there is one array that can be used on both sides of expressions. | New USR operations added: @(index) on left side (assign): USR(30, PrgEnd + 2* index, value) @(index) on right side (get value): USR(31, PrgEnd + 2* index) | new operation in register T to evaluate address from index |
| SIZE read-only variable | added parsing and evaluated as USR(29,...) | SIZE = Core_End - PrgEnd. value of PrgEnd is evaluated at each warm start, which Core_End (last address in RAM) is currently hard coded. | new operation on register T |
| ABS() function | added parsing and execute using already existing code path for RND() | - | - |
| % (modulo operator) | added parsing and execute through new USR(27, .., ..) call:T2 BC T3, "%" //factors separated by modulo
JS FACT
LN 27 //a % b = USR(27, a, b)
SX 1
SX 5
SX 1
SX 4 //rearrange stack so that 0x001B (USR code) is at the bottom
SX 1 //swap TOS and NOS
SX 3
SX 1
SX 2
US
BR T0
:T3 RT
| added USR(27, ...,...) which in turn uses existing div / mod routine | last step of div also corrects the sign of remainder to be same to dividend |
| THEN shortcut (If THEN is followed by integer, it is assumed to be a GOTO (e.g. IF a>b THEN 320)) | slight parser modification in IF statement | - | - |
| PEEK(address) function | invoke USR(20, address, 0):F2 BC F2ABS, "PEEK" // peek function
LN 20 // peek is usr(20, param, param), always PEEK8
JS FUNC
BR F2CONT
| - | - |
| POKE address, byte | invoke USR(24, address, byte) but discard the return value// POKE
:POKE BC RETN, "POKE"
LN 24 //POKE = usr(24, address, byte)
JS EXPR //address
BC *, "," //expect comma
JS EXPR //byte value
US
SP //drop usr() return value
NX
| - | - |
| PUSH <expression_list> | Added "PUSH" statement in the chain of recognized statements. It takes one or more comma delimited expressions and pushes their value on the stack. Typical use is to save some variables when entering a subroutine. | - | Made expression stack twice as deep (32 entries instead of 16) to accomodate for pushed data |
| POP <variable_list> | Added "POP" statement in the chain of recognized statements. It takes one or more comma delimited variable names. Typical use is to restore vars to previous values before RETURN from subroutine. | - | (see above) |
| Multiple statements on same line (colon delimiter) | Added "NC" instruction, with byte code 0x1E. It is similar to NX, but also searches for ":" character. If found, BP (basic pointer is moved to position after colon, but Lino (line number) does not change. If no colon found, same as NX | Implemented 0x1E "NC" in microcode | - |
The CPU and the microcode both support the full functionality, it is just a matter of which version of interpreter is presented to the CPU:
In the project, both are present and can be selected by flip of the switch. This can be done safely when the interpreter is in command mode, waiting for input (executing GL instruction). To differentiate, different prompt characters are used ( > original, vs. : extended)
I implemented FS (FOR start) and FE (NEXT) to leave on top of evaluation stack the line number of next instruction to be executed, which can be:
| Statement \ Case | Loop | Don't loop |
| FOR | First statement after FOR | First statement after NEXT |
| NEXT | FOR statement | First statement after NEXT |
This way, FOR/NEXT branching boils down to executing a GO instruction. Which already has the GOTO cache hooked up, so FOR / NEXT loops can benefit from caching too.
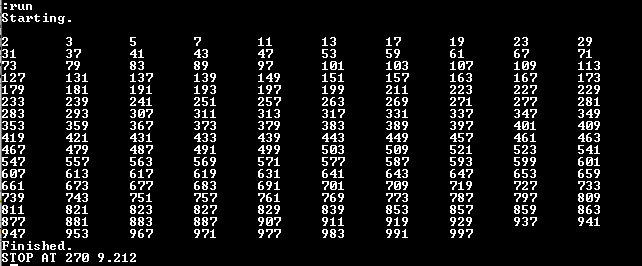
Comparing the benchmark results for Basic code on original interpreter vs. the extended, the extended runs 3% faster:
- Multiple assignments in LET save some parsing time
- FOR/NEXT instead of IF/GOTO saves parsing individual statements while still using the GOTO cache.
Extended, at 100MHz:
Original, also at 100MHz:
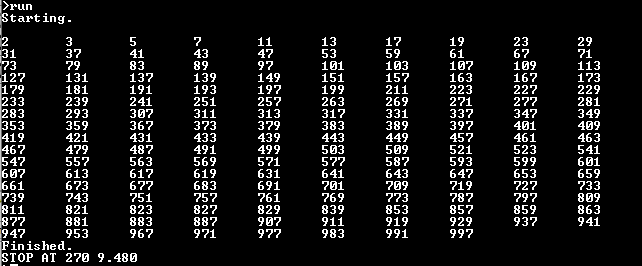
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.