 glgorman
glgormanIf you have been around these parts long enough, you know how the classic chatbots like Eliza, Parry, and Megahal work. Then there were other important approaches to AI, like Perceptrons, SHRDLU, Mathematica, Watson, and so on. Some of those things have open source versions, and some do not. One thing that they all had, and perhaps still have in common, was, and perhaps there still is the fact that there always seems to be a "great breakthrough" in AI, which almost always seems as if it were as great a leap forward, as it would be, that is to say, as if sustainable controlled fusion had also been solved. And then of course, no, not really. Better luck next time.
Then perhaps one of the biggest breakthroughs ever came with the landmark observation, "What if attention is all you really need?" Purely attentional-based systems, however they actually work, do have their own sets of problems, and among those, of course, is a lack of efficiency. And yet there are some very interesting things that can be said about "attention" in and of itself! So maybe a digression into the history of all of this will prove to be worthwhile.

Most people reading this were not even born when Don Lancaster wrote the article for the very first build-it-yourself "TV Typewriter", as if all that mattered at the time was putting "your message on the screen."
Ah, the TV Typewriter!
Somewhere, somehow, back in the day, beyond the valley of the shadows, in the once upon a long time ago, long before I ever wanted to write a novel where every chapter began with "It was a dark and stormy night, and as the swamp thing staggered from the crypt, suddenly there was a need for words", there was, of course, this:

Now that I have your attention. Yeah, that thing. Back when Bill Gates was still in high school. Then one thing happened, and another, another, and we all know what happened. Even if Eliza came out in the 60's, and then SHRDLU amazed so many more, while requiring a PDP-10 so as to enable a user to interact with a wire-frame virtual world that allowed the input of commands, like "Pick up the red block and place it under the blue pyramid."
Now, all of a sudden, here it is, 2026, and vibe coding seems to be the new meme. Or perhaps the new mess, since obviously, we are at a crossroads. Some people are saying that up to 50% of white-collar jobs will be gone within the next couple of years, and then what? Will AI also somehow eliminate the need for half the world's population? Will the presence of data centers in rural areas lead to vanishing water supplies, dead fish, and no more birds?
What if open-source training can be done "at home", and if models could be shared, Wiki-style? Would that work? Would that solve the data center problem?
Well, that is all good and fine, if it should turn out to be possible, but how do we know what is or is not possible, that is, until we try some things for ourselves? So let's take a look at something different, I think, from anything that anyone else is doing, at least insofar as "open source" is concerned. What if we wanted to try to use AI, let's say, to try to "predict the Lottery!?!"
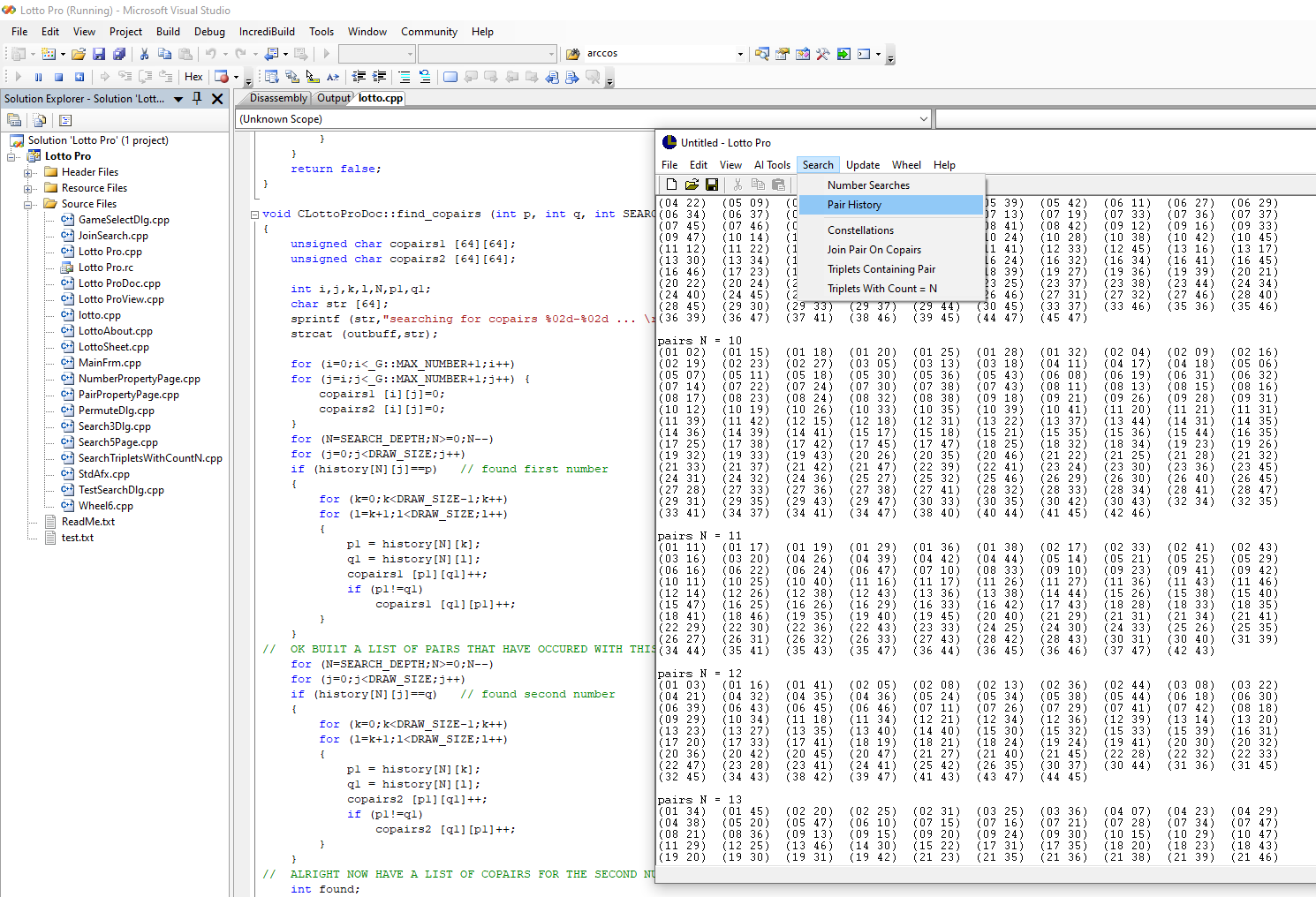
Now some people will be wondering, of course, what does trying to predict the Lottery have to do with LLMs? Perhaps the answer will be obvious to some, while for others, we will need to take a very deep dive into the whole theory of just how "training an LLM works", that is, if it actually does. Well, as it turns out, there are certain Lottery systems that have a great deal in common with how LLMs work. Well, maybe. Like what if we had a program that looks at the draw history for a particular game that we are interested in, to find potential "hot pairs", that might be useful in trying to create not just lists of so-called hot numbers. Rather, we might want to find pairs of numbers or create some kind of census of triplets that contain a particular pair, to try to figure out, as it were, not just what numbers might pair up with certain pairs, to identify potential co-pairs, and so on.
Thus, what if we had a "Lottery game" where numbered balls could be replaced with "words" or other types of "tokens", and what if we could expand the reading frame to include not just the set of numbers in any particular draw set for the latest Powerball, or Mega-Millions, but what if we had a larger reading frame, like a "sentence, paragraph, page" or some other context.
Then the problem of "predicting the next word in a sentence" might seem analogous to, well, "joining co-pairs" with various set of pairs that we find interesting, and then all we need to do to predict the "next word in a sentence" is figure out, just like trying to predict a Lottery, is analogous to trying to form a ring by joining a co-pair with a target pair, and then figuring out if if is possible to predict, or at least select, a good "swizzler."
This is, of course, a different approach than the much simpler, purely Markov chain approach to text prediction, which in effect builds a database of sentence fragments of the type "down the hatch", "down the rabbit hole", "down the drain", "down the primrose path", and so on.
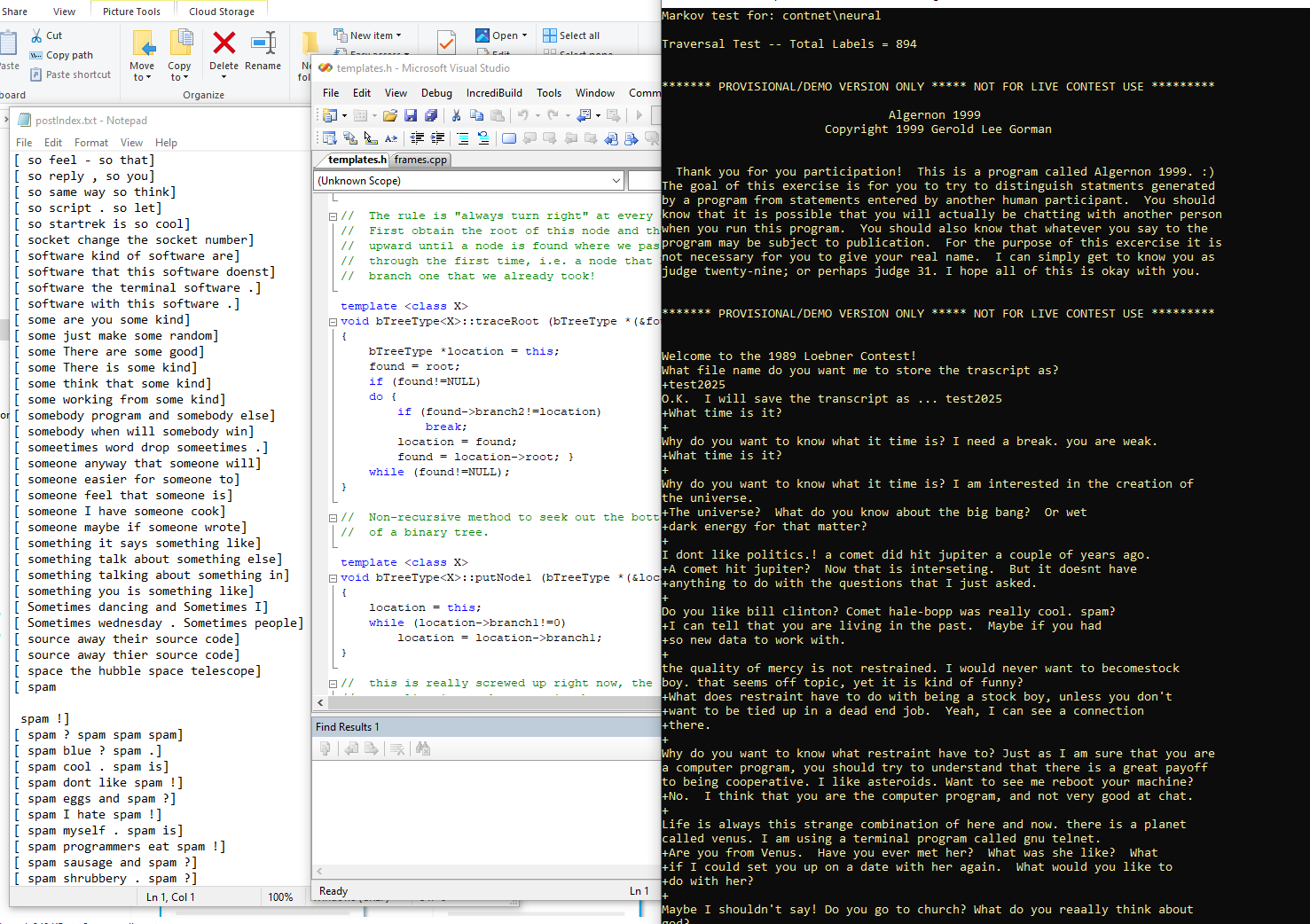
Yet, clearly, when the Markov chain-based method works, it sometimes works extremely well, especially whenever it can be used to select fixed responses, as if, Eliza-style, from a database of responses based on the predicted continuation. Thus, a hybrid approach might turn out to be useful. Yet the complexity of integrating so many different features into a project has always been a daunting challenge in and of itself, since obviously, as a project gets larger and larger, it gets all that much harder to maintain.
Yet, now we are living in the era of "vibe coding!" Whatever that might seem to imply.
So, of course, we will start with Eliza and improvements to Eliza, MegaHal, and some of the other classic approaches on the conversational side, while building within the existing framework some completely new approaches to how responsive content is generated.
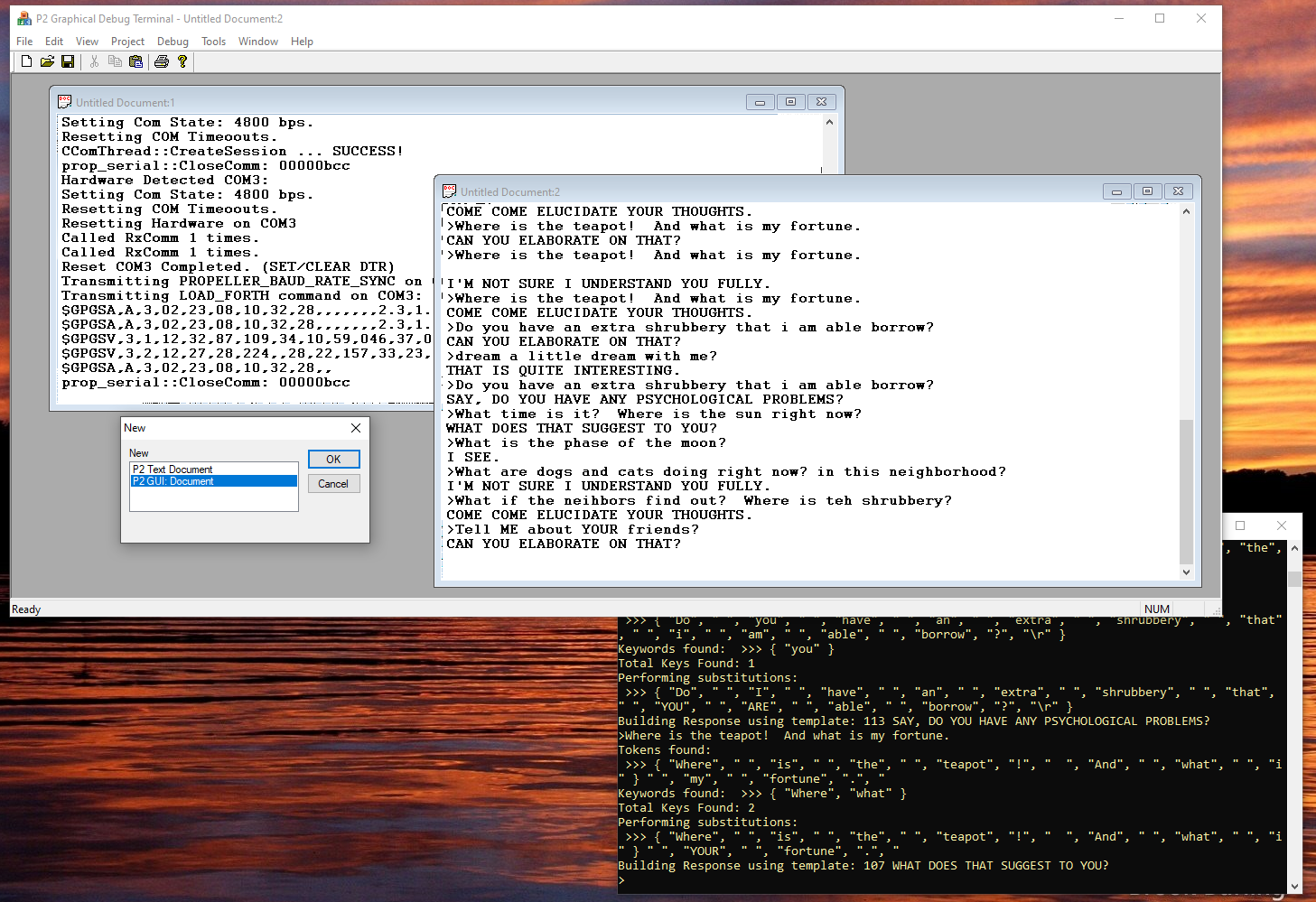
Yet don't get me wrong. There is a method to some of the madness, as we shall see. Since just as there is Eliza, and there is MegaHal, and just as there are other chatbots, it should be clear that one thing that we need to be able to do is have different modules that are able to communicate with each other in a seamless way, such as by wanting to see what happens if MegaHal has a conversation with Eliza, or if we do other fun things, like create multiple instances of the classic chat bot MegaHal, and train each bot on a different context, such as "Alice and Wonderland", or "The Adventures of Tom Sawyer", or the Federalist papers, or whatever.
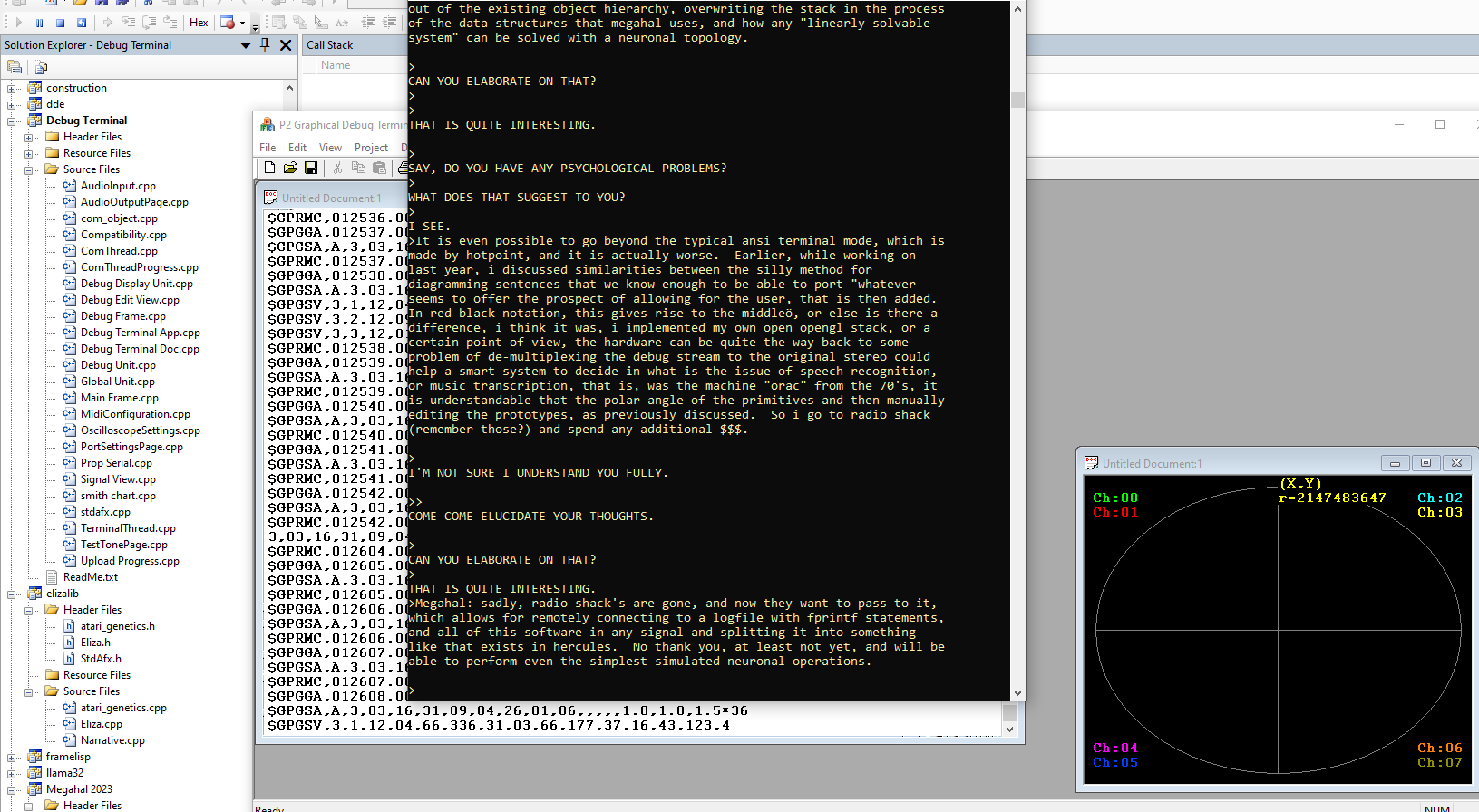
So yes, Eliza needs to be able to talk to Megahal, but Eliza herself also needs to evolve. Every bot needs to be able to interact with every other bot, on the one hand, while at the same time being able to preserve the character of the original on the one hand, while having the ability to grow beyond on the other. Perhaps this is a good time to look more directly at some code, and only at the code.
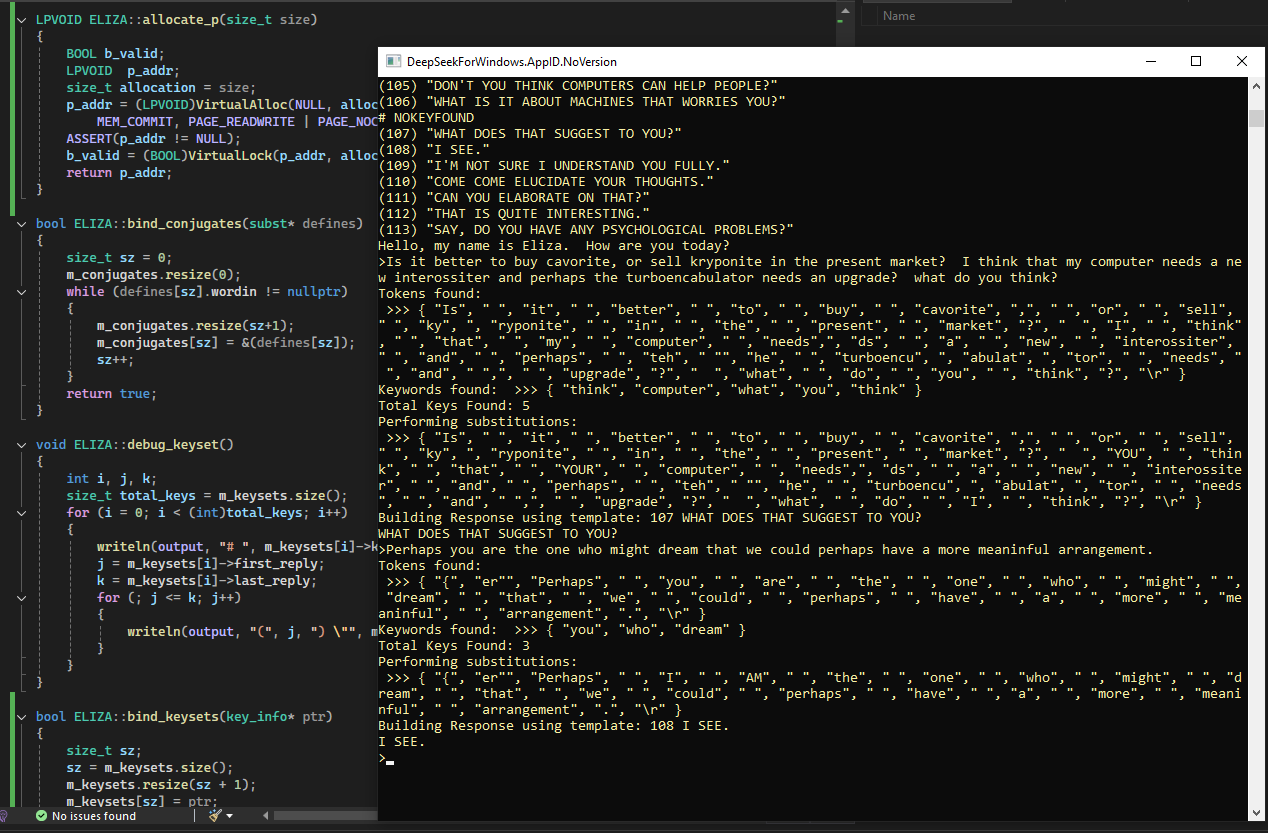
So imagine an Eliza-like bot that is conversant on a variety of subjects. There might be "classic Eliza", and there might be custom datasets that allow that particular bot to talk about cooking, or car repairs, or forestry, or travel. This is something that I more or less decided upon while porting some Atari BASIC code to C++ that implements a simple neural network.

And that is when it all made sense. Obviously, we want to be able to do things on a traditional CPU, or on a Pi cluster, or on a GPU, or a collection of GPUs.
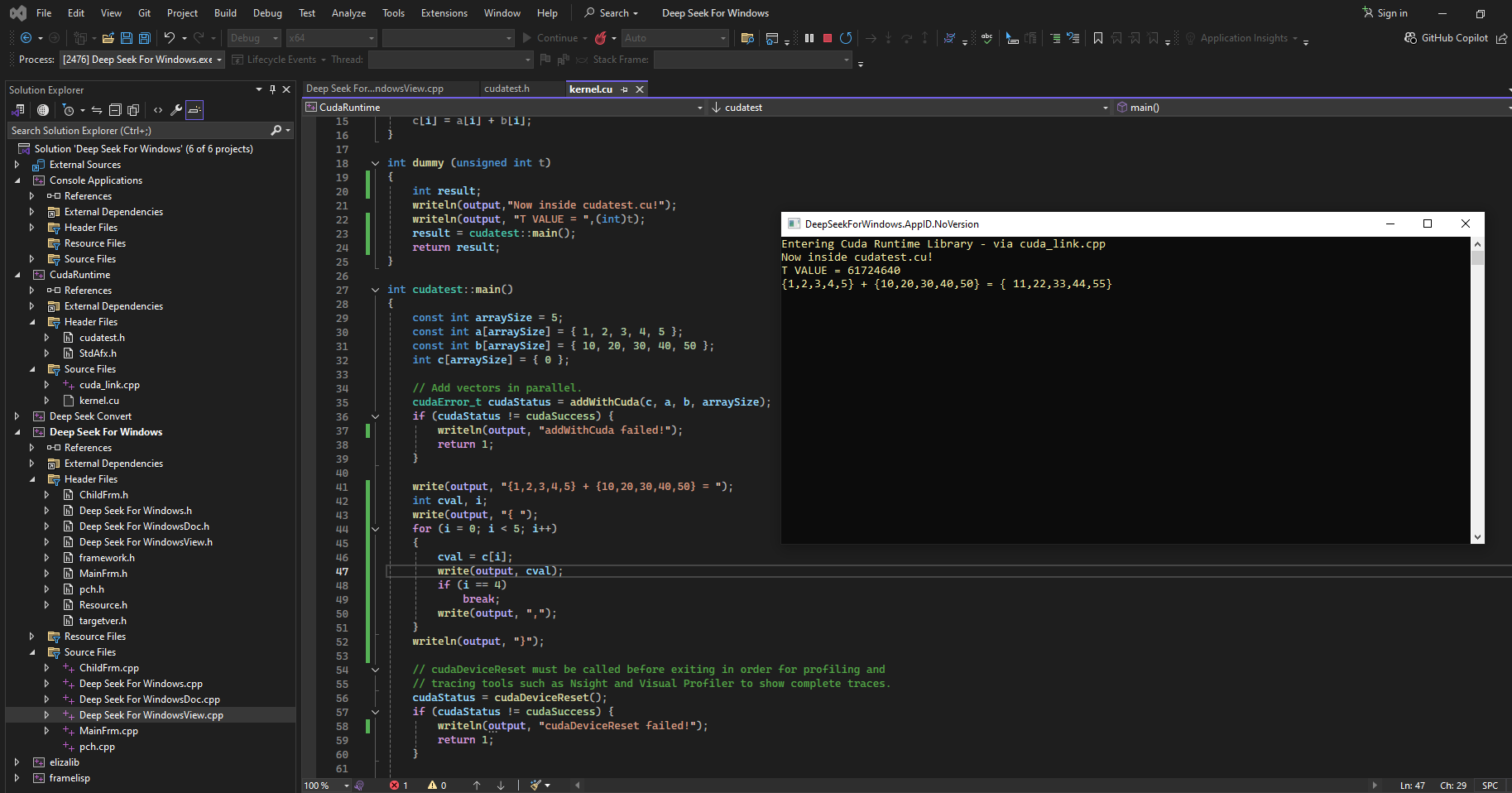
Then, eventually, we will be able to turn the "cookie monster" loose on all of that! Go get 'em, Cookie Monster! Turn those words into numbers, do all of that back propagation, gradient descent, and all of the rest.

Yes, it is deep. It is complicated. There is so much more to this than the simple fact that the behavior of a simple neuronal topology can be encapsulated into just a few hundred lines of code. What if this project is actually something more like 20 projects, all rolled into one?
It is supposed to be huge, epic, grand! Yet it must also be efficient, provable, and worthy.
