 glgorman
glgormanThe way that I figure it, what if I could write 3000 words each day, of "new material" which is somehow relevant to training an LLM, by whatever means? Then it would take "only" 333.33 days to get to one million words of hopefully, new, original, and just as important, potentially "useful" content. Yet there are other things that an LLM might be trained on, like MIDI data derived from audio input.
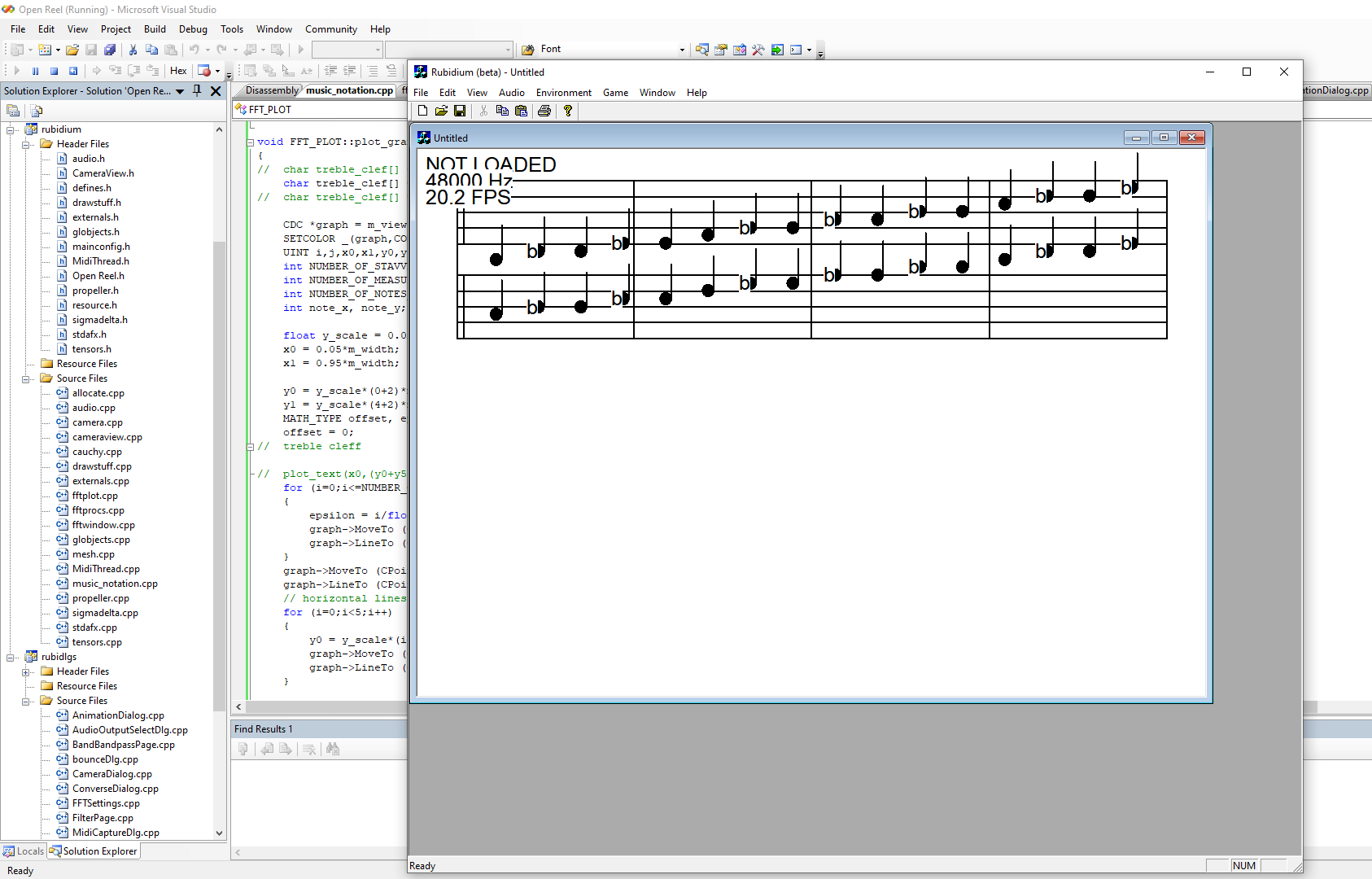
Or patterns in DNA, maybe?

I mean, why not? If it seems like a reasonable thing to try, and if the advent of vibe coding might somehow make the otherwise gargantuan task of retooling something like 100,000 lines of code, spread across at least 20 libraries, actually seem feasible. Then maybe that is yet another domain for AI, which is not only highly important, but also relevant, even if at the same time it might seem like such explorations are perhaps being underserved, at least within the Open Source community.
I know that I am going to want to be doing things with "transformers"; however, they actually work. Yet, there is also the obvious, yet seemingly all too often overlooked, task of getting the data into the program, to begin with. Maybe that isn't as hard as it might seem.
Yet there is also this idea of generating as much "metadata" as possible, maybe, based on traditional methods. Not just because it is possible to do, but because, maybe, just maybe, the transformer model would be a lot more efficient if some of the initial heavy lifting were done according to standard coding techniques.
Interestingly enough. When I took some Atari BASIC code and experimented with using a "genetic" algorithm to approximate a mathematical function, I found that I got better results if I ran 32 models in parallel, and let them compete with each other, let's say for 64 iterations each, than I was getting if I ran a single model for 2048 iterations.
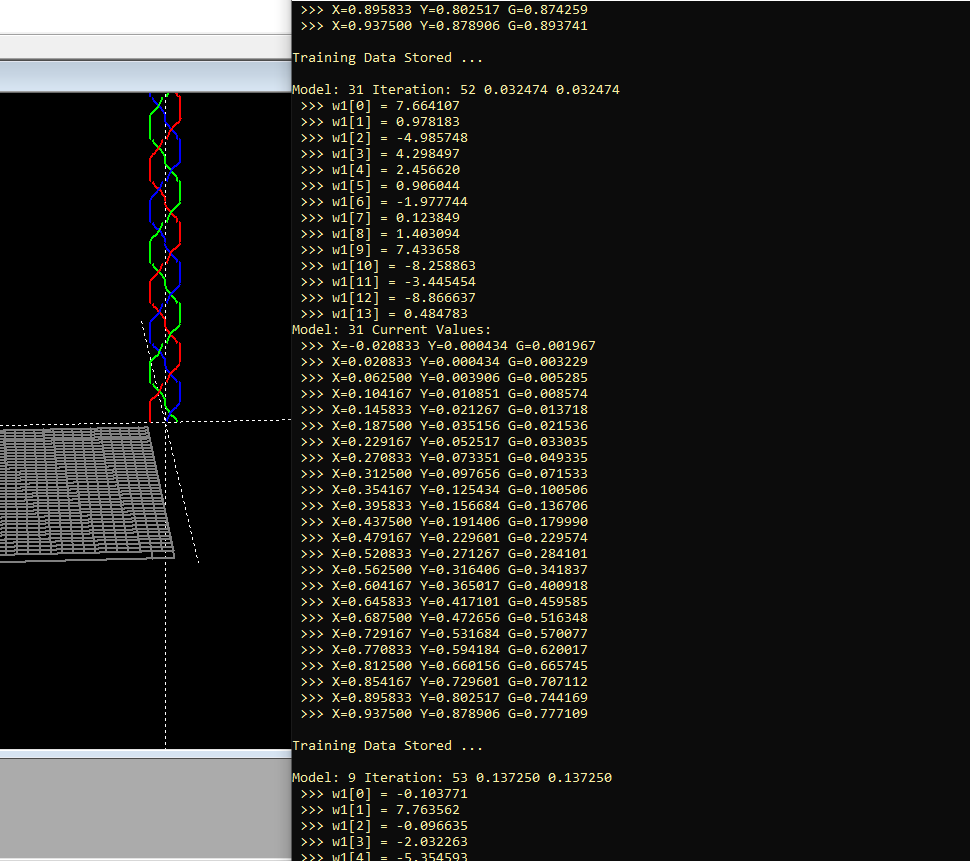
So I think that there are even more avenues that need to be explored, as far as how this sort of thing might work out in the long run. Clearly, at least in this particular case, a competition among the so called "mixture of experts", multi-model approach, seems to work best.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.