 Erik Piehl
Erik PiehlI've added a whole bunch of new functionality into the CPU core:
- All branch instructions. I had just JMP in the past, now I have:
- JLT
- JLE
- JEQ (tested)
- JHE
- JGT
- JNE (tested)
- JNC (tested - need rechecking)
- JOC (tested - need rechecking)
- JNO
- JL
- JH
- JOP
- Now the ALU supports more functionality:
- Add, Sub, Compare, and, or, and not operations
- Carry generation (needs much more testing)
- Setting of condition codes ST0 through ST4. These need much more testing and the implementation is bogus for sure.
- More convenient read and write operations in the core architecture.
- Support for the whole slew of source operand address modes (R9 used as example)
- R9 Workspace register addressing
- *R9 Workspace register indirect addressing
- *R9+ Workspace register indirect auto increment addressing
- @LABEL Direct addressing (immediate operand is memory address)
- @TABLE(R9) Indexed addressing (UNTESTED)
- Support for the whole slew of destination operand addressing mode. Some of these do not work properly, I need to add more states to handle all cases to support properly side effects
- R9 Workspace register addressing
- *R9 Workspace register indirect addressing
- *R9+ Workspace register indirect auto increment addressing BOGUS
- @LABEL Direct addressing (immediate operand is memory address) ONLY WORKS FOR MOV INSTRUCTION
- @TABLE(R9) Indexed addressing (UNTESTED, POTENTIALLY WORKS FOR MOV)
- Since the core now supports all addressing modes (although as listed above, some a bogus and some untested) I was able to add the dual operand instructions. These are mostly untested. Below are some examples.
- Move: MOV *R3+,R2
- Add: A R1,*R3
- Sub: S R2,R3
- Compare: C R2,R3 Doesn't work, flag support missing
- Or: SOC R2,R3 Untested
- And not: SZC R2,R3 Untested
The following test program runs correctly in the simulator:********** TEST 3 ** Simulation output BOOT LI R3,>8340 ** write to 8306 data 8340 1000001101000000 LI R0,>1234 ** write to 8300 data 1234 0001001000110100 LI R1,1 ** write to 8302 data 0001 0000000000000001 MOV R0,*R3 ** write to 8340 data 1234 0001001000110100 MOV *R3+,R2 ** write to 8306 data 8342 1000001101000010 * ** write to 8304 data 1234 0001001000110100 A R1,R2 ** write to 8304 data 1235 0001001000110101 MOV R2,R8 ** write to 8310 data 1235 0001001000110101 MOV R1,*R3 ** write to 8342 data 0001 0000000000000001 A R1,*R3 ** write to 8342 data 0002 0000000000000010 MOV @>4,@>8344 JMP BOOT
And below is the picture of the timing sequence of running the MOV @>4,@>8344 instruction:![]() The core does a few extra memory accesses (it reads register 0 needlessly twice) so the execution takes a whopping 6 memory reads and one memory write (IAQ signal marks opcode fetch - from yellow line onwards). Thus, despite the 100MHz clock, this instruction takes almost 500ns. I will remove the unnecessary R0 reads (that's an instruction decode artifact) later. For now I am just happy this works!
The core does a few extra memory accesses (it reads register 0 needlessly twice) so the execution takes a whopping 6 memory reads and one memory write (IAQ signal marks opcode fetch - from yellow line onwards). Thus, despite the 100MHz clock, this instruction takes almost 500ns. I will remove the unnecessary R0 reads (that's an instruction decode artifact) later. For now I am just happy this works!
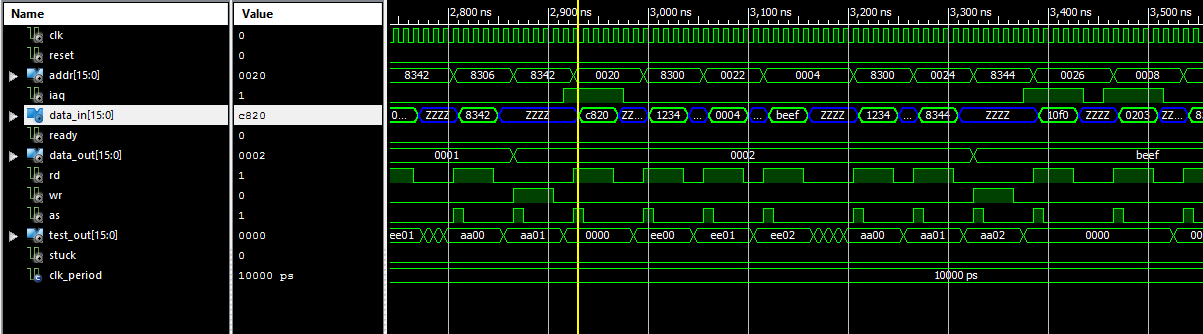 The core does a few extra memory accesses (it reads register 0 needlessly twice) so the execution takes a whopping 6 memory reads and one memory write (IAQ signal marks opcode fetch - from yellow line onwards). Thus, despite the 100MHz clock, this instruction takes almost 500ns. I will remove the unnecessary R0 reads (that's an instruction decode artifact) later. For now I am just happy this works!
The core does a few extra memory accesses (it reads register 0 needlessly twice) so the execution takes a whopping 6 memory reads and one memory write (IAQ signal marks opcode fetch - from yellow line onwards). Thus, despite the 100MHz clock, this instruction takes almost 500ns. I will remove the unnecessary R0 reads (that's an instruction decode artifact) later. For now I am just happy this works!
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.