 Manoj Kumar
Manoj KumarSpeech recognition is the process of converting an acoustic signal, captured by a microphone to a set of words. Some speech recognition systems use "training" where
an individual speaker or user reads text or isolated vocabulary into the system. Voice User Interface are included in Speech Recognition off late in all smartphones with applications like
voice dialing (e.g. "Call home"), domestic appliance control, call routing (e.g. "I would like to make a collect call") , search, simple data entry. With recent efforts in multi layer deep learning the accuracy has gone way up and is now offered as a service.
(Figure: Block diagram of typical speech recognition software)
This application is based on using the Google voice and speech API’s which google provides for free. The voice is recorded using the Microphone. Then using Google speech API’s it is converted to text. The text is compared with previously configured commands in
configuration command file. We also set several control command keywords which would control the interface. If the text matches with any of the commands, thus it performs the specific task. After finding the required commands the bash command for particular task is executed.
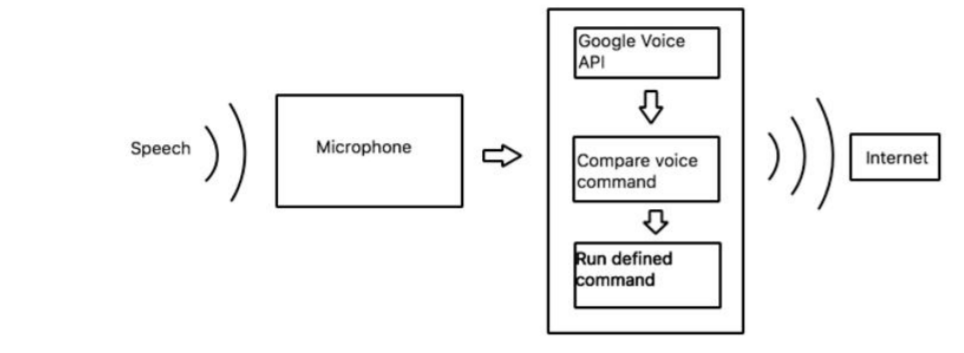 (Figure: Our implementation for the voice to text)
(Figure: Our implementation for the voice to text)To setup speech api, an account is created with the google cloud and a json file is obtained which is an authentication file. To export the authentication file the following command is used .
export GOOGLE_APPLICATION_CREDENTIALS "pathname"
export GOOGLE_APPLICATION_CREDENTIALS "pathname"
Once installation is done, recognition can be obtained by simple api calls to the cloud.
--For examples please have a look at this. ----
Since the recognition we need is a real time which is like listening to a audio and simultaneously it should be able to update. There should be some way of getting the inputs from the mic and storing it and sending it to the cloud in a proper way. To do this Pyaudio module is used.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.