0%
0%
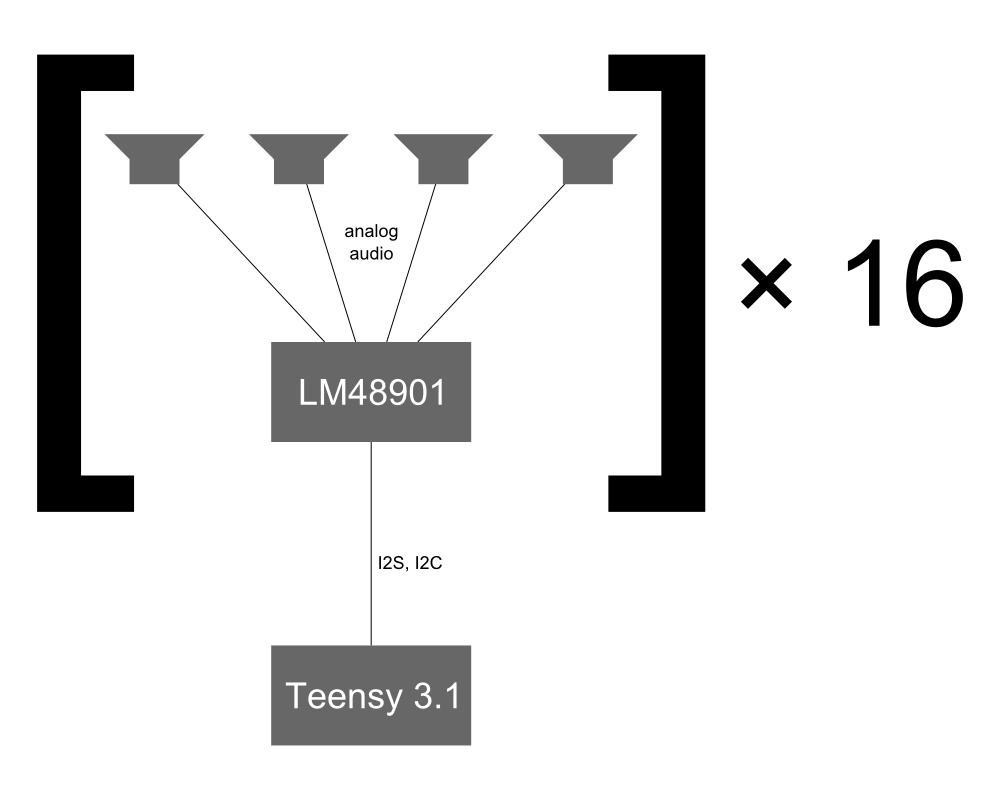
Directed Energy Precipitation Stimulation
Beam sound into the clouds to make raindrops form. Also usable as an LRAD/HyperSpike substitute, maybe.
 PointyOintment
PointyOintmentBecome a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests

 bryan.lowder
bryan.lowder
 Ben Hencke
Ben Hencke
 Chuck Glasser
Chuck Glasser