 Joshua Gruenstein
Joshua GruensteinThe Idea
The original idea behind Fido was to, well, build a robot dog. My partner and I had no real machine learning or artificial intelligence knowledge, so we did a lot of reading. After a bunch of experimentation, we tried to science-up our idea a little bit and generalize it into something actually practical. That something practical is Fido.
Background
Today, most robots are procedurally programmed. That means that for every task any robot has to perform, an "expert" has to come in and write the code for it in a traditional programming language like C++, Java, Python, Fortran, etc. What Fido does, among other things, is eliminate the expert part of the equation and allow anybody to use and train any robot to perform any task. While this may seem like a grand statement, Fido was able to successfully run on a differential drive robot, a holonomic kiwi drive robot, and a robot arm with zero code changes. And it was actually practical too: we could train Fido to follow a line faster than we could program it. We chose reinforcement as a training method as it seemed organic: reinforcement is the natural method of learning and growth, and a simple concept for anybody to understand and use.
Scientific Impact
Beyond the practical applications, Fido also represents a breakthrough in the field of reinforcement learning for robotics. Traditional systems for reinforcement learning, such as Q-Learning, take thousands of learning iterations, or pieces of reward given, to learn basic tasks. This means that robots using this system can't really be trained by humans; instead, they must be trained by other robots with infinite attention spans and perfect reward-giving skills. We came up with a few fancy upgrades to Q-Learning that allow it to learn 3 times faster and 4 times better, even in noisy real world environments. This represents a fundemental shift in reinforcement learning for robotics: Fido actually makes the whole "humans training robots" deal practical. And beyond robotics and machine learning, this is a step towards a general intelligence. If we learn through reinforcement using constructs such as pain and enjoyment, who's to say that Fido doesn't feel the same way?
How We Built It
First, all of our work is open source under the MIT license and released on Github. We used git throughout our development process, so you can track our progress over the last few months. The codebase ended up being quite large, as to make Fido practical on embedded systems we had to write all of the machine learning constructs ourselves in C++. While this certainly took a lot of time and understanding, it ended up being super great for a few reasons.
First, we were able to make optimizations throughout the entire algorithm that gave us practically no noticeable latency, even while running on lower power devices like the Pi Zero. Second, we ended up having a lot of "left over code," stuff like genetic algorithms that we experimented with, but didn't actually end up in the AI. We decided to re-organize our repo as a general purpose open source C++ machine learning library for embedded electronics and robotics, and have been enjoying seeing Fido's popularity rise. We're proud to say that Fido now has over 300 stars on Github, and we've appreciated contributions from the open source community all across the country.
Implementation Details
The Fido project overall roughly broke down into two categories: the learning algorithm, and the hardware implementations. We'll be getting into the nitty gritty on both of these subjects in our build logs, but we'll summarize here.
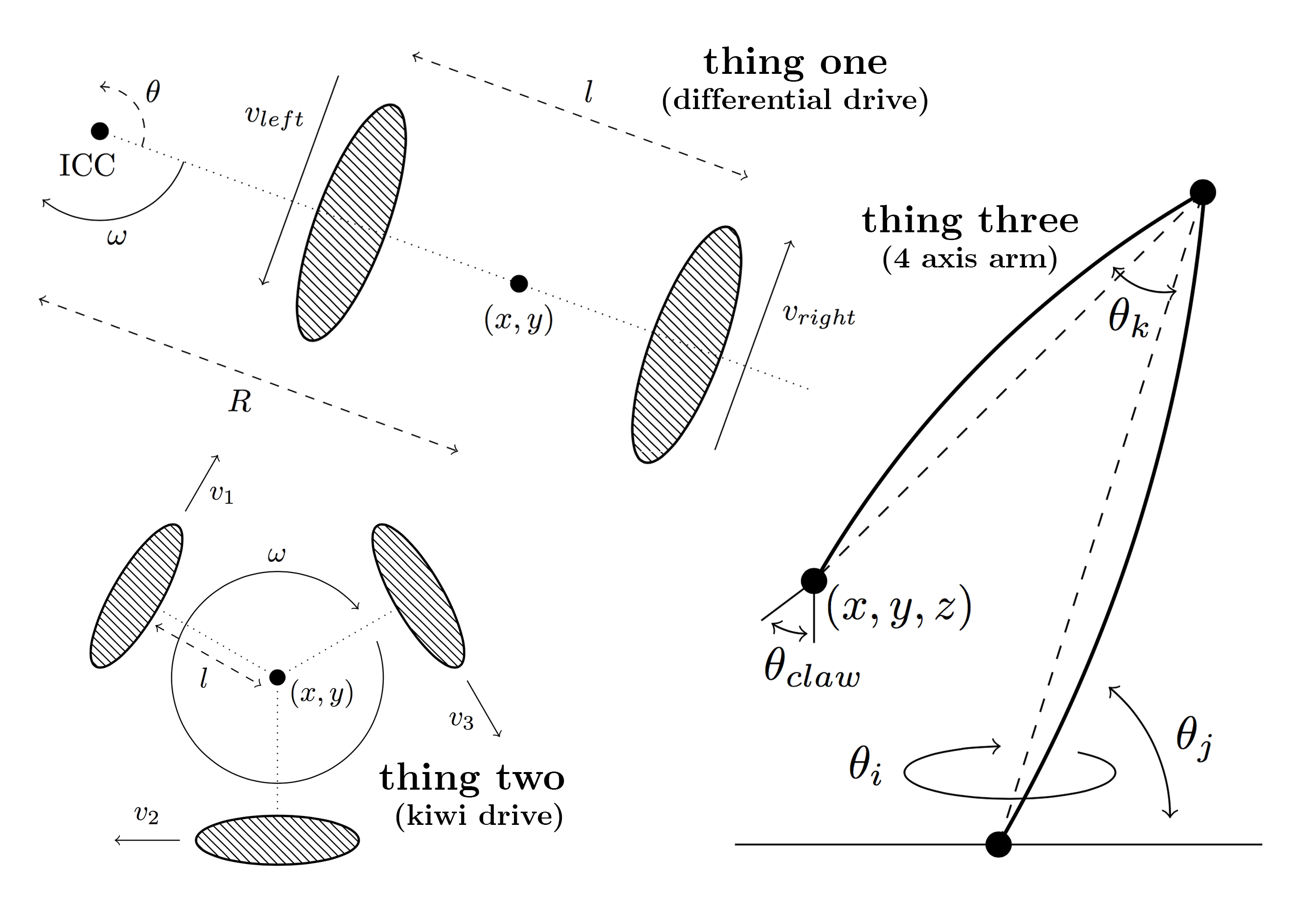
We programmed the AI in C++ with no external dependencies, writing the entire project from scratch (over 5000 lines of C++). Next, we built three robots and a simulator to test the algorithm. The first robot, nicknamed "Thing One," has a 3D printed chassis (designed in AutoCAD student), uses a differential drive system, and is powered an Intel Edison for computation. After constructing Thing One,...
Read more »


 Pascal Buerger
Pascal Buerger

 prateekt
prateekt
 shamylmansoor
shamylmansoor
"An AI that lets any robot learn through positive and negative feedback."
Once this project goes to Hackaday blog, you'll receive a lot of negative feedback, I guess. That's how the community works.
Nice project, by the way.