I wanted Deep Synth to be polyphonic. So I started planning how to share voices among notes. My goals:
one note is replicated across six octaves, as in the mono synth.
as notes are added, some voices move to the new notes. Some voices should move up, and some should move down. (the wandering oscillator effect). The voices should stay distributed across the six octave range.
no notes let the voices drift back to the chaotic buzzing pattern.
Let me explain the wandering oscillator effect. Deep Synth should have no lowest note, so it assigns voices in a pseudo-Shepard tone way. No note should be strictly lower or higher than any other note; the oscillators should be moving both up and down on every transition. I went into more detail in the previous post.
Again, I prototyped it in Jupyter notebook. Actually, you can see that I'm using exactly the same code to assign voices to notes. That's because I'm fudging: I backported the new algorithm into the mono simulation to ensure it still works there. I don't actually have a record of my Jupyter notebook before polyphony worked.
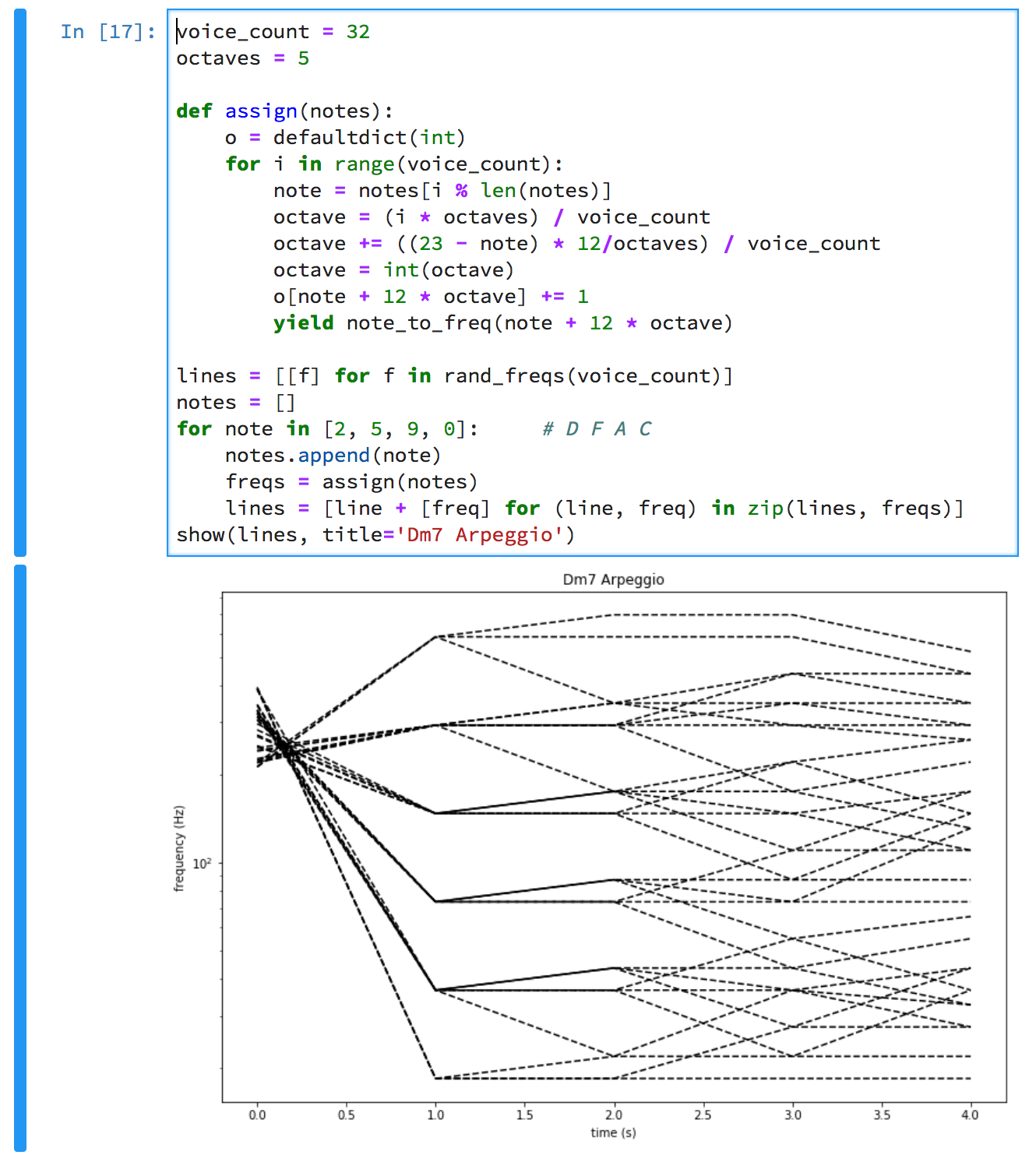
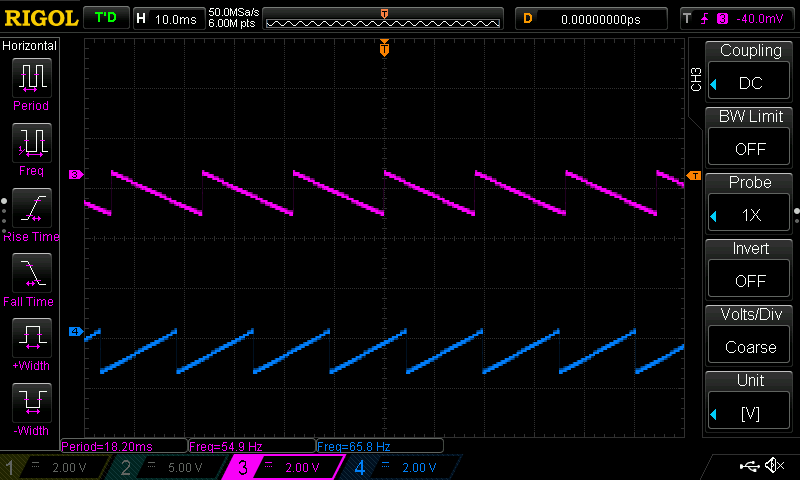
The graph shows the notes of a D minor 7th chord being added one at a time. At t=0, the voices are buzzing chaotically. At t=1, they are playing D in six octaves. Then F is added, and At t=2, half the voices have moved to F. At t=3, the voices have redistributed to D, F, A. And finally at t=4, we have the whole chord: D, F, A, C.
You can see that at each transition, voices are sliding both up and down.
There are 20 different notes in the final chord! It's a deep chord [sic]. The magic of Shepard tones is that there is no definite bottom note. This chord is root and all three inversions, open and closed voicing, all at once.
Voice Transitions
But it still wasn't right.
It's easy to say, "voice should slide from this frequency to that". But the way it slides is also important. After trying several things, I decided I wanted these properties:
When moving between notes, voices should ignore the chaotic buzzing frequency.
When notes are changing quickly, voices should move quickly.
When notes change before a voice has finished moving, it should start toward its new destination immediately and start moving faster
Voice "blurring" (resuming chaotic buzzing) should start imperceptibly, then get faster.
Voices may start blurring before they're fully focused on a note. And vice versa.
I eventually came up with this mental model.
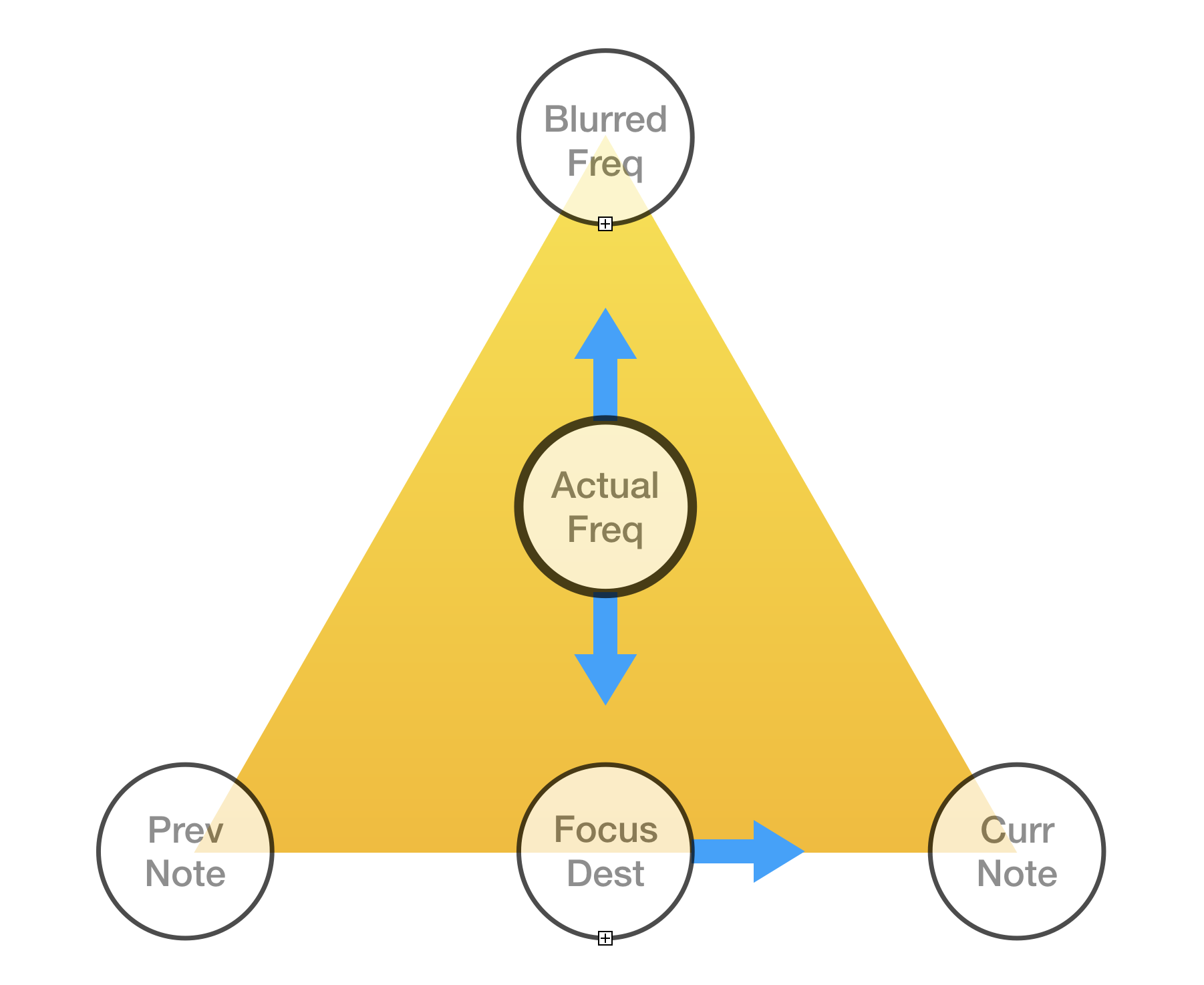
The voice's frequency is within the triangle. When the voice is focusing (moving toward a note because at least one note is triggered), the voice is moving toward the focus destination. Otherwise it is moving toward the blurred frequency. The focus destination is gradually moving from the previous note to the current note.
Here is the code to do that calculation. `sweeper_interpolate` interpolates between 0 and 1 along an exponential curve; see below.
When the voice is assigned to a new note, Curr Note is set to the new note's frequency. If the focused destination had reached the previous note, Prev Note is set to the previous note's frequency. Otherwise, Prev Note is calculated so that Focus Dest does not have to change, either in its distance from Curr Note or its frequency.
That's not a very good explanation. Here's the relevant source.
I wrote a "class" called `sweeper` that interpolates along an exponential curve. It's designed to be fast to calculate and easy to use.
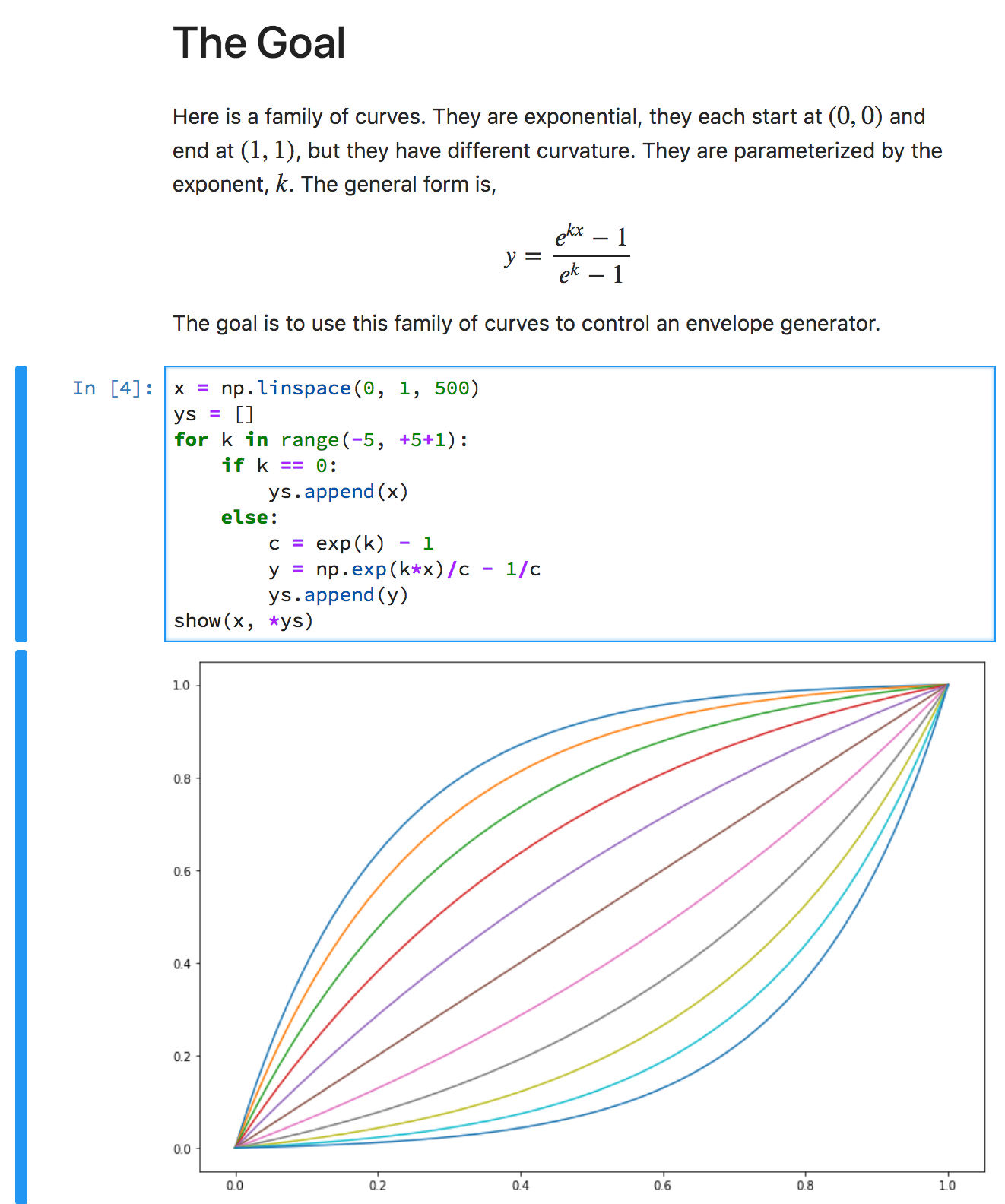
I made another Jupyter notebook to understand exponential curves. (I love Jupyter notebooks. They are great if you think visually.) This one has explanatory text, so I'll just paste it verbatim.
It's a nice curve. You can start out slow and get faster, or start fast and slow down, and that's independent of the total time or distance. You can scale x and y to the actual time and distance needed.
And it's fast. Here is the code to increment position along the curve. (`sstate` points to the sweeper's mutable data.)
I had some ideas about Deep Synth. I wanted to be able to play several different notes, and I had the idea that after a note, the sound should revert to chaotic buzzing.
At first, Deep Synth was monophonic -- whichever note was triggered last was the note to play. On a Note On event, each oscillator's target frequency would be set to the note's frequency in one of several octaves. The code on Earslap distributed the oscillators across six octaves. Then the frequency would drift toward that note over several seconds.
There are ten buttons on the 1UP's gamepad. Which buttons should trigger which notes? Eventually, I realized you can sort of conceptualize the buttons as being in the shape of a piano keyboard. (See below.)
I also thought it might be fun to have the octaves weighted as pseudo-Shepard tones. That way there wouldn't be a single deepest note.
It would be good to have a full 12 note chromatic scale with Shepard tones, then Deep Synth could play "all" notes. (All notes that lie on the chromatic scale, that is. Exotic tunings need not apply.)
So I needed two more buttons, and I settled on the volume buttons. The new audio output section doesn't use them, so they are available, just inconveniently placed.
So this is how I mapped the chromatic scale onto the gamepad. Several months later, I've fooled myself into thinking this is a natural layout.
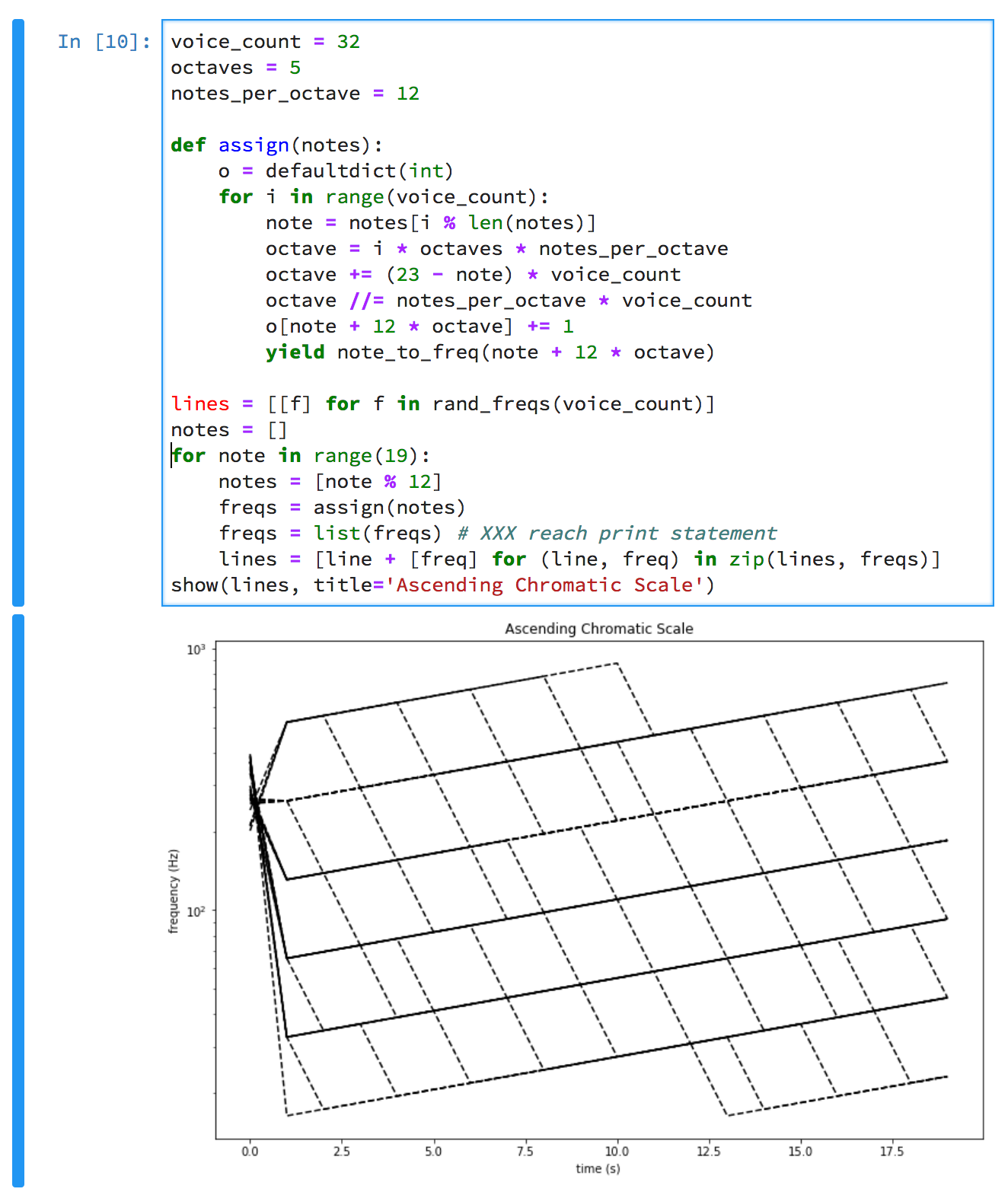
I also imagined it would be interesting to have individual oscillators wandering around a bit when notes changed. So I made it so that on every half step, most oscillators would move up, but a few would move down an octave. This would be the basis of the Shepard tones.
I prototyped an algorithm in a Jupyter notebook. The graph shows how the oscillators move when playing a 19 note ascending chromatic scale. At each step, one or more oscillators drop down an octave. And you can see that the pseudo-Shepard weighting is maintained. The octave assignment code was heuristically created -- there's no deep theory there.
The next question was, what happens when a note is released? I went through several iterations on this code. It will get trickier when Deep Synth becomes polyphonic (foreshadowing!) but for the mono synth, it's pretty straightforward. The chaotic buzzing frequencies are always generated, but when the oscillators are focused on a note, the buzz frequencies are ignored. When the note is released, the frequencies gradually start drifting back. I made the drift start very slowly -- it takes a second or so to realize the note is dissolving. I like the effect, but it is definitely an acquired taste.
Finally, the first note takes several seconds to focus, but it's hard to play an instrument that's always that laggy. So if you trigger a new note before the previous note has completely defocused, the new note focuses faster.
To make a synth that sounds like Deep Note, first I need to understand Deep Note. Fortunately, Batuhan Bozkurt has analyzed Deep Note and has published a good approximation of the sound. Unfortunately, he used a synthesis language called SuperCollider. I didn't know anything about SuperCollider.
SuperCollider is a declarative programming language for describing audio processing engines. Its basic numeric type is a tensor, much like APL and NumPy. It has high level primitives like oscillator, filter, envelope generator, etc.
But SuperCollider is open source, so it's easy enough to extract the relevant algorithms. "Easy enough" in this context means a week or two of learning SuperCollider concepts, grepping through code, exploring blind alleys. Free Software is both free as in freedom and free as in all your free time.
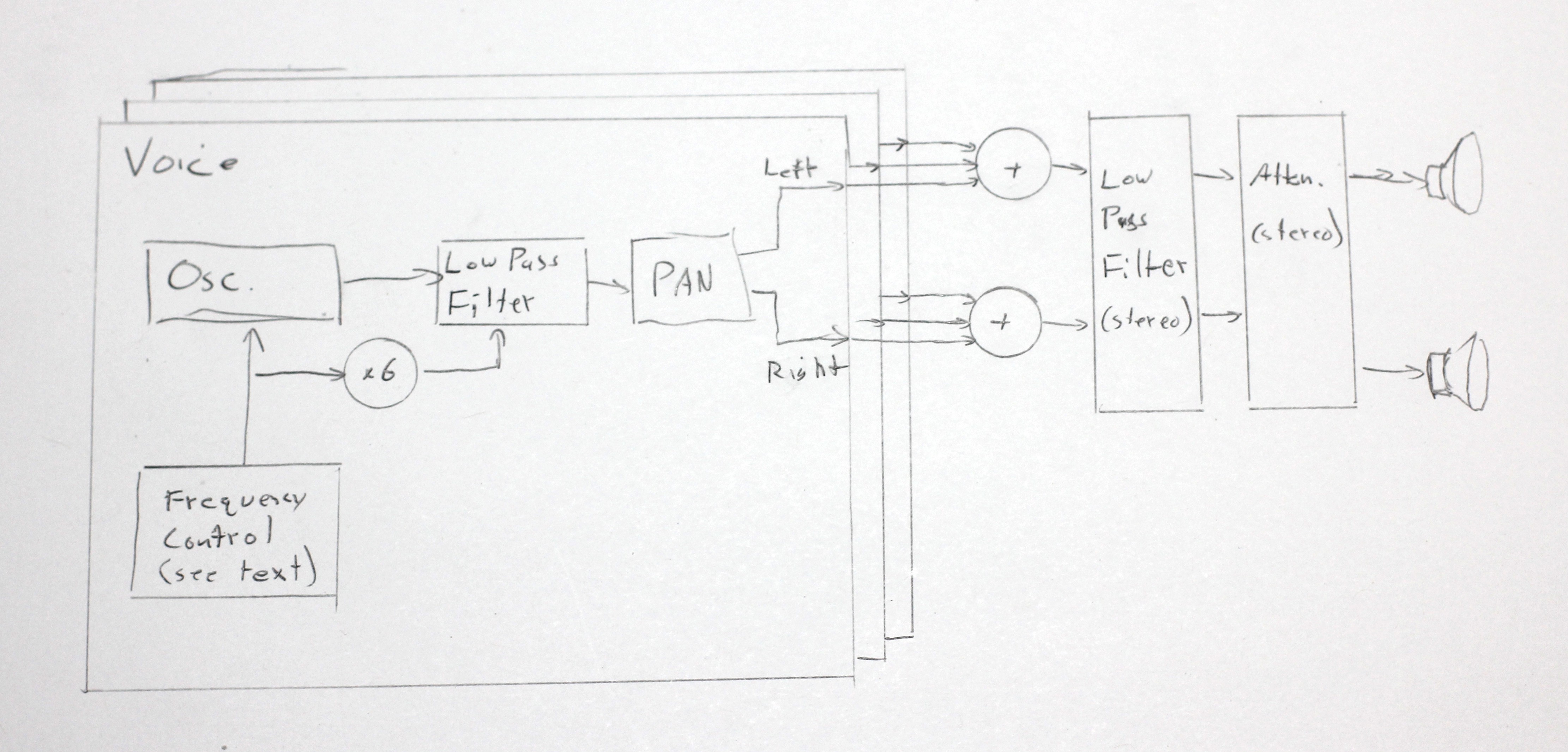
The overall architecture is like this. There are 32 voices. Each voice is a sawtooth oscillator, a low pass filter, and a panner. Each osc. starts out randomly drifting between 200 and 400 Hz, then as the voices converge to the big chord, it sweeps toward its place in the chord. The filter tracks the oscillator's frequency, with its cutoff frequency six times higher. The panner puts the oscillator at a fixed, random position between the stereo channels.
All voices are mixed together, then the mix is low pass filtered and attenuated. The global filter starts at 2KHz, and gradually opens up to 20KHz. The global attenuator starts at zero, then opens up over a 12 second period.
So I reimplemented it in C. At first, I just ran it on my Mac -- the edit-compile-test cycle is faster there. Then I ported the C code to the 1UP.
SuperCollider uses 2nd order biquad filters. I started out with those, then switched to state variable filters. The SVFs are more efficient when the cutoff frequency is changing. These filters' cutoffs are always changing.
Note: I know nothing about DSP. Whenever I say something like "biquad filter", you may safely assume that I'm just parroting something I read somewhere. I wouldn't know an actual biquad filter from my own grandmother. But I can read code, so if I see code purporting to be a biquad filter, I can analyze and transform it as code.
One thing I never did figure out was SuperCollider's sawtooth oscillator. It appears to be a perfectly bandlimited sawtooth (as opposed to a filtered one) created as the ratio of two sine waves, integrated. The denominator is the oscillator's fundamental frequency, and the numerator is the highest odd harmonic below the Nyquist frequency. But that makes no sense to me. I tried for too long to extract working code from SuperCollider, but failed.
I ended up using an aliased sawtooth oscillator instead. Sorry. The low pass filter removes most of the aliasing, and the limited bit depth gets most of the rest.
So that's Deep Note analyzed and implemented. The next challenge is to make something that plays more than one note.
The Deep Synth project grew out of the 1Bitsy-1UP project. So let me tell you about the 1UP and its audio section.
The 1Bitsy is based on an STM32F415 chip, which has three I²S peripherals. Unfortunately, due to pin conflicts, the 1UP can't use those.
Instead, the 1UP uses the STM32's two channel DAC for stereo audio output. The DAC has 12 bit resolution. Since the 1UP is an homage to the Game Boy, we thought 12 bit was probably good enough for bleeps and boops.
So I wrote an audio driver and a test application.
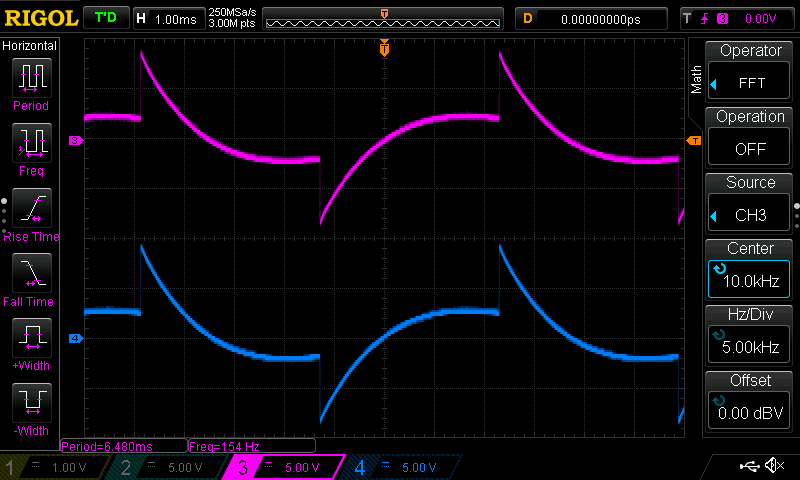
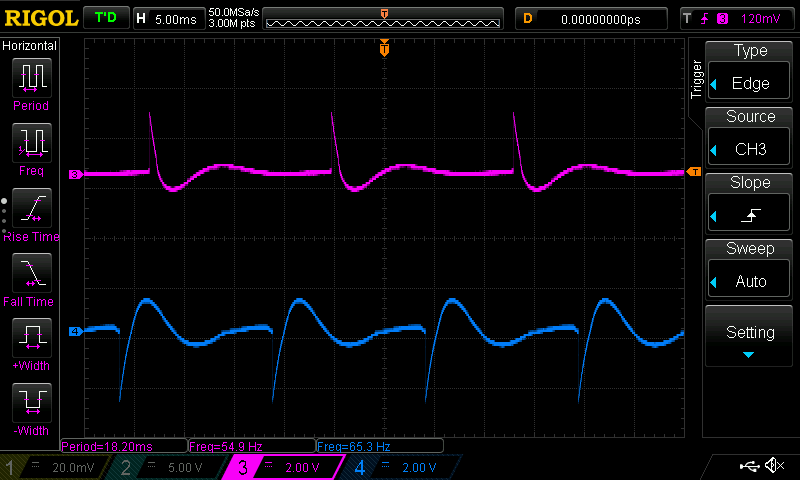
When I looked at the audio on an oscilloscope, though, it didn't look good. Here's a square wave. The left channel is above the right.
And here are two sawteeth. 55Hz on the left, 65Hz with opposite polarity on the right.
So we looked at the circuit. (We means @esden, J—, and @scanlime.) There were a couple of problems. The DACs fed an RC high pass filter, and from there went into a digital potentiometer (Microchip MCP4661). The digipot wiper fed a headphone amp (TI TPA6135A2). We identified a couple of issues.
The RC time constant was too high.
The digipot's power rails were 0V and +3.3V. The audio signal was dipping below 0V, sending the pot into uncharted territory.
The digipot has linear taper, and audio attenuation should use a log taper.
So we reworked the board to move the high pass filter downstream of the digipot. And then the headphone jacks started breaking off.
So I started designing the new audio output section using the PAM8019 from Diodes Incorporated. It would have a through hole headphone jack and a volume potentiometer. I made a new board that would attach to the 1UP in some unspecified way.
My first thought was to sandwich the audio board between the 1Bitsy and the 1UP. I got this far in the design.
That was not the answer. The routing was a mess. I used SMT passives, but paired each with a set of through holes to replace the passive if testing showed it was the wrong value. (I am not (yet) very good at soldering SMT, and I'm not keen on SMT rework at all. And the PAM8019 datasheet had left me with several questions about component values.) And how could you replace components if the audio board was under the 1Bitsy?
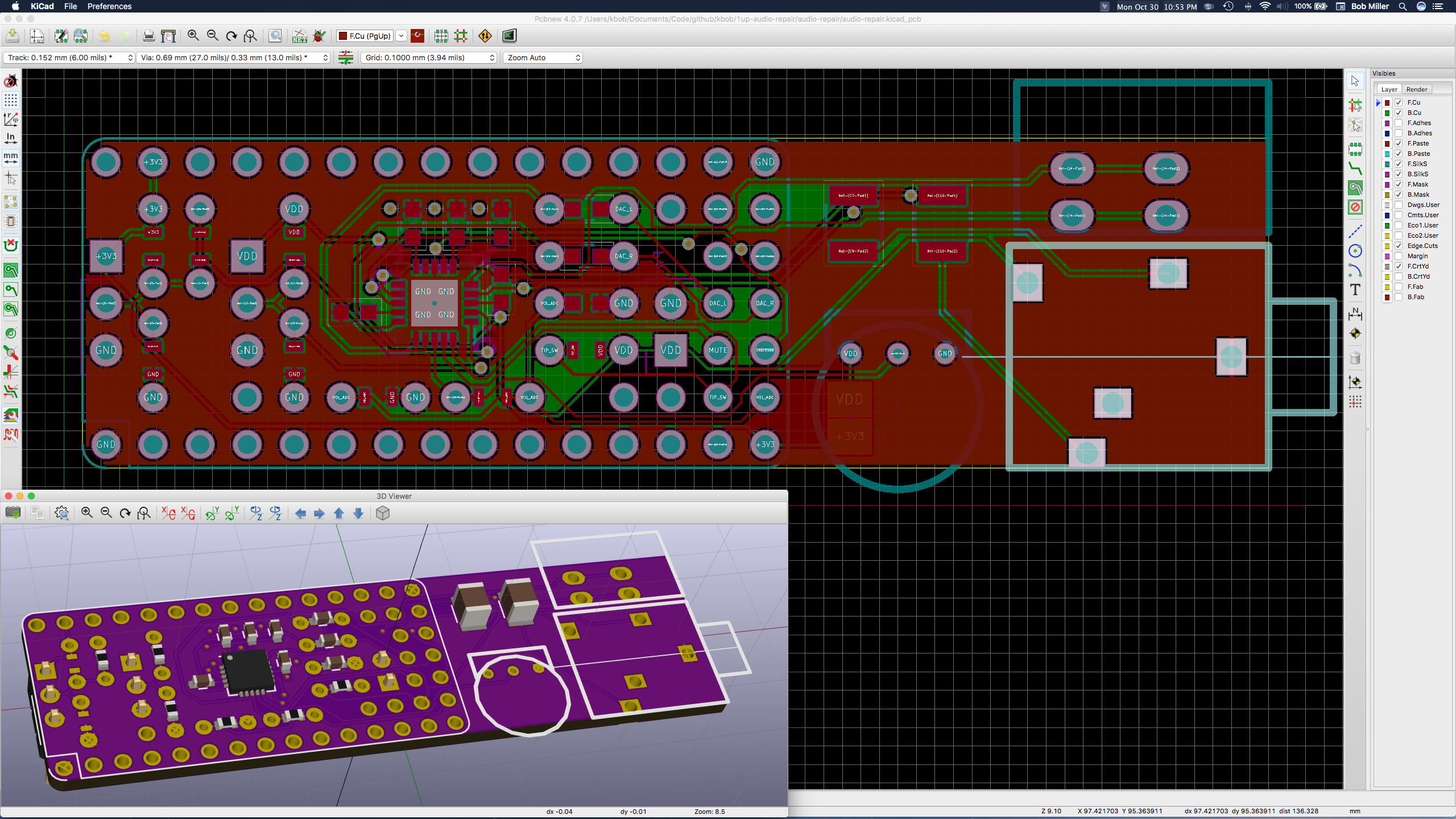
So I backed up and designed a board that would not fit the 1UP but would let me test components. Here is the second board, V0.2, after it was debugged.
The jumpers in the lower left allow switching between regulated 3.3V and battery power. The two jumper blocks at the top allow bypassing voltage dividers, shorting a pin directly to +V or GND.
The rework corrects a bug in the headphone sense circuit.
There are two speaker jacks -- we only want mono, but stereo is available on this revision.
Then I spent an afternoon measuring different values for the voltage dividers. One of them was replaced by a jumper to ground, and the under voltage protection got values that shut off the amplifier power just before the STM32 shut down.
So it was time for a new board. Here is board number 3. It solders onto the top of the 1Bitsy. I made three of them, and they all worked.
 Bob Miller
Bob Miller