lion mclionhead
lion mclionhead-
Qualcomm adreno options
10/19/2025 at 03:27 • 0 commentsProgress has moved on since the Jetson Nanos. The lion kingdom's $150 Jetson Nano had .25 TFLOPS in 32 bit float. That gave it 6FPS with a pure C++ implementation. Modern $250 jetson orin nanos have 8 TFLOPS in 32 bit float. Modern, sub $100 phones have over .4 TFLOPS in 32 bit float which is just enough. The trick is they can't run CUDA or CUDNN. The world is rapidly dropping CUDA because of the high cost.
The largest repository of adreno examples might be openpilot. The models are in ONNX format.
https://github.com/commaai/openpilot/blob/master/selfdrive/modeld/models/
It uses tinygrad & opencl as the backend. 16 float seems to be a waste for this application. 32 bit float gives better results.
There might already be an openpose for android.
------------------------------------------------------------------------------------------
The lion kingdom got a 5Ghz wifi dongle for the jetson nano but it seems to have inferred its last image. The phone app could use optimization with the BufferedStream class, too.
An on camera flash is needed. The godox doesn't wake up without the full ID signal, so it had to be constantly power cycled. Usage in a model session would require the wireless system or adjusting the timeout, risking its unreliable persistent settings. A smaller flash might be the only way. Recovering the 580EX II would require a donor flash.
-
Pose estimation with the raspberry pi 5
04/06/2024 at 08:01 • 0 commentsIt seems the raspberry pi 5 is making tensorflow-lite on the CPU a viable alternative to tensorrt on the GPU. They're claming 3x faster inference speeds than the rasp 4, which would make 8 bit int on the rasp 5 equivalent to FP16 on the jetson nano. FP16 on the jetson nano was generally 3x faster than 8 bits on the rasp 4.
As for porting body_25 to 8 bits, the rasp 5 would probably run it at a slightly lower speed that it runs in the jetson nano, 6.5fps with a 256x144 network. It would have to use the CPU for a lot of post processing that the jetson does on the GPU. It would not be worth porting.
The lion kingdom only paid for the 4 gig rasp, since it only has 2 possible jobs & a USB swap space proved viable on the jetson. It took a long time to finally do the deal, since the jetson nano was so expensive.
https://www.tensorflow.org/lite/examples/pose_estimation/overview
Looking at the top 8 bit pose estimator, MoveNet.Thunder, it should hit at least 11fps on the rasp 5 with all the post processing, maybe 12fps with overclocking. Helas, it only supports 1 animal. It might be viable for rep counting. The rep counter of the last 6 years has been a 256x256 body_25 at 12fps.
The notes for movenet on the rasp 4 were
https://hackaday.io/project/162944/log/202923-faster-pose-tracker
The biggest multi animal network is movenet_multipose_lightning. movenet_multipose lighting FP16 would probably hit 9fps on the rasp 5. Overclocking it to 10fps seems attainable.
---------------------------------------------------------------------------------------------------
The pose estimator tests were using tensorflow for python. This required a totally different installation than the C libraries.
Installing tensorflow for python had a new twist. They no longer allow 3rd party python modules in the root directories. You have to make a virtual environment.
root@truckcam:/root% mkdir venv root@truckcam:/root% python3 -m venv venv
Activate the virtual environment:
root@truckcam:/root% source venv/bin/activate
Install the libraries:
root@truckcam:/root% pip3 install tensorflow
pip3 install opencv-python
apt install libgl1
The trick with python is it can't read from the fisheye keychain cam. It only works with a standard webcam. The past work used a 640x480 webcam.
The next step after installing tensorflow was downloading the demo program.
git clone https://github.com/ecd1012/rpi_pose_estimation
This one used the following model:
The invocation was
python3 run_pose_estimation.py --modeldir posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite --output_path pose_images
Something got this guy hung up on requiring a GPIO library, physical button & LED. Lions just commented out all that code & hacked a few more bits to get it to save more than 1 image. This model hit 16fps but was really bad. Mobilenet V1 was the 1st clue.
The one which uses movenet_multipose_lightning is
https://github.com/tensorflow/examples/tree/master/lite/examples/pose_estimation/raspberry_pi
Download this directory with a github downloader program. Then rename it posenet. Run setup.sh Helas, this one seems to use a variant of opencv which fails to compile on the rasp 5. Trying to run it with the cv2 package that worked in rpi_pose_estimation dies with Could not load the Qt platform plugin "xcb" The easiest way to run this one is to make a C program.After many iterations, the 2D & 1D tracking programs for the raspberry pi all ended up inside
https://github.com/heroineworshiper/truckcam/truckflow.c
The android app for controlling it ended up inside
https://github.com/heroineworshiper/truckcam/
There seems to be no way around endlessly copying the same code around because of the battle between many models with different infrastructure needs. The latest feeling is instead of manetaining status bits, these programs should send print statements to the phone. There are too many problems with the webcams & no-one is ever going to use this who doesn't know the source code. Raw console output would require a streaming protocol, repetition of the error messages, or a counter indicating something was lost.
---------------------------------------------------------------------------------------------------------------------------------------------------------------
movenet_multipose.tflite has a dynamic size which must be set with ResizeInputTensor. At 256x256, it goes at 17fps on the rasp 5. At 320x320 it goes at 11fps & is much better. Any higher than 320 crashes it. It's hard coded to detect 6 animals.
It's so much faster than the rasp 4, it's amazing they're still using repurposed set top box chips. Smart TV's weren't exactly known for feeds & speeds. Everything might have just gotten pushed against the top end, since the top end couldn't go any faster.
![]()
![]()
On a test photo, it was highly dependent on threshold values for animals & body parts.
On lion footage, it was a steaming pile of dog turd. Some key advantages of body25 on the jetson nano were detection with most of the body out of frame, detection from behind, fewer missed hits.
In a direct comparison, body 25 at 8fps, 255x144 still outdid movenet at 11fps, 320x320. It seems movenet requires using efficientdet 1st to get hit boxes & then applying movenet to the hit boxes. It might require square tiles too. That doesn't work well for 2 overlapping bodies in horizontal positions.
Looks like body25 on the jetson nano is still the best option for the 2 animal 2D tracking while the rasp 5 is going to be limited to 1D tracking of a single lion. The 16 bit floating point on the jetson is still superior to higher resolution 8 bit. If only customized efficientdets worked on it.
It's possible that body25 could run faster & at higher resolution on the rasp 5 in 8 bit mode but the mane limitation is time. The current solution works.![]()
It shall not die.
-
Commercial progress
07/06/2023 at 17:57 • 0 comments5 years after lions got serious about this project, OBSBOT is knocking it out of the park, in a sense. They're all still based on face tracking. The best ones still are required by law to use indigenous Chinese cameras with horrendous light sensitivity. They would still have a hard time with 2 animals with obstructed faces in unusual positions. Their face trackers are hitting high frame rates, allowing fast movement to be tracked.
The lion kingdom still hasn't had enough money or time to use the tracker for its intended purpose, since building the jetson nano system.
The other project requires tracking 1 animal in a crowd while being mounted on a small vehicle. The obsbot would be no use there.
-
How to fix USB on the jetson nano
04/13/2023 at 18:33 • 0 commentsIt became clear that USB on the jetson nano didn't work without ethernet being connected. It was obviously broken & a lot of users have trouble getting reliable USB in general. Power management for USB might have gotten busted when it was hacked for servos. Maybe it was back EMF from the servos. Maybe it just burned out over time. Disabling power management with /sys & usbcore.autosuspend=-1 didn't work. Ideally there would be a way to trick the ethernet port into thinking it was connected, but the world's favorite search engine ended that party.
![]()
The best hope was hacking the tegra-xusb-padctl driver to stay on. There's a kernel compilation guide on https://developer.ridgerun.com/wiki/index.php/Jetson_Nano/Development/Building_the_Kernel_from_Source
cd /root/Linux_for_Tegra/source/public/ export JETSON_NANO_KERNEL_SOURCE=`pwd` export TOOLCHAIN_PREFIX=/opt/gcc-linaro-7.3.1-2018.05-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu- export TEGRA_KERNEL_OUT=$JETSON_NANO_KERNEL_SOURCE/build export KERNEL_MODULES_OUT=$JETSON_NANO_KERNEL_SOURCE/modules make -C kernel/kernel-4.9/ ARCH=arm64 O=$TEGRA_KERNEL_OUT LOCALVERSION=-tegra CROSS_COMPILE=${TOOLCHAIN_PREFIX} tegra_defconfig # Change some drivers to modules make -C kernel/kernel-4.9/ ARCH=arm64 O=$TEGRA_KERNEL_OUT LOCALVERSION=-tegra CROSS_COMPILE=${TOOLCHAIN_PREFIX} menuconfig # change to modules: # Device Drivers → USB support → xHCI support for NVIDIA Tegra SoCs # Device Drivers → USB support → NVIDIA Tegra HCD support # Device Drivers → PHY Subsystem → NVIDIA Tegra XUSB pad controller driver # disable Device Drivers → USB support → OTG support # disable Device Drivers → USB support → USB Gadget Support make -C kernel/kernel-4.9/ ARCH=arm64 O=$TEGRA_KERNEL_OUT LOCALVERSION=-tegra CROSS_COMPILE=${TOOLCHAIN_PREFIX} -j8 --output-sync=target zImage make -C kernel/kernel-4.9/ ARCH=arm64 O=$TEGRA_KERNEL_OUT LOCALVERSION=-tegra CROSS_COMPILE=${TOOLCHAIN_PREFIX} -j8 --output-sync=target modules make -C kernel/kernel-4.9/ ARCH=arm64 O=$TEGRA_KERNEL_OUT LOCALVERSION=-tegra CROSS_COMPILE=${TOOLCHAIN_PREFIX} -j8 --output-sync=target dtbs make -C kernel/kernel-4.9/ ARCH=arm64 O=$TEGRA_KERNEL_OUT LOCALVERSION=-tegra INSTALL_MOD_PATH=$KERNEL_MODULES_OUT modules_installThen there's a nasty procedure for flashing the jetson. Lions just back up /boot/Image then
cp build/arch/arm64/boot/Image /antiope/boot/
cp -a modules/lib/modules/4.9.140-tegra/ /antiope/lib/modules/
cp -a build/arch/arm64/boot/dts/*.dtb /antiope/boot/dtb/
The trick is the NFS mount requires having ethernet plugged in, bypassing the bug. The offending modules are
/lib/modules/4.9.140-tegra/kernel/drivers/usb/host/xhci-tegra.ko
/lib/modules/4.9.140-tegra/kernel/drivers/phy/tegra/phy-tegra-xusb.ko
The USB hub is actually a RTS5411 on the carrier board, MFG ID 0bda. The jetson card has only 1 USB port which supports OTG.
Ethernet is provided by a RTL8111 on the jetson card.
The lion kingdom managed to hack phy-tegra-xusb to not turn USB off after unplugging ethernet, but it won't turn on until ethernet is plugged in. Interestingly, once phy-tegra-xusb is loaded it can't be unloaded.
You can get phy-tegra-xusb to call the power_on functions without ethernet but it can't enumerate anything until ethernet is plugged in. There's a power on step which is only done in hardware. The power off step is done in software. USB continued to disconnect, despite enabling the pads.
A key requirement is disabling power management for some drivers
find /sys/devices/50000000.host1x -name control -exec sh -c 'echo on > {}' \;
This kicks it up to 3W & starts roasting the heat sink.
The kernel outputs vdd-usb-hub-en: disabling but there's nothing about where the print is or any device tree specifying a hub.
Verified a stock jetpack image has the same problem. Software options were all busted.
Outside chatgpt, a few more keyword combinations revealed many bit banged ethernet projects which can simulate a cable connection. They're short on any specific timing & voltage.
https://github.com/cnlohr/ethertiny
![]()
Much troubleshooting revealed this, with the RX +/- pins on the jetson connected to some GPIOs on a 5V arduino.
![]()
Then you pulse the + pin followed by the - pin. It seems to require pulses of 100ns length every 16ms. It doesn't matter what the order of the pulses is, whether they're on the TX or RX pins, whether there are resistors. The link light doesn't turn on. Activity blinks 3 times & goes dark with an exponential backoff, but the kernel reports a link up & starts enabling USB.
After enumerating, it still disconnected USB despite showing activity. If the power management was all disabled, it would repeatedly enumerate the hub & disconnect. Timing changes made no difference.
This method only gives a solid link light when going into a hub. There are ways to bit bang packets, but they require a 20Mhz clock. There is a more comprehensive ethernet MAC for an RP2040 but a clockspeed over 20Mhz is required. It has to listen for packets from the jetson. The lion kingdom could hack a bitbanged ethernet MAC many ways but in the interest of time, the next step is a W5500 SPI to ethernet gadget. This provides a full ethernet MAC over SPI. It could fit inside the enclosure. It could probably work without its RJ45.
There's a trend of progressive failure. Methods of enabling USB have gone from working to not working. There are anecdotes of jetson nanos burning out over time when run without a fan. It could be a marginal voltage or timer. In the worst case, the USB ports could die permanently & I/O could be encapsulated in ethernet.
The W5500 arrived only to turn on USB just with its power being plugged in. It was just the small load on the 3.3V rail.
![]()
Certainly a much easier hack than what lions were doing before. Maybe the 3.3V load was what always turned USB on. Maybe it was a goofy power management dependency, a missing component on the board, or a burned out load sensor. Just a matter of waiting & seeing if this progressively fails.
-
Plastic modelling
04/03/2023 at 02:25 • 0 commentsServo board enclosure
![]()
There was a real fight to retain some kind of IR capability, including modeling an opening for it & trying to glue it. There never was a good way of mounting it. The fact is it's not going to be used. The best mounting solution might eventually be PLA riveting down a separate box which surrounds the back of the IR sensor. In the mean time, it just flops around.
![]()
![]()
The tripod mounting evolved to a more compact puck which bolts on. The puck is of course modeled after a certain rocket engine injector plate.
![]()
![]()
![]()
Then, the servo board just hooks onto the puck. The servo wires hook up to umbillicals. The ziploc bag gets chewed up by the gear & sticks down too far. It needs a more permanent gear shroud, but there's no way to farsten a PLA shroud to the aluminum. The puck still doesn't attach firmly to the tripod. It needs indentations on the underside for the set screws to grab onto but any PLA is just going to flex.
![]()
There is a desire to make an alternative puck for clamping it on a bench, but whatever replaces the puck still needs to allow the servo board to hook on. The bare aluminum can clamp on, but isn't very secure. This system has been years in the making. It started before lions had any semblance of a real bench.
![]()
Pan/tilt head finally got gear shrouds. These actually stay in place passively, but can be wired in for transport. Sadly, they're too flimsy & delaminate.
The flash mounting is still unsolved. It was originally just clamped onto a larger puck. Then it seemed to migrate to another tripod.
All the USB ports on the jetson are powered by a common 5V. This was bodged to make it do the full 2A.
![]()
![]()
Next, time to scavenge parts from the 1st enclosure. It would have made a hell of a portable TV, 40 years ago, when just getting a moving picture to appear on anything was a miracle. We just don't use portable TV's anymore. The overhead expansion slots worked, even if they were hard to get the cards out of. The battery door stopped latching. The swinging back door worked, even if the magnets were out of alignment. It was quite sturdy despite being made of PLA.
![]()
Ideas for a wifi enclosure weren't a whole lot more compact. They revolved around a bundle of excess wiring sized for the portable TV & the buck converter. On top sits the jetson with ports facing up. On the bottom sits the battery. The power switch sticks out the top or the side. Outlets for 12V & 5V stick out the side to power a flash. The wiring could be resoldered again to move the outlets to the top.
![]()
![]()
![]()
The result was a self contained jetson nano module. Helas, the USB ports no longer worked. They all had 5V but couldn't detect anything anymore. It seems the external 5V puts them into device mode. Plugging in ethernet puts them into host mode. A kernel recompile without OTG support might work.
The power supply ended up being a $25 Castle Creations 10A. These are super compact & make a lot more power than the LM2596.
![]()
![]()
Fully assembled tripod head for historic purposes.
-
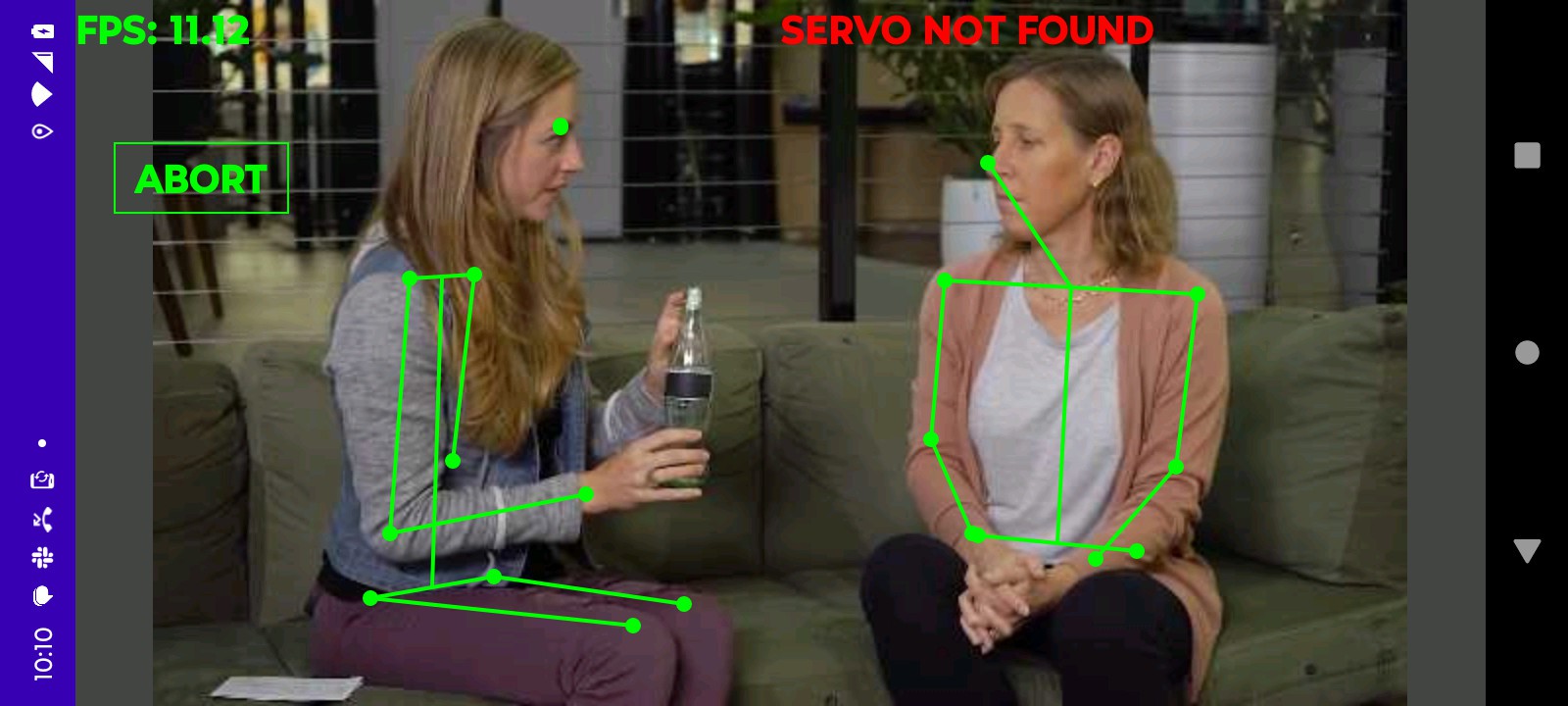
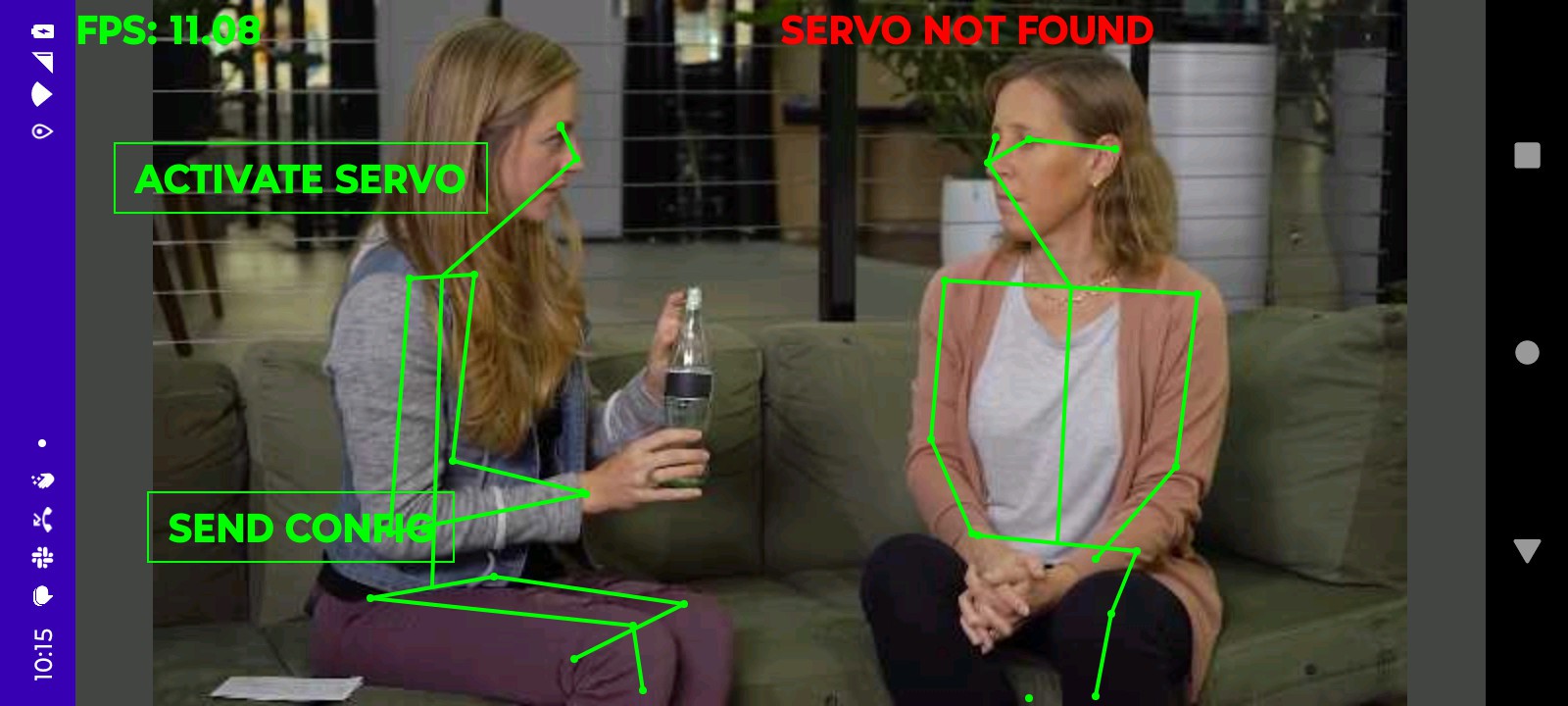
Phone interface with jetson
03/26/2023 at 02:33 • 0 comments![]()
Old laptop wifi was a fail.
![]()
Macbook wifi was a fail.
![]()
For something which comes nowhere close a 5 year old laptop, it's impressively packed with 0201's.
![]()
The HDMI, wifi, & servos actually fit into all the USB ports with some bending.
Back to problematic USB dongles & a phone interface it was. This also meant the beloved IR remote was useless. This would require yet another enclosure for the battery, confuser & USB dongles. The enclosure would need a phone holder. It probably needs a fan.
The RTL8188 driver on the jetson manages to stay connected, but still drops out for long periods when it's more than a foot away. Like all wifi drivers, if it's not connected eventually powers down & has to be restarted.
Wifi rapidly degrades beyond a few feet, probably because of the high bitrate of 2megbit. UDP is essential, but the wifi is so bad it might be necessary to use USB tethering. Restarting the app brings it back, but recreating the socket does not. Android might restrict wifi usage a number of ways.
The MACROSILICON HDMI dongle is able to output 640x480 raw YUV, which kicks the framerates up a notch. It only uses 25% of 1 core so overclocking would make no difference. Compression of JPEG frames for the wifi has to be done in a thread. The HDMI output has to be kept in YUV outside of the GPU. The neural network needs RGB, so the YUV to RGB conversion has to be done in the GPU. This arrangement got the 256x144 model from 6.5 up to 8fps. This stuff definitely needs to be in a library to be shared with truckcam.
A key step in CUDA programming is dumping the error code when your CUDA functions return all 0.
cudaDeviceSynchronize(); cudaError_t error = cudaGetLastError(); if(error != 0) printf("%s\n", cudaGetErrorString(error) );The most common error is too many resources requested for launch which means there either aren't enough registers or there are too many kernels. The goog spits out garbage for this, but lions got it to work by reducing the blockSize argument. This increases the gridSize argument.
Portrait mode is best done by loading 2 models simultaneously. A 160x240 body_25 was created for portrait mode. This runs at 7fps because it has slightly more neurons. It does much better than stretching 256x144. The resident set size when loading 1 model is 1 gig & 2 models is 1.4 gig.
![]()
All 4 modes need to be paw debugged. Screen dimensions on the Moto G Pure are different than the Wiki Ride 3. The mane trick is the neural network scans the center 3:2 in portrait mode while it scans the full 16:9 in landscape mode. It might be easier if all the keypoints are scaled to 0-1 instead of pixel coordinates.
That leaves bringing up the servo head with the jetson. The good news is this app is pretty solid after 3 years.
There is a person outline detector which might give better results. Testing different models is long & hard. The entire program has to be rewritten. They have to detect sideways & overlapping animals.
-
The truth about INT8
03/19/2023 at 22:23 • 0 commentsThe next step after FP16's disappointing results was INT8. The trick with INT8 is it requires a calibration step & the goog has nothing on that. NvInfer.h has a bunch of calibration functions. trtexec has a --calib option for reading a calibration file but nothing for creating a calibration file. The calibration file seems to be just a table of scaling values for each layer in the network.
The IBuilderConfig used in creating the tensorrt engine has a setInt8Calibrator function. It seems the model has to be converted to FP32 by trtexec once, executed on a data set to create a calibration file, then the model has to be converted again to INT8 by trtexec with the calibration file passed to the --calib option. A key requirement is the creation of a batch stream.
Helas, int8 is not supported on the jetson nano, so it would be a waste of time. Int8 is a relatively new concept, so GPUs before 2020 don't support it.
Instead, it was time to try the lowest possible network size in FP16, 224x128.
Enter the desired H & W in the prototxt file:
/root/openpose/models/pose/body_25/pose_deploy.prototxt
name: "OpenPose - BODY_25" input: "image" input_dim: 1 # This value will be defined at runtime input_dim: 3 input_dim: 128 # This value will be defined at runtime input_dim: 224 # This value will be defined at runtimeConvert to ONNX:
time python3 -m caffe2onnx.convert --prototxt pose_deploy.prototxt --caffemodel pose_iter_584000.caffemodel --onnx body25_128x224.onnxReplace broken operators:
time python3 fixonnx.py body25_128x224.onnx body25_128x224_fixed.onnxFinally convert to tensorrt:
time /usr/src/tensorrt/bin/trtexec --onnx=body25_128x224_fixed.onnx --fp16 --saveEngine=body25_128x224.engine9fps 224x128 using 640x360 video represents the fastest useful output it can generate. It's about as good as resnet18. Input video size has a big impact for some reason. What might be benefiting it is the use of 25 body parts to create redundancy.
In porting the rest of the tracker to tensorrt, it became clear that the large enclosure lovingly created for the jetson nano isn't going to do the job. It's no longer useful for rep counting & it's too big. The speakers especially have no use. A phone client began to gain favor again. Noted the battery door deformed & no longer latches. Another idea is making the screen a detachable module. Throwing money at a laptop would solve everything.
-
Body_25 using FP16
03/15/2023 at 02:53 • 0 commentsWhile porting BodyPartConnectorCaffe, it became clear that the easiest solution was to link openpose against the tensorrt library (nvinfer) rather than trying to move the openpose stuff into the trt_pose program. It would theoretically involve replacing just the use of spNets in poseExtractorCaffe.cpp. It would still be work & most of the unhappy path was already done though.
BodyPartConnectorCaffe entailed copying most of openpose. In the end, the lion kingdom's attempt to port just a subset of openpose became a complete mess. Having said that, the port was just the GPU functions. The post processing is so slow, the CPU functions aren't any use on a jetson nano.
Should be noted all the CUDA buffs are float32 & all the CUDA functions use float32. No fp16 data types from the tensorrt engine are exposed. INT8 started gaining favor as a next step, since it could impact just the engine step, but the value ranges could change.
Another important detail is they instantiate a lot of templates in .cpp files with every possible data type (classType className<unsigned short>;) Despite this efficiency move, they redefine enumClasses.hpp in 9 places.
![]()
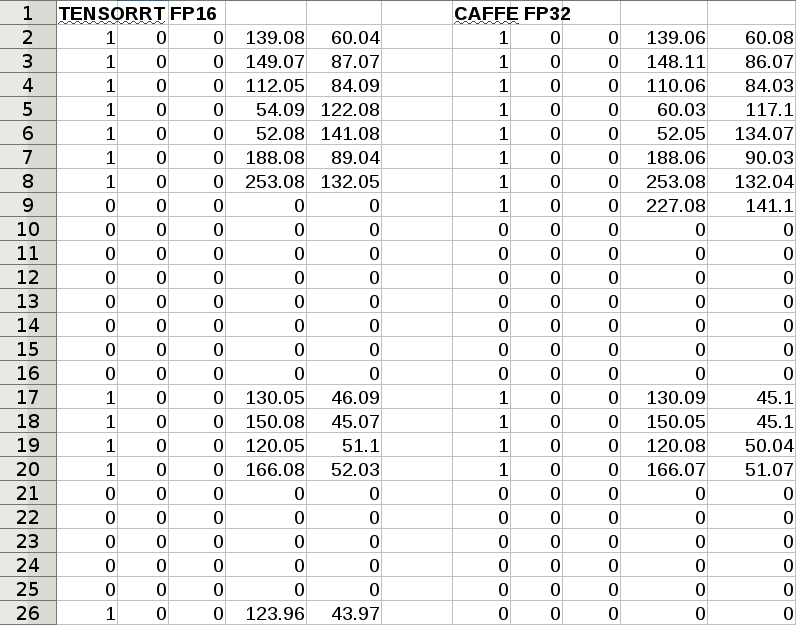
The non maximum suppression function outputs a table of obviously 25 body parts with 3 columns of some kind of data. It's interesting how close FP16 & FP32 came yet 2 rows are completely different. The rows must correspond to POSE_BODY_25_BODY_PARTS + 2. Row 9 must be LWrist. Row 26 must be RHeel. Neither of those are really visible. The difference is not RGB vs BGR, brightness or contrast, the downscaling interpolation, but some way the FP16 model was trained.
After 1 month invested in porting body_25 to FP16, the result was a 3.3fps increase. The model itself can run at 9fps, but the post processing slows it down. The GUI slows it down by .3fps. The FP32 version did 5fps with a 224x128 network. The FP16 version hit 6.5fps with a 256x144 network, 8.3fps with a 224x128 network. It's still slower than what lions would consider enough for camera tracking.
Results are somewhat better if we match the parameters exactly. 128x224 network, 640x360 video experiences a doubling of framerate in FP16. The size of the input video has a dramatic effect. There is less accuracy in FP16, as noted by the NMS table.
-
Debugging tensorrt
03/06/2023 at 05:43 • 0 commentsPrevious results with efficientdet were documented here:
https://hackaday.io/project/162944/log/203849-best-results-with-raspberry-pi-4
Reasons for not using efficientdet were documented here:
https://hackaday.io/project/162944/log/203975-the-last-temptation-of-christ
Detecting 2 overlapping animals, lying positions, & oscillations from windowing were the deal breakers.
Despite the naming convention, all the caffe "forward" functions in openpose seem to be raw CUDA with no specific dependencies on CAFFE. The memory mapping for the CAFFE & CUDA buffers is the same. They're flat float buffers of pixel data. The CAFFE buffers (ArrayCpuGpu) have a cpu_data() to access the data from the CPU. The CUDA buffers have a cudaMemcpy to access the data from the CPU.
To debug the porting effort, it was essential to have the caffe & tensorrt programs read the same frame from a gootube vijeo (yJFOojKXe4A) as input. Then write different stages of the output as flat PPM files. Never underestimate the value of obsolete formats like PPM.
![]()
Input to body_25 is 3 256x144 planes
![]()
The output of body_25 is 78 32x18 frames. Obviously the top frames are the part affinity fields for each body part & the bottom frames are the confidence maps of how the body parts attach. 1 frame is a background.
![]()
In the tensorrt version, much effort was spent chasing why the output was Nan, all 0 or rotated. 1 problem is CUDA doesn't give any errors for buffer overruns so it wasn't allocating a big enough input frame. Another problem was the input dims back in pose_deploy.prototxt were height & width.
name: "OpenPose - BODY_25" input: "image" input_dim: 1 # This value will be defined at runtime input_dim: 3 input_dim: 144 # This value will be defined at runtime input_dim: 256 # This value will be defined at runtime![]()
The proper output of tensorrt was nearly identical to caffe. Minor differences could have been caused by FP16, which means all of the improvement in body_25 could be from the bit precision rather the model. trt_pose drops a lot of body parts & sure enough, the big difference with FP16 is some markers not being as bright as float32.
The spResizeAndMergeCaffe function just upscales these 32x16 frames back to the original 256x144 resolution. The magic is in spNmsCaffe (NmsCaffe) & spBodyPartConnectorCaffe (BodyPartConnectorCaffe). Those 3 functions are busters with many openpose dependencies & multidimensional arrays.
-
Openpose framerates with tensorrt
03/04/2023 at 06:36 • 0 commentsDecided to benchmark body25 without decoding the outputs & got a variety of frame rates vs. network size.
256x256 5.5fps
224x224 6.5fps
192x192 8fps
160x160 9fps
256x144 9fps
128x128 12fps
448x256 was what the Asus GL502V has used at 12fps since 2018. Lions believe 9fps to be the lowest useful frame rate for tracking anything. It pops between 160x160 & 128x128 for some reason. Considering 224x128 with the original caffe model hit 5fps, it's still doing a lot better. Memory usage was about half of the caffe model. It only needs 2GB.
This was using 1280x720 video. Capturing 640x360 stepped up the frame rates by 5% because of the GUI refreshes. Sadly, it's not going to do the job for rep counting, but it should be enough for camera tracking.
Following the logic in openpose, the magic happens in PoseExtractorCaffe::forwardPass.
The model fires in spNets.at(i)->forwardPass
The output appears in spCaffeNetOutputBlobs. The sizes can be queried with
spCaffeNetOutputBlobs[0]->shape(1) = 78
spCaffeNetOutputBlobs[0]->shape(2) = 18
spCaffeNetOutputBlobs[0]->shape(3) = 32The output dimensions are transposed from 32x18 to 18x32.
At this point, it became clear that openpose uses a 16x9 input size instead of 1x1 like trt_pose. Providing it -1x128 causes it to make a 224x128 input. Providing it -1x256 causes it to make a 448x256 input. That could explain why it's more robust than trt_pose but it doesn't explain why body25 did better with 16x9 than 4x3.
Openpose processes the output strictly in CUDA while trt_pose does it in the CPU. The CUDA functions sometimes call back into C++.
Openpose does an extra step which trt_pose doesn't called "Resize heat maps + merge different scales".
spResizeAndMergeCaffe->Forward transfers the output from spCaffeNetOutputBlobs 18x32 to spHeatMapsBlob 78x144x256
TRT_pose & openpose both continue with non maximum suppression. trt_pose calls find_peaks_out_nchw & openpose calls spNmsCaffe->Forward. Trt_pose does it in the CPU. Openpose does it in the GPU.
spNmsCaffe->Forward transfers spHeatMapsBlob 78x144x256 to spPeaksBlob 25x128x3
find_peaks_out_nchw transfers the CMAP 42x56x56 to refined_peaks (size 3600) peak_counts (size 18) & peaks (size 3600)
Finally openpose connects the body parts by calling spBodyPartConnectorCaffe->Forward which indirects to connectBodyPartsGpu in CUDA.
This transfers spHeatMapsBlob & spPeaksBlob to mPoseKeypoints & mPoseScores but doesn't use a PAF table anywhere. TRT_pose does 3 more steps in the CPU with a PAF table.
At this point, it seems simpler to port PoseExtractorCaffe::forwardPass to tensorrt & keep its CUDA functions intact.
Auto tracking camera
A camera that tracks a person & counts reps using *AI*.