biemster
biemster-
SODA finally landed, client working
12/15/2020 at 18:03 • 23 commentsUPD: wine is not necessary anymore.
So SODA finally landed, sort of, and for a couple weeks already apparently. I've been on the lookout for the Linux library, since that is my preferred environment and I was under the impression that the development was taking place on that platform. But I was wrong, and the Windows and macOS libraries were available since late November.
Since I'm much more capable on a Linux machine, I've searched (and found!) a way to use either one of those available libraries. In my last post I reported on quite a successful project with the Google TTS library, which resulted in a very lightweight client for it. And fortunately the same can be said for the SODA client, resulting in a very small code base with only the library as dependency. This enabled me to work with wine, and have it pipe the data straight from whatever Linux application I wanted to use to the Windows DLL.
Just issue the following command:
$ ecasound -f:16,1,16000 -i alsa -o:stdout | wine gasr.exeand watch your conversations roll over the screen:
W1215 22:58:43.683654 44 soda_async_impl.cc:390] Soda session starting (require_hotword:0, hotword_timeout_in_millis:0) >>> hello >>> hello from >>> hello from >>> hello from sod >>> hello from soda >>> hello from soda >>> final: hello from sodaThe SODA client I wrote is developed in a separate repository (gasr), as it will be mostly just a tool to do the full reverse engineering of the RNN and transducer. But having an actual working implementation will greatly improve my ability to figure out the inner workings of the models.
Using wine as an intermediate is still far from ideal, but I guess that the Linux library will also pop up soon considering ChromeOS would depend on it.
UPDATE:
As @a1is pointed out, the Linux library is also out there already, so no need to go the wine way anymore. And as an added bonus, the GBoard models are working with these libraries as well! That opens up a whole world of experimentation, since there are already quite a few of those spotted in the wild!
UPDATE2:
Now with a python client in the repo, for easier integration with home automation and such.
-
ChromeVox Next offline TTS client, a sister project
11/30/2020 at 15:23 • 2 commentsIn a large part my reason to start this speech recognition project was for home automation, and to get some feedback from my home a logical companion project is the reverse of speech recognition: Text to Speech (TTS). The offline TTS on Android has quite a pleasant voice and seemed to be running on Chrome on Desktop as well, so it made a perfect combination with the recognition pipeline.
With the recognition project waiting for SODA to be released for Chrome, I had a bit of time to tackle this TTS, which turned out to be quite a bit easier, and definitely quicker!
I started with getting a copy of Chrome OS in a virtual machine, courtesy of neverware.com. Incidentally I also found a page in the Chrome source repo mentioning that the TTS part of Chrome OS can be downloaded separately.
After a weekend of getting ltrace running on chromeos, and tracing the calls to the googletts library, I wrote a tiny (~50 lines of C) client which pipes any Google voice (there are quite many languages available) to for example ALSA:
./gtts "Hello from Google Text to Speech!" | aplay -r22050 -fFLOAT_LE -c1It's just a tiny proof of concept, which can easily be added to any C/C++ project out there. Also a python wrapper would be awesome, maybe I get to that someday (or maybe you want to pick that up?). Code lives on github, if you decide to use it don't forget to leave a comment below!
-
SODA: Speech On-Device API
05/04/2020 at 16:13 • 10 commentsProgress has been slow lately, due to the difficulty of tracing the apps in how they use the models, and also my lack of free android hardware to run tests on. However, this may become completely irrelevant in the near future!
It seems Google is building speech recognition into Chromium, to bring a feature called Live Caption to the browser. To transcribe videos playing in the browser a new API is slowly being introduced: SODA. There is already a lot of code in the chromium project related to this, and it seems that it might be introduced this summer or even sooner. A nice overview of the code already in the codebase can be seen in the commit renaming SODA to speech recognition.
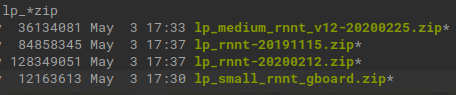
What is especially interesting is that it seems it will be using the same language packs and RNNT models as the Recorder and GBoard apks, since I recently found the following model zip:
![]()
It is from a link found in the latest GBoard app, but it clearly indicates that the model will be served via the soda API. It is still speculative though, but it seems only logical (to me at least) that the functionality in Chromium will be based on the same models. There is also this code:
which indicates that soda will come as a library, and reads the same dictation configs as the android apps do.
Since Chromium is open source, it will help enormously in figuring out how to talk to the models. This opens up a third way of getting them incorporated into my own projects:
1) import the tflite files directly in tensorflow (difficult to figure out how, especially the input audio and the beam search at the end)
2) create a java app for android and have the native library import the model for us (greatly limits the platform where it can run on, also requires android hardware which i don't have free atm)
3) Follow the code in Chromium, as it will likely use the same models
I actually came up with a straightforward 4th option as well recently, and can't believe I did not think of that earlier:
4) Patch GBoard so it also enables "Faster voice typing" on non-Pixel devices. Then build a simple app with a single text field that sends everything typed (by gboard voice typing) to something like MQTT or whatever your use case might be.
I'll keep a close eye on the Live Transcribe feature of Chromium, because I think that that is the most promising path at the moment, and keep my fingers crossed it will show how to use those models in my own code. In the mean time I found a couple more RNNT models for the GBoard app, one of which was called "small" and was only 12MB in size:
Very curious how that one performs!
UPDATE june 8:
The following commit just went into the chromium project, stating:
This CL adds a speech recognition client that will be used by the Live Caption feature. This is a temporary implementation using the Open Speech API that will allow testing and experimentation of the Live Caption feature while the Speech On-Device API (SODA) is under development. Once SODA development is completed, the Cloud client will be replaced by the SodaClient.
So I guess the SODA implementation is taking a bit longer than expected, and an online recognizer will be used initially when the Live Caption feature launches. On the upside, this temporary code should already enable me to write some boilerplate stuff to interface with the recognizer, so when SODA lands I can hit the ground running.
-
Pixel 4 Recorder app with offline transcribe
10/16/2019 at 07:58 • 4 commentsSo 15th of October Google showcased the new Recorder app for Pixel 4 devices, with real time transcription. After downloading the app and peaking inside it contains the same type of RNNT models with 2 encoders, a decoder and a joint, so I assume it's the same model. It is considerably smaller though, so I expect it to be an update.
The tflite files are also not obfuscated, and the zip contains .ascii_proto files that are human readable. It even contains shell scripts to run the models on a local machine!
This is the third full model I'm analysing, and seems to contain the most info thus far. I'll update this log is I find out more.
-
Google Open-Sources Live Transcribe's Speech Engine
08/19/2019 at 12:54 • 0 commentsThis is mainly a log to indicate that this project is still very much alive. Google announced August 16th that it open sourced the Live Transcribe speech engine, with an accompanying github repo. What is especially interesting for this project is the following line in the github Readme.md:
- Extensible to offline models
I'll be dissecting the code in this repository for the next weeks, and I expect to get some good hints how to feed the models in my project with a correctly processed audio stream. And maybe I can even plug in the offline models directly and build an android app with it, who knows? More to come.
-
Recovering the symbol table
03/27/2019 at 18:48 • 0 commentsOne last thing that was still missing was the symbol table. Apparently the output of the softmax layer maps directly to the symbol table, and since this output is 128 in length, I was searching for a table of this same length.
The prime suspect was of course the 'syms' binary, but I could not seem to open it. The blog post mentions FST, so I started my investigation with OpenFST. There is a nice python wrapper that could open the file, and returned some sensible name for the thing. But when I queried the keys, it would return 0.
In a hex editor I already noticed a funny sentence somewhere in the body: "We love Marisa." Initially I thought that was some padding built in by a developer, and took no notice of it. However, this is actually the header of a filetype for the library libmarisa, which is an acronym for Matching Algorithm with Recursively Implemented StorAge.
Extracting just this part of the binary is easy:
import sys fname = sys.argv[1] b = bytearray(open(fname, 'rb').read()) for i in range(len(b)): if b[i:i+15] == "We love Marisa.": open(fname + '.marisa', 'wb').write(b[i:]) breakAnd the file syms.marisa can be read with the python package marisa-trie, presenting me with a nice symbol table:
import marisa_trie trie = marisa_trie.Trie() trie.load('syms.marisa') <marisa_trie.Trie object at 0x7f5ad44330b0> trie.items() [(u'{', 0), (u'{end-quotation-mark}', 122), (u'{end-quote}', 123), (u'{exclamation-mark}', 124), (u'{exclamation-point}', 125), (u'{quotation-mark}', 126), (u'{quote}', 127), (u'{question-mark}', 103), (u'{sad-face}', 104), (u'{semicolon}', 105), (u'{smiley-face}', 106), (u'{colon}', 107), (u'{comma}', 108), (u'{dash}', 109), (u'{dot}', 110), (u'{forward-slash}', 111), (u'{full-stop}', 112), (u'{hashtag}', 113), (u'{hyphen}', 114), (u'{open-quotation-mark}', 115), (u'{open-quote}', 116), (u'{period}', 117), (u'{point}', 118), (u'{apostrophe}', 94), (u'{left-bracket}', 95), (u'{right-bracket}', 96), (u'{underscore}', 97), (u'<', 1), (u'<s>', 119), (u'<sorw>', 120), (u'<space>', 121), (u'</s>', 98), (u'<epsilon>', 99), (u'<noise>', 100), (u'<text_only>', 101), (u'<unused_epsilon>', 102), (u'!', 2), (u'"', 3), (u'#', 4), (u'$', 5), (u'%', 6), (u'&', 7), (u"'", 8), (u'(', 9), (u')', 10), (u'*', 11), (u'+', 12), (u',', 13), (u'-', 14), (u'.', 15), (u'/', 16), (u'0', 17), (u'1', 18), (u'2', 19), (u'3', 20), (u'4', 21), (u'5', 22), (u'6', 23), (u'7', 24), (u'8', 25), (u'9', 26), (u':', 27), (u';', 28), (u'=', 29), (u'>', 30), (u'?', 31), (u'@', 32), (u'A', 33), (u'B', 34), (u'C', 35), (u'D', 36), (u'E', 37), (u'F', 38), (u'G', 39), (u'H', 40), (u'I', 41), (u'J', 42), (u'K', 43), (u'L', 44), (u'M', 45), (u'N', 46), (u'O', 47), (u'P', 48), (u'Q', 49), (u'R', 50), (u'S', 51), (u'T', 52), (u'U', 53), (u'V', 54), (u'W', 55), (u'X', 56), (u'Y', 57), (u'Z', 58), (u'[', 59), (u'\\', 60), (u']', 61), (u'^', 62), (u'_', 63), (u'`', 64), (u'a', 65), (u'b', 66), (u'c', 67), (u'd', 68), (u'e', 69), (u'f', 70), (u'g', 71), (u'h', 72), (u'i', 73), (u'j', 74), (u'k', 75), (u'l', 76), (u'm', 77), (u'n', 78), (u'o', 79), (u'p', 80), (u'q', 81), (u'r', 82), (u's', 83), (u't', 84), (u'u', 85), (u'v', 86), (u'w', 87), (u'x', 88), (u'y', 89), (u'z', 90), (u'|', 91), (u'}', 92), (u'~', 93)]I believe I have recovered all the main components now, so what is left is just brute forcing how to present the data to the individual models. I earlier overlooked that the decoder should be initialised with a <sos> start of sequence when an utterance starts, so I think I should get a proper endpointer implementation and experiment which symbol is this <sos> (I only could find a <sorw>, <s> and </s>).
-
Experiments with the endpointer
03/26/2019 at 19:25 • 0 commentsMy focus at the moment is on the endpointer, because I can bruteforce its parameters for the signal processing a lot faster than when I use the complete dictation graph. I added a endpointer.py script to the github repo which should initialize it properly. I'm using a research paper which I believe details the endpointer used in the models as a guide, so I swapped to using log-Mel filterbank energies instead of the plain power spectrum as before.
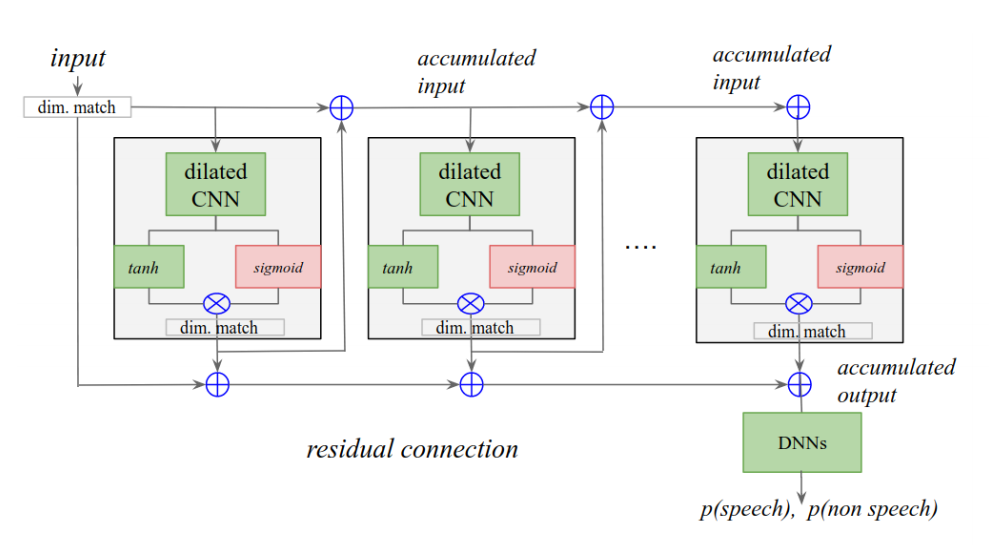
I believe the endpointer net outputs two probabilities: p(speech) and p(non speech) as given in this diagram from the paper:
![]()
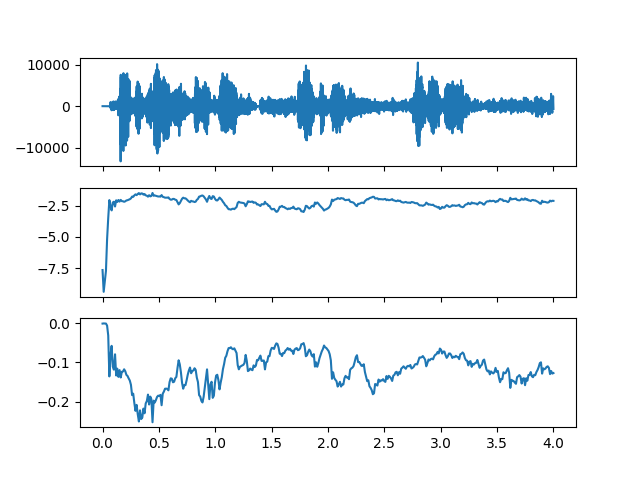
The results from the endpointer.py are still a bit underwhelming:
![]()
so some more experiments are needed. I'll update this log when there are more endpointer results.
UPDATE:
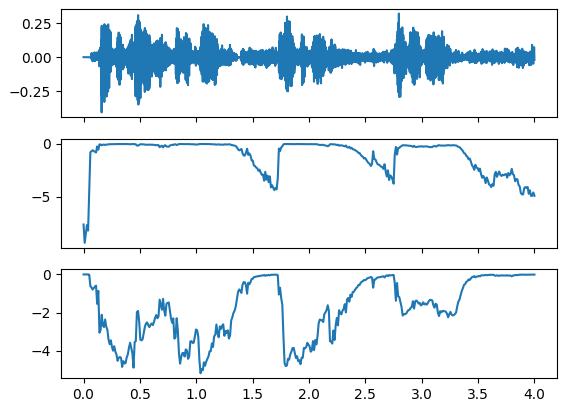
Thanks to awesome work being done by thebabush in the github repo, the endpointer gives very good results now! The most relevant changes are the normalisation of the input by 32767, and the change of the upper bound of the log mel features from 7500Hz to 3800Hz. This gives excellent results:
The top plot is the wav file with some utterances, the middle is p(speech) and the bottom is p(non speech), both with 0 being high probability. (Or the other way around, actually not sure of the absolute meaning of the values)
-
First full model tests
03/22/2019 at 20:45 • 0 commentsThe github repo is updated with the first full model test. This test just tries to run the RNNs with a sample wav file input.
What this experiment does is the following:
- Split the incoming audio in 25 ms segments, with a stepsize of 10ms (so the input buffers overlap). Compute the FFT to calculate the energies in 80 frequency bins between 125 and 7500 Hz. The above values are taken from the dictation ascii_proto.
- Average those 80 channels to 40 channels to feed the EndPointer model. This model should decide if the end of a symbol is reached in the speech, and signal the rest of the RNNs to work their magic. Just print the output of the endpointer, since I don't know how to interpret the results.
- Feed the 80 channels to a stacker for the first encoder (enc0). This encoder takes 3 frames stacked as input, resulting in an input tensor of length 240.
- The output of the first encoder goes to a second stacker, since the input of the second encoder (enc1) is twice the length of the output of the first.
- The output of the second encoder goes to the joint network. This joint has two inputs of length 640, one of which is looped from the decoder. At first iteration a dummy input from the decoder is used, and the values from the second encoder are the second input.
- The output of the joint is fed to the decoder, which produces the final result of the model. This model is fed back into the joint network for the next iteration, and should go to the next stage of the recognizer (probably FST?)
In my initial runs the decoder outputs just NaNs, which is highly disappointing :(.
When I feed both the first and second encoder with random values, the output of the decoder is actually proper values, so my first guess is that the fft energies are not calculated correctly. That will be my focus for now, in combination with the endpointer. My next experiments will search for the correct feeding of the endpointer, so it gives sensible values at points in the audio sample where symbols should be produced.
Make it so!
*I just realize that that should be my test sample.wav*
UPDATE: the nan issue in the decoder output was easily solved by making sure no NaN values loop back from the decoder into the joint, so the joint is next iteration fed with proper values.
-
Recovering tflite models from the binaries
03/21/2019 at 08:33 • 4 commentsAfter hours of looking at hex values, searching for constants or pointers or some sort of pattern, comparing it with known data structures, and making importers for both C++ and python to no avail, I finally hit the jackpot:
When you look at the header of a proper tflite model you will see something like this:
![]()
Especially the TFL3 descriptor is present in all model files. The binary files in the superpack zip supposedly containing the models look like this:
![]()
They all have this 'N\V)' string on the same spot as the tflite model's descriptor, and nowhere else in the 100MB+ files. Then I also remembered being surprised by all these 1a values throughout all the binaries from the zip, and noticed they coincide with 00 values from the proper tflite models.
Now anybody who ever dabbled a bit in reverse engineering probably immediately says: XOR!
It took me a bit longer to realize that, but the tflite models are easily recovered xor'ing the files with the value in place of the 00's:
import sys fname = sys.argv[1] b = bytearray(open(fname, 'rb').read()) for i in range(len(b)): b[i] ^= 0x1a open(fname + '.tflite', 'wb').write(b)This will deobfuscate the binaries, which can than be imported with your favorite tensorflow lite API. The following script will give you the inputs and outputs of the models:
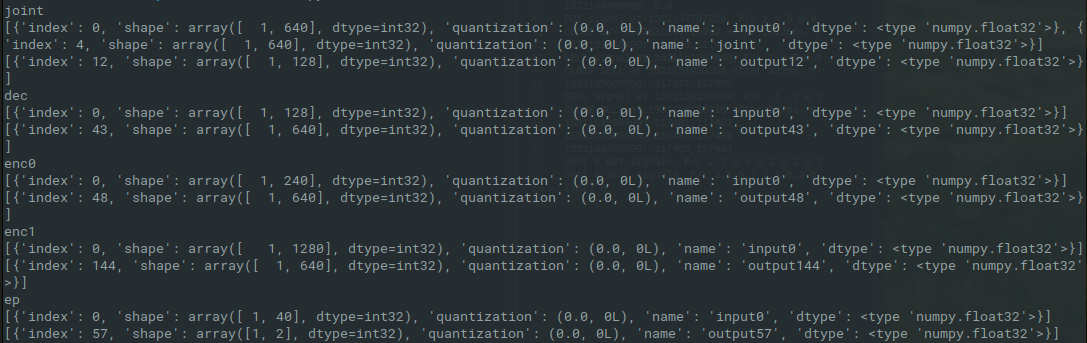
import tensorflow as tf models = ['joint','dec','enc0','enc1','ep'] interpreters = {} for m in models: # Load TFLite model and allocate tensors. interpreters[m] = tf.lite.Interpreter(model_path=m+'.tflite') interpreters[m].allocate_tensors() # Get input and output tensors. input_details = interpreters[m].get_input_details() output_details = interpreters[m].get_output_details() print(m) print(input_details) print(output_details)Now I actually have something to work with! The above script gives the following output, showing the input and output tensors of the different models:
![]()
De decoder and both encoders have an output with length 640, and the joint has two inputs of length 640. I will have to experiment a bit what goes where, since the graph I made from the dictation.config and the diagram in the blog post don't seem to be consistent here.
With the dictation.ascii_proto and those models imported in tensorflow, I can start scripting the whole workflow. I hope the config has enough information on how to feed the models, but I'm quite confident now some sort of working example can be made out of this.
-
Analysis of the dictation.config protobuf
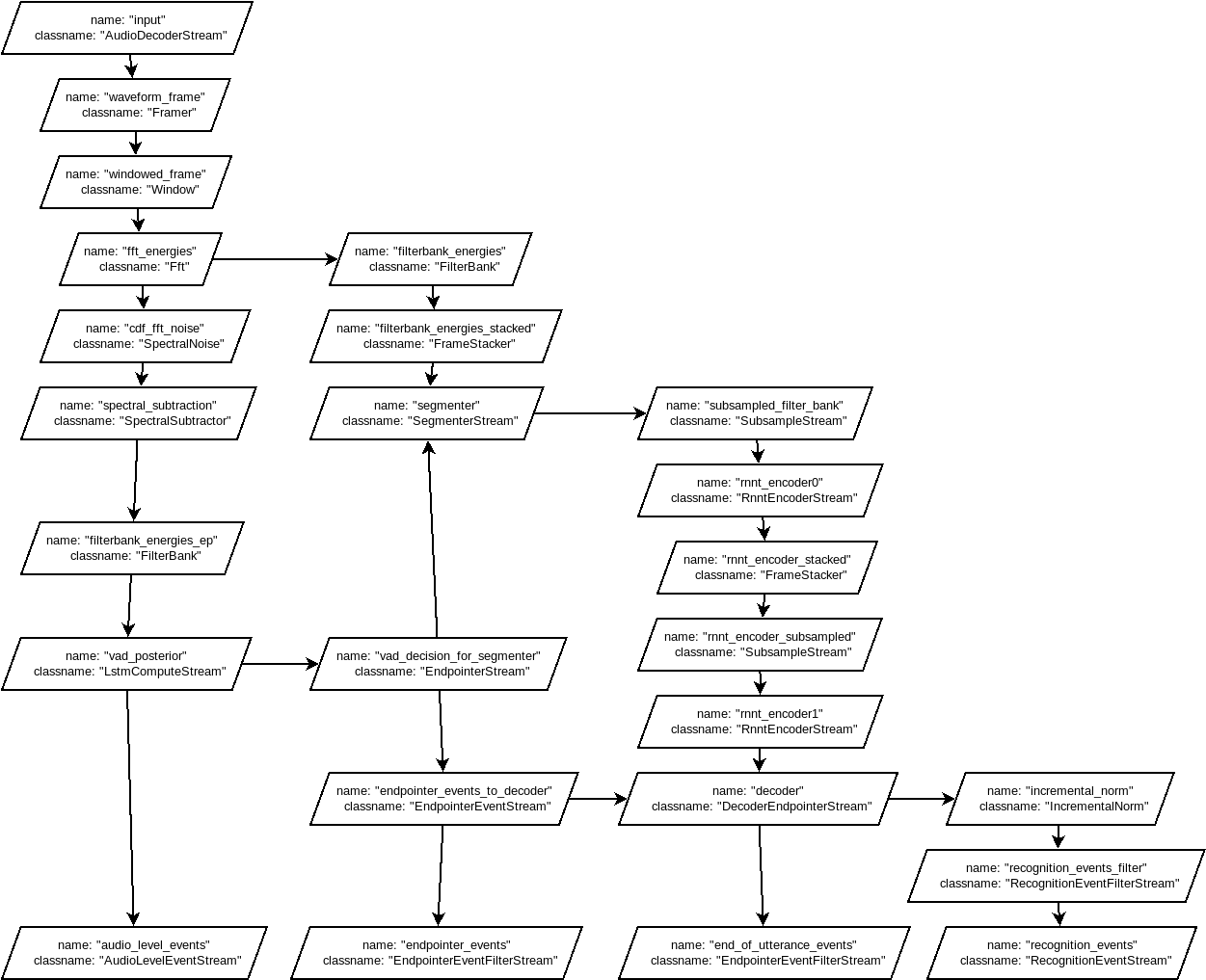
03/17/2019 at 20:10 • 0 commentsThe dictation.config seems to be the file used by GBoard to make sense of the models in the zipfile. It defines streams, connections, resources and processes. I made a graph of the streams and connections:
![]()
It starts with a single input, as expected the audio stream. There is some signal analysis done of course, before it is fed to the neural nets. If I compare this diagram with the one in the blog post, there are a couple things unclear to me at the moment:
- Where is the loop, that feeds the last character back into the predictor?
- Where does the joint network come in?
The complexity of the above graph worries me a bit, since there will be a lot of variables in the signal analysis I will have to guess. It does however seem to indicate that my initial analysis on the 'enc{0,1}' and 'dec' binaries was incorrect, since they are simply called in series in the above diagram.
This whole thing actually raises more questions than it answers, I will have to mull this over for a while. In the mean time I will focus on how to read the 3 binary nets I mention above.
Android offline speech recognition natively on PC
Porting the Android on-device speech recognition found in GBoard to TensorFlow Lite or LWTNN