biemster
biemster-
Reverse engineering GBoard apk to learn how to read the models
03/15/2019 at 10:12 • 1 commentThis is my first endeavor in reversing android apk's, so please comment below if you have any ideas to get more info out of this. I used the tool 'apktool', which gave me a directory full of human readable stuff. Mostly 'smali' files, of which I never heard before.
They seem to me some kind of pseudo code, but are still quite readable.
When I started grepping through those files again search for keywords like "ondevice" and "recognizer", and the filenames found in the zipfile containing the models, I found the following mention of "dictation" in smali/gpf.smali:
smali/gpf.smali: const-string v7, "dictation"
Opening this file in an editor revealed that the a const-string "config" was very close by, strengthening my suspicion that the app reads the "dictation.config" file to learn how to read rest of the files in the package. This is promising, since I then don't have to figure out how to do this, and if a future update comes along with better models or different languages, I just need to load the new dictation.config!
Next up is better understanding the smali files, to figure out how this dictation.config is read, and how it (hopefully) constructs TensorFlow objects from it.
UPDATE: The dictation.config seems to be a binary protobuf file, which can be decoded with the following command:
$ protoc --decode_raw < dictation.configThe output I got is still highly cryptic, but it's progress nonetheless!
UPDATE 2: I've used another {dictation.config, dictation.ascii_proto} pair I found somewhere to fill in most of the enums found in the decoded config file. This ascii_proto is uploaded in the file section, and is a lo more readable now. Next step is to use this config to recreate the tensorflow graph, which I will report on in a new log.
-
Finding the models
03/15/2019 at 09:55 • 0 commentsThe update to the on-device speech recognition comes as an option to GBoard, called "Faster voice typing" but is only available on Pixel phones as of now. I downloaded the latest version of the GBoard app, extracted it with apktool and started grepping for word like "faster" and "ondevice".
After a while the following link came up during my searches:
https://www.gstatic.com/android/keyboard/ondevice_recognizer/superpacks-manifest-20181012.json
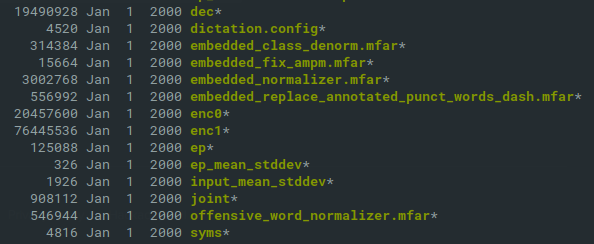
Following this link presented me with a small json file with a single link to a zip file of 82 MB containing the following files:
![]()
Well this looks promising! The size is about correct as mentioned in the blog post, and there seem to be two encoders, a joint and a decoder, just like in the described model.
More things that can be speculated are:
The encoder network is supposed to be four times as large as the prediction network, which is called the decoder. In the file list the 'enc1' file is about four times the 'dec' file, so my guess is the 'dec' file is the predictior network and the 'enc1' is the encoder on the bottom of the diagram. The 'joint' file is almost certain the Joint Network in the middle, and that would leave the 'enc0' file being the Softmax layer on top.
Fortunately the dictation.config file seems to specify certain parameters on how to read all files listed here, so my focus will be on how to interpret this config file with some TensorFlow Lite loader.
Android offline speech recognition natively on PC
Porting the Android on-device speech recognition found in GBoard to TensorFlow Lite or LWTNN