Zack Freedman
Zack Freedman-
Bleeding for My Art
05/05/2020 at 22:19 • 0 commentsOK, more like enduring joint pain for my work, but that sounds lame.
The glove's machine-learning model starts with an RNN (I'm using a LSTM for now) to pull discrete patterns out of the string of incoming coordinates. I suspect I'll need a bunch of hidden layers after that because letters are made of downstrokes, circles, and other mini-shapes, and I need a bunch of abstraction to distinguish them.
Why does this matter? Recurrent and deep networks are easy to overtrain, and that means my wrist is gonna hurt.
Overtraining is when the machine-learning model aces a test by writing the answers on its hand. The network has internalized the training data, and instead of recognizing an incoming gesture, it just outputs which training sample it looks like. It does great with the training data, but face-plants in the real world. It gets new data, looks at the answers on its hand, doesn't see any close matches, and takes an embarrassingly poor guess.
LSTM's and deep learning are physically large and can encode a lot of data within themselves. In other words, it's got a really big hand and it can't help writing answers on it. There's only one solution, and it's...
More data.
Each training run needs to consist of many samples, far more than the model can internalize. If the model tries to make a cheat sheet, it quickly runs out of paper and is forced to actually do the work. With 100 nodes in the densest layer, I estimate that I need about 100 samples for each of the 50 letters, numbers, and punctuation marks to do the job.
That's 5,000 times I need to waggle my hand for science.
The problem is, the network will still inevitably overtrain. I need this glove to work in all kinds of circumstances - when I'm walking, sitting, jogging, have my hands full, can't move much, or need to make big gestures onstage. So, I need...
Even more data.
The machine-learning model, mad lad that it is, tells me to kiss its ass and it memorizes the answers anyways. But I'm a step ahead! I give it a second test with totally different questions on it.
The model blows a wet raspberry and memorizes the answers to that test too. So, when it comes back to class, I give it a third totally different test.
This repeats, the model memorizing tests and me making new tests, until the model starts failing. Its strategy is stretched too thin - the model is just not big enough to encode all those questions and answers, so the only way it can get good grades is to learn patterns, not answers.
This is called k-fold cross-validation - you split your data into subsets so the same model has to ace many different tests at once, and it never gets asked a question from the practice test in the real test.
A rule of thumb is that 10-fold cross-validation is the point of diminishing returns. You need 10 times the data that are required to train the model, to prevent the model from memorizing answers.
That means I need to flap my meat mittens 50,000 times to collect an appropriate training set.
So say I do that. The machine-learning model eventually passes all ten tests, and I rejoice. But that little bastard is wearing an obnoxious grin, almost as if to say, "Stupid monkey! I memorized all ten tests! Eat my shorts!" There's only one way to know for sure, and it is...
I got a fever, and the only prescription is more data.
That's right. As that pissant mass of floating-point operations snickers to itself, I look it dead in the eye, reach into my back pocket, and whip out a double-super-top-secret eleventh test.
This set of data, the sanity check, is special. Unlike the training set, the model isn't allowed to see these data while training. The model has no way to memorize the answers, because it's not allowed to see the grade. I see the grade, and if the model flunks the final exam, I drag it out back and put it out of its misery (reset and start over). If it passes, the job is done, and it gets loaded onto the glove and sent into the real world.
The sanity check is the final line of defense, and the final metric of how effectively it does the thing. Say I want my glove to be 95% accurate. That means it must score a 95 or higher on the final, or backyard pew pew. I need to put more than 100 questions on the test, because I myself might screw up and make a test that has, say, 50% fewer walking-around samples than real-world usage.
So, I think it's prudent to collect 200 more samples of each gesture, for a total of 60,000 samples, to know for sure that this thing is rock-solid.
This is gonna hurt.
Oh yeah. 1,200 copies of each sample is enough to give me RSI, not to mention the soul-eroding boredom. I estimate that I can collect about 100 samples per minute, so the entire data-set will take ten entire hours of nothing but nonstop hand-waving.
Pitter-patter, let's get at 'er.
-
Artificial Stupidity
05/05/2020 at 20:34 • 0 commentsLast log, I was riding high because my ML model was getting 95% accuracy. It actually performed decently well. Buuut...
When I walked around, the network barely worked at all. Worse, the speed and angle I was gesturing affected performance a lot. Some letters just never worked. It thought H's were N's, A's were Q's, and it straight-up ignored V's. Z's and K's were crapshoots, which is awesome when your name is Zack and you want to capture some footage for Instagram.
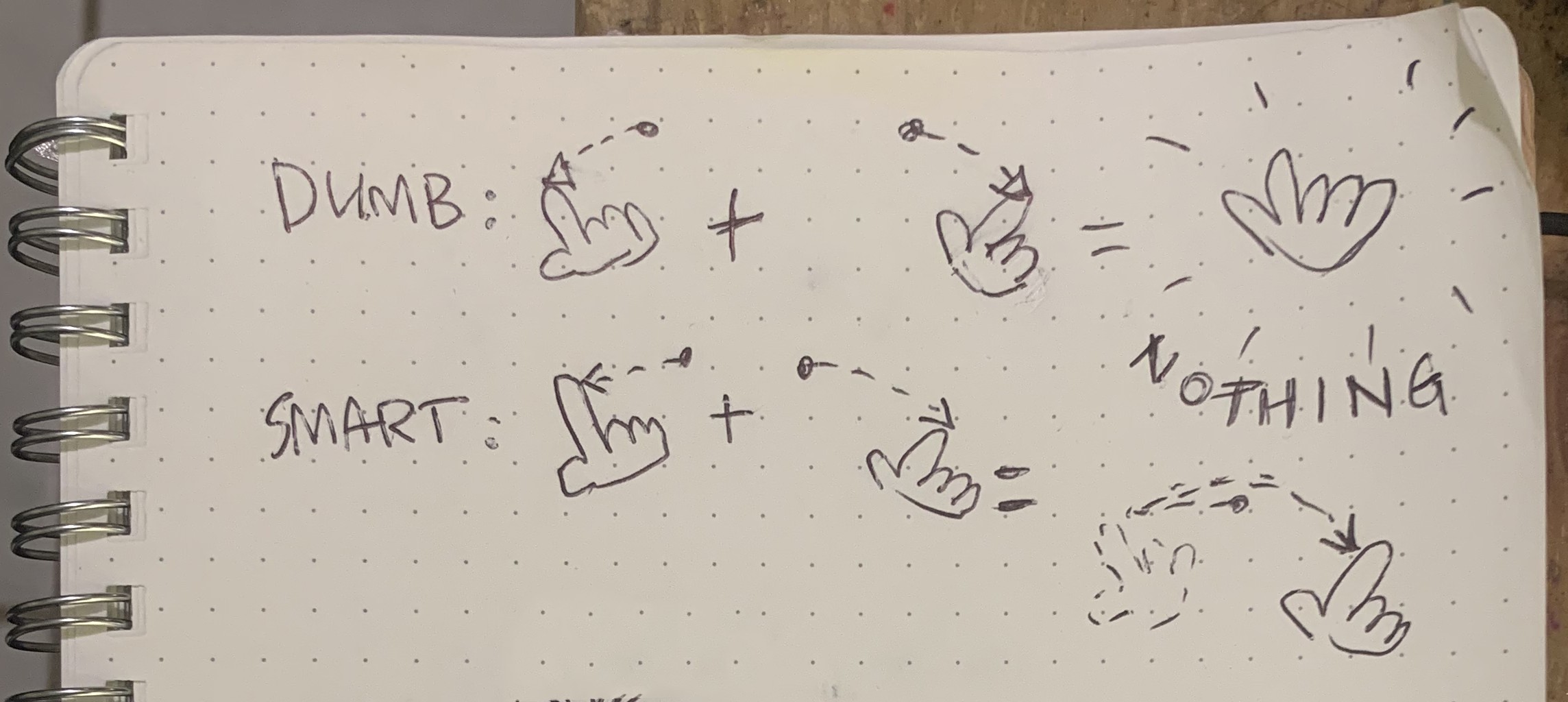
It turns out that I had made the most rookie move in machine learning - failing to normalize data. I will now punch myself in the ego for your education.
Normie Data! REEEE
Asking a bunch of floating-point math to recognize air-wiggles is hard enough, and having it also filter out timing, scaling, starting position, and more is just kicking it when it's down. Normalizing the data, or adjusting it to remove irrelevant parts, is a critical first step in any machine-learning system.
I thought I did a decent job normalizing the data. After all, the quaternions were already scaled -1 to 1, and I decimated and interpolated each sequence so every sample had 100 data points. So why didn't it work?
1) I didn't normalize the quaternions.

I read a bunch of articles and grokked that the data should have a magnitude of 1. The problem here is that each data point goes from -1 to +1. This means that in a recurrent network, a negative value then and a positive value now add to zero value. Zero values don't excite the next node at all - they do nothing. What I meant to do was excite the next node halfway between the minimum and maximum.
Instead, I should have scaled from 0 to 1, where -1 becomes 0, 0 becomes 0.5, and 1 keeps its 1-ness. Instead of canceling out the entire operation, Ugh.
I fixed that, but then discovered that...
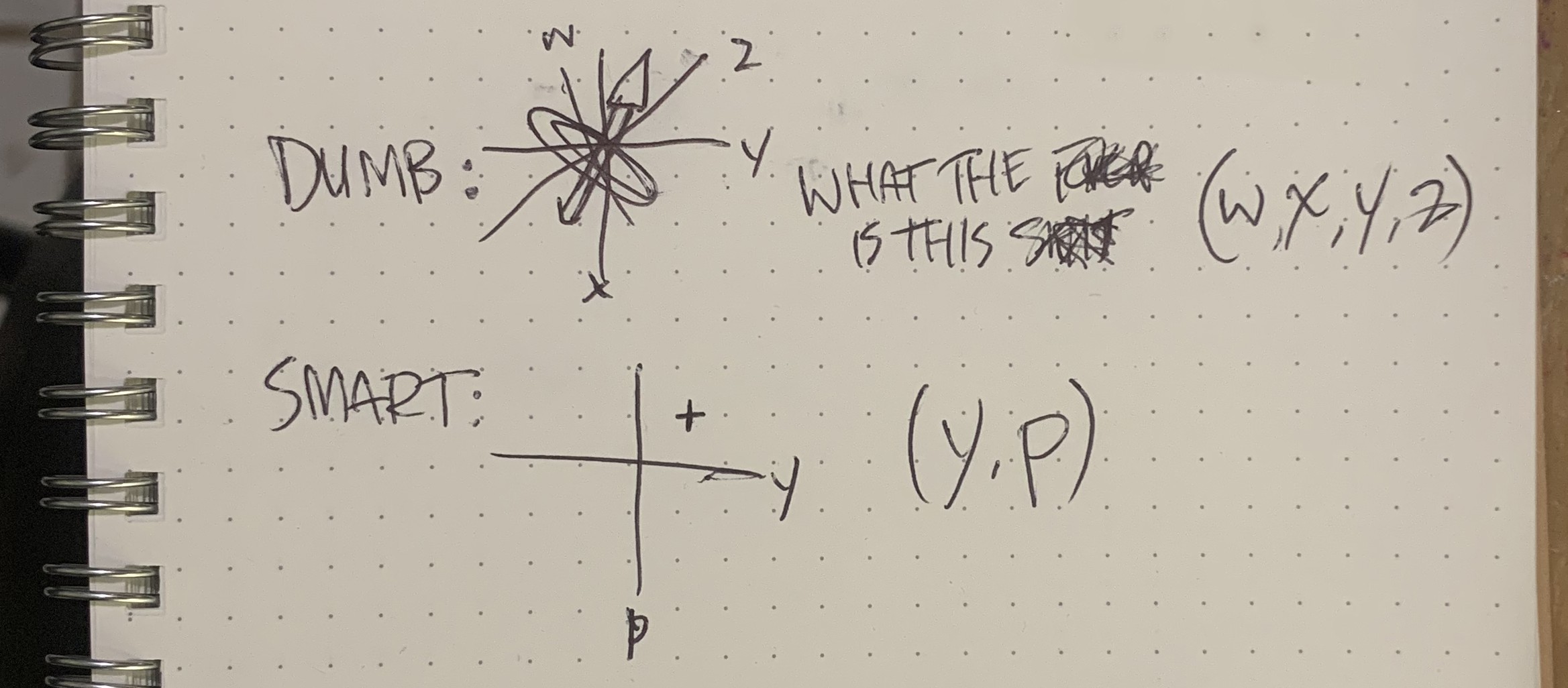
2) I fitted the wrong data.
Quaternions were a baaad choice. Not only is the math a mind-melting nightmare, but they intrinsically include rotation data. That isn't relevant for this project - if I'm swiping my pointer finger leftwards, it doesn't matter if my thumb is up or down. I failed to filter this out, so hand rotation heavily influenced the outcome.
Even stupidlier, I realized that what I cared about was yaw and pitch, but what I fed into the model was a four-element quaternion. I was making the input layer twice as complex for literally no reason. I was worried about gimbal lock, but that was dumb because the human wrist can't twist a full continuous 180 degrees. Ugh.
I switched the entire project, firmware and software, to use AHRS (yaw, pitch, and roll) instead of quaternions. Not only did steam stop leaking out of my ears, but I now had half the data to collect and crunch. Buuut...
3) I didn't normalize the timescales.
This is the one that really ground my self-respect to powder. I wrote a complex interpolation algorithm to standardize every gesture sample to 100 samples in one second. I did this by interpolating using the timestamps sent along with the data from the glove.
The algorithm worked great, but I wasted all the time writing it because it was the absolute wrong approach.
See, I care about the shape I'm drawing in the air, not the speed my finger is moving. It doesn't matter if I spend 150ms on the top half of the B and 25ms on the lower half. It's a B.
By scaling the timestamps, I preserved the rate I was drawing. This is extra-dumb because your hand moves faster at the beginning and end of the gesture. Most of my data points were when I was getting my hand moving, and slowing it down, instead of the actual gesturing part with the letter in it.
With shame in my heart, I deleted the code and replaced it with a subdivision algorithm, right out of the programming interview playbook. It worked great, but...
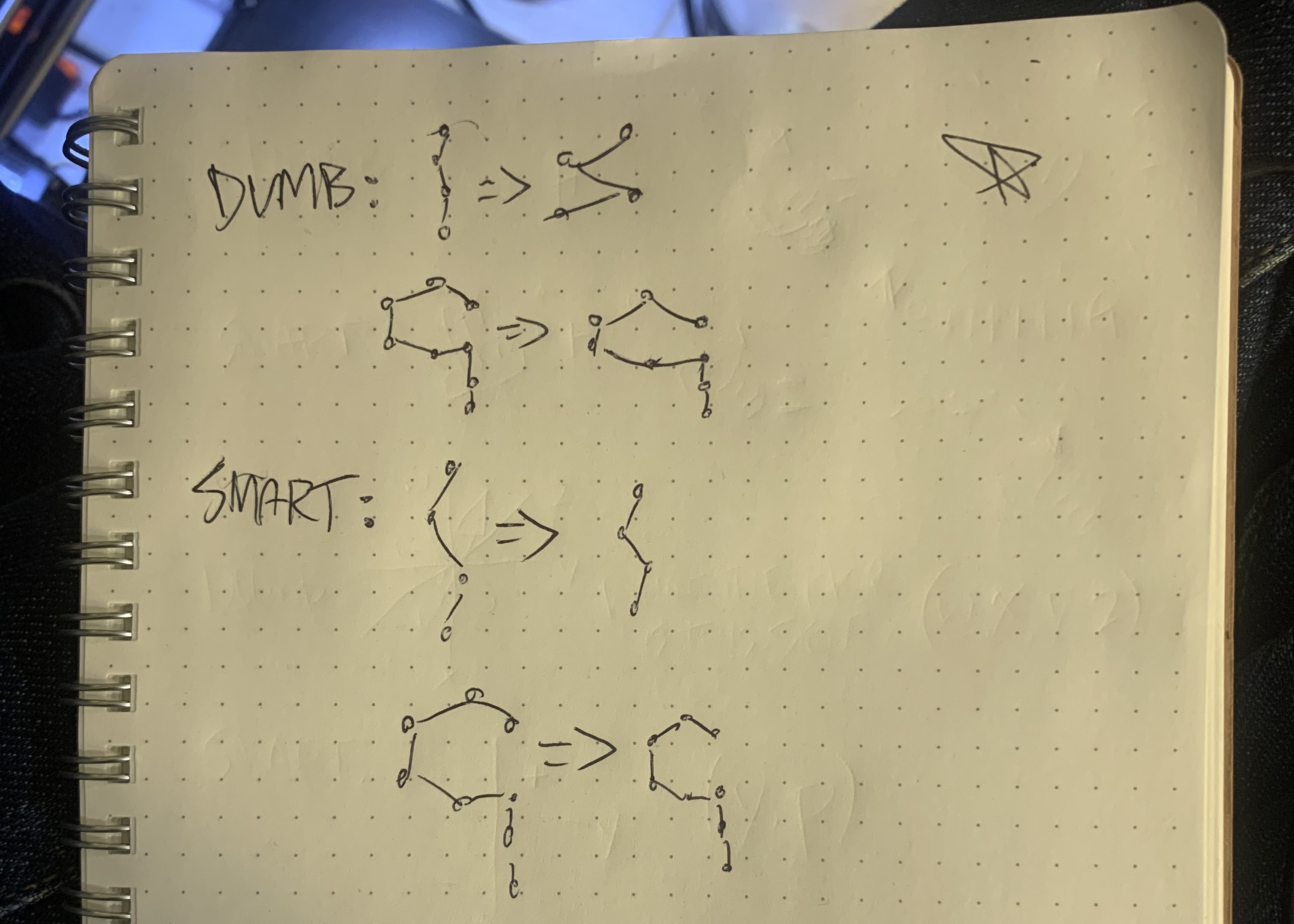
4) I scaled the data like a dumbass.
Gestures of all sizes, big and small, should recognize the same. This wasn't an issue with quats, but it does come into play with angles. I standardized each sample by finding the lowest and highest yaw and scaling each yaw accordingly, then I did the same with each pitch.
Hopefully, you just facepalmed, because that approach discards the aspect ratio, stretching and squishing each sample into a square.
This meant that the tiny yaw (left/right) variance in the letter I were multiplied until the letter looked like a squiggly Z. Lower-case Q and A were squished in the pitch direction, which eliminated the Q's downstroke. Luckily I caught this before wasting too much time, but it was dumb.
Instead, I had to find the bounding box of the gesture, and scale it uniformly so that the longer side went from 0 to 1.
Conclusion
When collecting data, make sure you know exactly what should be standardized, what should be kept, and which formats reduce the workload. If you struggle to understand a concept, like quaternions, there's no shame in switching to a substitute that actually lets you finish the project.
After all that dumbness, I finally started collecting decent data that made for great tests. Now, time to waggle my hand tens of thousands of times to collect enough data.
-
Training Day
02/05/2020 at 22:01 • 0 commentsFun fact: Everyone seems to be nuts over machine learning, but almost no one gathers their own data. My training utility isn't technically sophisticated - just Tkinter, Pillow, Numpy, and Pyserial - but apparently most ML enthusiasts haven't needed to make one.
I'm pretty proud. I haven't made a GUI since Google Glass, and this one came out pretty nice.
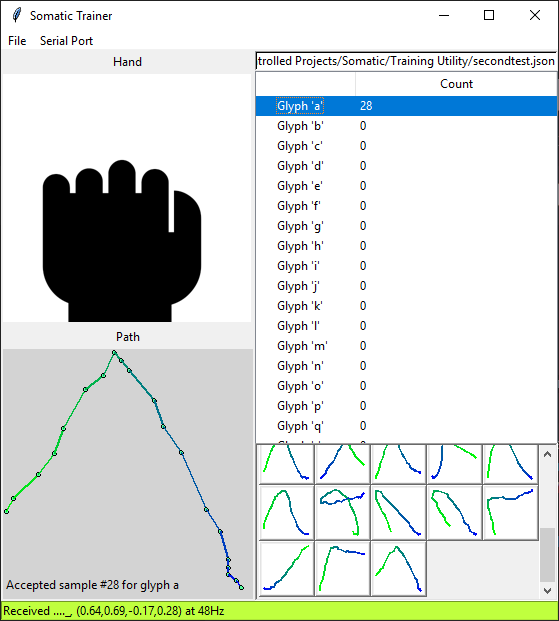
Here's what it looks like:
The idea is that I want to collect a few hundred samples of all 70 glyphs by actually drawing them in midair, the same way the glove will work in real life. That's the training data.
The left column shows the hand gesture up top and the currently-drawn path at the bottom. I made it fade from green to blue so I can easily verify the direction of the gesture. The utility automatically rejects any gesture that's too short or slow, to cut out false readings.
The right column shows the number of samples for each glyph, and the bottom has little thumbnails of each gesture. I can right-click one to remove it, which will help clean up the data.
At the bottom, you can see the status bar that shows the raw packets received from the glove, as well as the refresh rate. All samples are standardized to one second at 50Hz, but it's nice to keep an eye out for slowdowns that could affect the finished project.
I've wasted a billion hours wrangling the Android and Silverlight UI builders, so I was very surprised by the Tkinter library's productivity. The Python Image Library (packaged in the Pillow module) made the thumbnails and graphics easy, and serial comms are handled by the excellent Pyserial module. Numpy, and the Pyquaternion extension, simplifies processing the incoming quaternion data, but goddammit, quaternions are such an incomprehensible pain in the ass.
As an aside, it's nice to be able to use an up-to-date version of Python, after being stuck with 2.7 on other projects. It has some relevant improvements (TYPE CHECKING!!!) but the updated libraries are also great.
Anyways, time to collect some data. When this baby hits 14,000 samples, you're gonna see some serious stuff.
-
Give 'em a Hand
01/04/2020 at 01:51 • 0 commentsThe Supercon really loved the data glove - enough to convince me to put it online.
The project looks pretty good, but inside, it's pandemonium. Below the clean-looking case (I'm pretty proud of that, it came out great) the Somatic prototype is a mess of perfboard and sloppily-soldered dev boards. The code does basically nothing, and the training utility does even less.
But, the hardware works, and I have my tasks ahead of me. From easy to hard:
- I have code to recognize hands signs, output keystrokes, and do the gyro mouse stuff from a previous data glove. Gotta port that over to this hardware.
- Finish the training utility. This will be fed into TensorFlow to recognize gestures. I've never actually built a desktop GUI app, but the learning curve of Tkinter is pretty forgiving.
- Gather and process training data. I estimate I'll need something like 100 samples of each of the about 100 glyphs. I'll need some serious podcasts (and wrist support) to draw ten thousand letters in the air. Preprocessing should be pretty simple - the IMU itself produces unit quaternions; my job will be to normalize the sequences so they're the same length.
- Make the artificial neural network. I've never done anything close to this before, but it seems pretty straightforward. The priority is making a network that can be easily ported to the Teensy. I'm not going to train directly on the glove - it'll just run the model.
- Build custom PCB's and all that jazz to make it smaller and perform better. Normally I'd call this easy, but the Teensy 4.0's new chip is BGA and looks like a nightmare to solder with hot air.
Anyways, stay tuned, I think I'm pretty close to finishing the training utility... as soon as I can figure out how to render the quaternions and gesture path...
Somatic - Wearable Control Anywhere
Hand signs and gestures become keystrokes and mouse clicks