 Cassio Batista
Cassio Batista-
1Image Loading
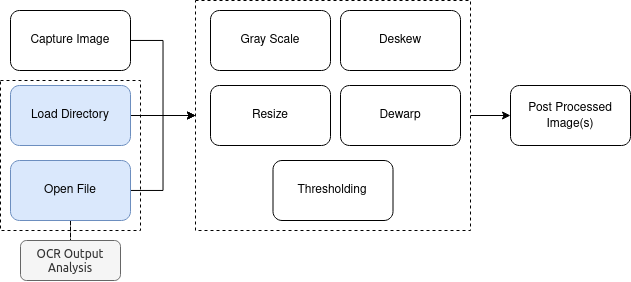
Using OpenCV, an open-source Computer Vision library, the system either captures new images using a Rapberry Pi NoIR v2 Camera, or load single files or directories via terminal parameters in order to compute the OCR accuracy with multiple images.
-
2Pre Processing Original Image
Once the image is captured, the system applies a sequence of computer vision algorithms in order to improve the quality of the picture. The main objective here is to make the text in the image as evident and recognizable as possible, which is essential to increase the OCR fidelity.
![]()
When it comes to refine OCR accuracy, we basically have two options: i) improve the quality of the camera: Pi NoIR pictures have a maximum resolution of 3280 x 2464 pixels, which is more than the necessary for a book page capture; or ii) improve the quality of the image: by pre-processing the original capture, it's possible to "facilitate" the work of the OCR engine. Even though Tesseract already has a built-in image processing system, using untreated images induces a suboptimal result. Hence, we developted a [pre] pre-processing system using OpenCV and Numpy. You can see below a chunk of code with the main parts of out image processing implementation.def get_grayscaled(image): return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) def resize(image, scale=0.5): return cv2.resize(image, (0, 0), fx=scale, fy=scale) def get_text(image, language='por'): return ocr.image_to_string(image, lang=language) def write_text(text, filename): try: with open(filename, 'w') as txt: txt.write(text) except IOError as txt: print("Couldn't open or write to file (%s)." % txt) def get_threshold(image): gray = get_grayscaled(image) reversed = gray return cv2.threshold(reversed, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] def get_angle(image): coords = np.column_stack(np.where(image > 0)) angle = cv2.minAreaRect(coords)[-1] if angle < -45: angle = - (90 + angle) else: angle *= -1 return angle def deskew(image): thresh = get_threshold(image) angle = get_angle(thresh) h, w = thresh.shape[:2] center = (w // 2, h // 2) matrix = cv2.getRotationMatrix2D(center, angle, 1) return cv2.warpAffine(image, matrix, (h, w), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)The techniques we used to process text images (books, posters, cards, etc.) prior to using OCR are show below., They are presented in the order they were applied to the images.
-
Convert Image to Gray Scale: Gray scale images uses just one channel of color, reducing the computational complexity of post analysis (RGB 3D -> Gray 1D). Also, gray images are more suitable for certain applications e.g. optical character recognition.
-
Resize Image: As gray scale converting, resizing images reduce the size of the matrix that represent the picture. In our experiments via CLI, we used a 0.5 resize factor for both width and height, which significantly reduces the number of pixels to a half.
-
Optional - Thresholding: Thresholding is the simplest method of image segmentation. From a gray scale image, thresholding can be used to create binary images (Shapiro, et al. 2001:83). Tesseract does this internally (Otsu algorithm), but the result may be suboptimal, particularly if the page background is of uneven darkness.
-
Optional - Correcting Text Skew: A skewed image is when a page has been scanned when not straight. The quality of Tesseract's line segmentation reduces significantly if a page is too skewed, which severely impacts the quality of the OCR. To address this, one must rotate the page image so that the text lines are horizontal. The CLI calculates the image angle of rotation in order to deskew the text lines.
- Optional - Dewarping Image Text: Sometimes, deskewing images doesn't produce the expected result, especially with books, labels and packages images. One of the major challenges in camera-captured document analysis is to deal
with the page curl and perspective distortions. Current OCR systems do not expect these types of artifacts, and have poor performance when applied directly to camera-captured documents. The goal of page dewarping is to flatten
a camera captured document such that it becomes readable by current OCR systems.
![1_in.png]()
Image dewarping became one of the most discussed and researched topics during the development of this project for two of reasons: i) the lack of algorithms, papers and studies about the subject: curiously, there are some dewarping algorithms contests with the objective to create and evaluate new algorithms; and ii) the complexity of perfoming such task: indeed, dewarping the original image is the most time consuming step in the system.
-
-
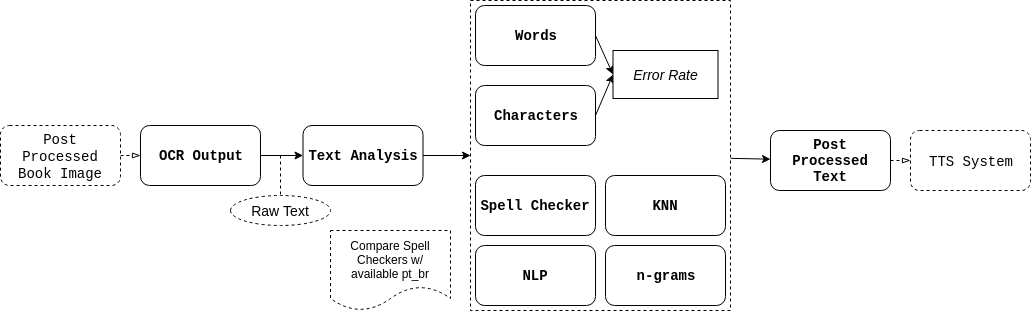
3Character Recognition and Output Evaluation
The text of the processed image is then recognized using Google's Tesseract and stored in a txt file. When we were evaluating different OCR parameters and image processing techniques we created some python scripts to compute the word and character error rate. Also, spell checkers were utilized to improve the confiability of the post processed text by replacing miss-understood words (especially the ones with diacritical marks).
![]()
-
4Text-to-Speech
Finally, Google TTS (GTTS) were utilized to produce a audible output for the user.
Automatic Reading Machine
An assistive system that takes pictures of pages containing text, and read words aloud, favoring people with visual disabilities.

Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.