Yann Guidon / YGDES
Yann Guidon / YGDES-
Depthlist v2
12/09/2020 at 22:08 • 0 commentsOne year after 27. DepthLists and I'm back on the subject. The old code is being replaced with new, better data structures, thanks to the hindsight gained since the first version. The basic principle doesn't change much but it now includes the outputs of the backwards and the DFF gates at the level 0. I also want to use a more unified memory allocation approach, similar to what I used for the sinklist, with a large chunk of memory containing all the lists in a compact sequential way.
I can ensure that the lists are well sorted by using "insertion sort" with linked lists for example, then the linked lists are transformed into normal lists. It's easy because we already know the number of gates and input ports. We don't know the maximum depth in advance though and temporary dynamic allocation seems necessary.
A new subtlety appears with the DFF and backwards gates : although they are counted as drivers along with the inputs, they are also sinks and should be considered as such as well. We want to know how many gates are traversed before reaching the DFF's input and this sink gate appears at the end side of the depthlist.
...
Some coding and thinking brought a new fresh idea and structure to the "depthlist" complex:
- Level 0 is the list of the input ports and a new list that contains the DFF and backwards gates (it's called pseudo_drivers_list, with pseudo_drivers_count elements)
- The other levels are stored in a large array that contains DutVectOut_length + gate_instance_counter elements, called depth_lists. The trick is that since it is some some sort of permutation of the original array, we can store the lists starting from index 0, while also fit the rolling list of gates to propagate/check at the top end. The array can be allocated early.
- The depth is not easy to get and must be allocated dynamically. There are two values to store for each index (starting at 1 because 0 is implicitly a different kind of data) : the count of elements in the current level, and the starting index in the depth_lists array. Once again it's redundant because it's another "prefix sum".
A nice solution is to "over-allocate" the depth-lists (by how much ?) and store the individual list sizes just before the given list. A final step will simply scan the lists and compute the prefix sum to store it in a normal array, when its size is known.
The good news is I got rid of the linked lists ! Though this makes deletion/insertion less convenient.
...
(tbc) -
Skipping the preflight check
12/07/2020 at 23:17 • 0 commentsThe last log Plot twist explains the "shadowing flaw" in the new net probing algorithm. A solution was proposed and this log tries to get the details straight.
Inspired from the CORS nomenclature, the previous solution runs a first round of checks before starting the main loop, so it's called the "preflight check".
Instead of serialising the driver's identifier, the signal sends a value that encodes the type of the driver, so 'U' would naturally mean "unconnected". This then helps the next phase to send data when partial inputs are available.
A new code path must be added, by using a special value of 0 for the shared variable multiply_pass.
Fine so far but...
Why did I go from "OR" to "AND" logic to propagate the update event ? It simplifies the logic because I don't have to check if the output value has already been sent.
This is because now, setting the output also modifies the "decumulator" and it would be out of sync if more than one event triggers it.
In fact the "preflight check" can be skipped if each input and output has a flag to indicate that the corresponding signal has been processed (accumulated or decumulated). I know it would take a bit more room but... It's only 5 bits for the LUT4 and the previously proposed solution would use more. The output port is scanned manually at the end of each cycle so it's not affected, unlike when a preflight check is used.
There are two new challenges to solve : how/where to solve the flags, and when/how to toggle them.
- There are 5 flags (max.) to store for each gate (as noted above, the output ports are explicitely scanned so don't need a flag). These flags fit nicely in the bulky histogram array.
- Each flag is set on the first valid condition, but reset is not as obvious because there is the risk to fall back into the same trap as before (the reset ending up not being propagated due to AND/OR logic corner cases). The solution seems to be a simple shared flag "probe_phase" that alters the algorithm depending on what is required.
- When "probe_phase = 0" then all the flags are cleared (if already set) and the output is set to 'U'. That's it. At this point it is possible to add a warning that an input is not connected but this is not critical for this algorithm.
- When "probe_phase = 1" then
- if output is not already set, set it and set the flag
- if each input is not already flagged, register it and set the corresponding flag
That should work...
.
.
.
AAaaaannnd... It works ! Amazingly with pretty few hicups and few compile errors on the first try. Go get it : LibreGates_20201209.tbz !
The probe is enabled for 4 out of the 6 tests and even spotted a flaw in the BigLFSR one (which I will leave for the lulz because it doesn't really matter). I should benchmark its performance now. The next step will be to reimplement the depthlist system.
-
Plot twist
12/06/2020 at 13:45 • 0 commentsThe new probe system works nicely ! Except when it doesn't... This happens when any sign of backwards connection appears, even when a backwards gate is inserted !
This is caused by the limitations in the way one can drive an entity's output : it has to be triggered by at least a change of one input. The new probe algorithm takes a "safety shortcut" by changing the output only when all the inputs have a valid value. This effectively prevents the gate's output from propagating the "toggle signal" when one input is tied to a backwards gate, which has not yet received the toggle signal...
It's a chicken&egg problem that would not exist if a gate's output was directly controllable by an external code. But the other cause is the AND condition for the new algorithm. It is required to ensure the speed in most circumstances and it performs great in the pure-boolean INC8 and ALU8 units. The "corner cases" test miserably fails though. Worse : all the logic cone after the first gate that receives a backwards signal is also "shadowed" because the trigger signal can't propagate.
And because of the "shadow", it's not possible to know if a "disconnected" gate is really disconnected, receives a backwards signal OR is in the shadow of a backwards-fed gate.
The answer to this question can come from a "preliminary pass" that scans/propagates through all the circuit but instead of sending a chunk of the driving gate's number, it sends the type of the driving gate: input, boolean, backwards... This first pass will already solve the question of which inputs are not connected, so these gates can still propagate other trigger signals during the main probing algorithm.
The new pre-pass requires storage of (temporary ?) extra data for each input (gate & output port), which can be :
- not connected - 'U'
- input port
- gate
- backwards
- (eventually a sequential gate ?)
This can be a single std_logic variable, but it must be allocated somewhere. It can be temporary because unconnected inputs cause the rest of the program to fail, and once the netlist is built, checking the type of the driver is easy :
- input ports are non-positive driver numbers,
- gates, including backwards, have a positive driver number,
- gates have a enum_gate_kind that can be looked up.
(to be continued)
-
Strong typing snafu
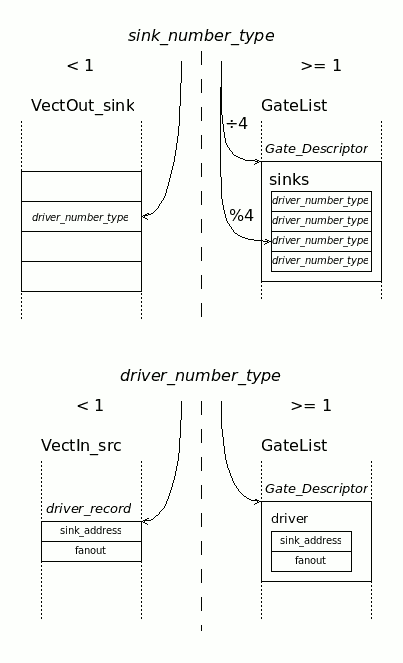
12/01/2020 at 16:29 • 0 commentsVHDL is a strongly typed language : you can define types that, though similar, can't intermix unless you cast them. This is good™ for code robustness. As long as you get them right. My recent code used strong typing to prevent mixing two similar-looking types, that I finally illustrated on this diagram:
![]()
The two types share the "signedness" trick where a number less than 1 indicates a port. The differences are significant though:
- One points to an input while the other points to an output.
- A positive sink number must also specify the gate's input number, encoded in the 2 LSB.
At one point I must have been confused and the corresponding diagram made no sense... sink_number_type was used instead of driver_number_type and sinks would point to sinks. That's a virtue of thorough documentation: it helps catch logic errors :-)
The above diagram and the one below are the keys to understand how the netlist is structured. Each sink points to their driver, and each driver points to one sink or a list of sinks. Easy to say, delicate to code :-)
![]()
So the confusion is now cleared and I can resume development.
.
.
.
And the result is there : LibreGates_20201202.tbz
-
A smarter sinks list allocator
11/28/2020 at 09:29 • 0 commentsI don't know why I heard about the radix sort algorithm only recently. I have seen it mentioned, among many other algorithms, but I had not looked at it, leaving this subject to the sorting nerds. Until I watched this :
This is very smart and useful but I'm not building a sorting algorithm now. However I can reuse some of these tricks to build, or compile, a semi-dynamic data structure (write-only once) that is both compact and efficient.
Let's go back to my first version of the netlist probe:
Each signal driver must manage a list of its sinks and I first implemented it as a linked list, borrowing some words of memory from each sink structure. Memory-wise, the memory overhead is minimal because one sink can be linked to only one source. The "pointer" of the linked list is both the desired value and the pointer to the next sink (unless it's the last). It avoids any malloc() and meshes directly in the existing structures, however in return they become more complex and harder to mange. The insertion and scan algorithms are a bit cumbersome...
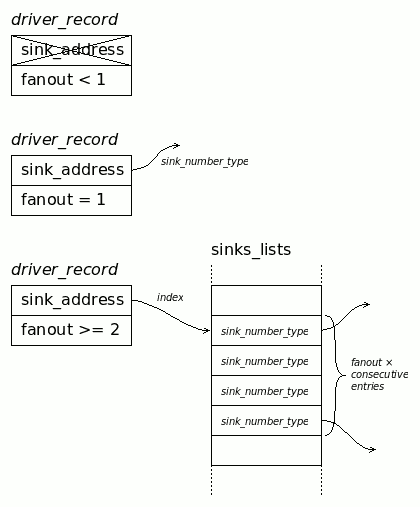
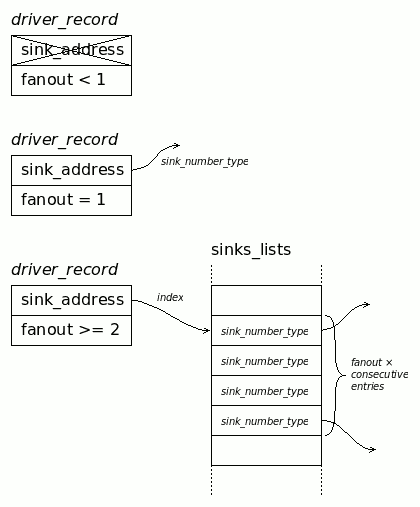
The new version allocates a single chunk of memory to store simple lists of sink addresses (called sinks_list).
This allows the sink descriptors to be a single number, which is the address of the source/driver. It's easy to manage. As shown in log 3. Rewrite, the driver only contains a fanout number and an address:
- If the fanout is 1, the address is a direct sink address.
- If the fanout is 2 or more, the address is an index in the unified array of addresses, pointing to fanout× contiguous sink addresses.
![]()
Building an appropriate compact structure in one pass is not impossible but would require many inefficient re-allocations. However, with 3 passes, it's easy !
- After the first netlist scan, all the drivers have their fanout count updated.
- A second pass creates a counting variable, then for each driver with more than 1 sink, the fanout is added to the counter, which is then put in the address. It's called the "prefix sum"
- The large memory chunk can be allocated because we know exactly how many items it will contain, and the intermediary values of the counter point just beyond the end of each sub-list. The third pass re-scans all the sinks, check the driver, then (if fanout > 1) get the index, decrement it and finally store the sink address to the main list array. As explained in the video, everything falls into place neatly because pre-decrementing ensures that the last write it to the first element of the list.
With this method, there are more simpler loops but each lookup is faster, creating fewer cache faults for example.
This wouldn't have been considered possible if I had never watched the video above, and I think I'll apply this method in more places :-)
-
Wrapper rewrite
11/21/2020 at 19:39 • 0 commentsGood news everyone !
The benchmarking results are encouraging and made possible thanks to a new, rewritten version of the wrapper, which now even handles some essential generics ! You can expose generics of integers and string-based types, including std_logic, text and SLVx.
The core of this tool relies on GHDL's XML output, which is then parsed by a crude bash script. This is part of the new release :-)
-
Benchmarking results
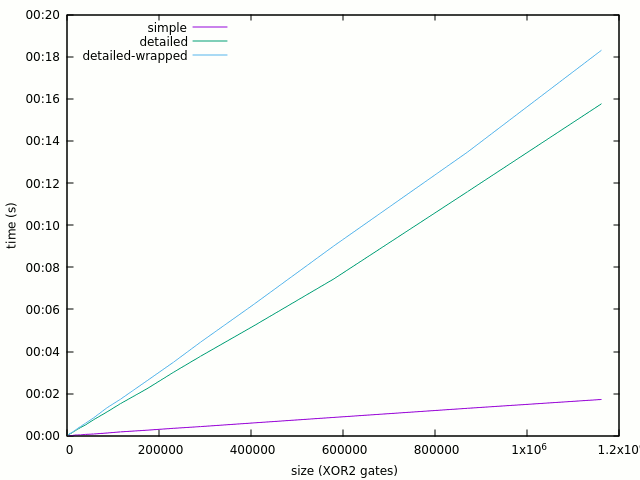
11/20/2020 at 17:27 • 0 commentsThe results are finally available !
[yg@localhost test6_bigLFSR]$ ./test.sh Simple gate version setup (RAM+time) : 290 4260 0:00.00 580 4528 0:00.00 1160 4800 0:00.00 2030 5576 0:00.00 2900 6132 0:00.00 5800 8272 0:00.01 11600 12296 0:00.02 20300 18568 0:00.03 29000 24744 0:00.05 58000 45264 0:00.09 116000 86364 0:00.18 203000 148588 0:00.30 290000 210440 0:00.44 580000 417476 0:00.91 1160000 831120 0:01.77 2030000 1451852 0:03.11 Detailed gate version setup (RAM+time) : 290 5480 0:00.00 580 6652 0:00.01 1160 8668 0:00.01 2030 12052 0:00.03 2900 15336 0:00.04 5800 26764 0:00.08 11600 49428 0:00.16 20300 83392 0:00.28 29000 117340 0:00.39 58000 230732 0:00.79 116000 457372 0:01.53 203000 797488 0:02.70 290000 1137588 0:03.81 580000 2270924 0:07.51 1160000 4538012 0:15.17 2030000 7938396 0:27.71 Benchmark : OK
I wanted to test several things :
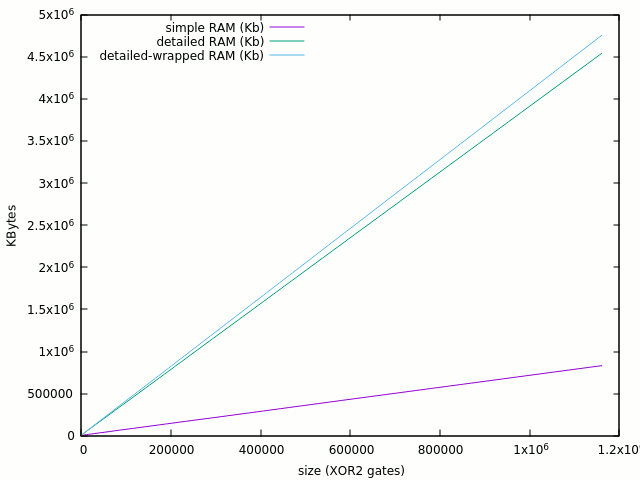
- Time and RAM are roughly linear so it's a good news. Note that this is only the setup performance.
- Setup time is 10× with the detailed version, and I don't even run an iteration !
- The detailed version uses about 6× more RAM, but that amounts to about 4KB for a single gate !
This means that with 16GB RAM, it is possible to simulate approx. 20M gates and analyse 3M gates.
You can run this test manually with the newer archives. It's a stress test for the system and the behaviour will change depending on your computer configuration. I don't assume your CPU speed or RAM size, so run it cautiously.
---------------------------------------Update 20201121:
I managed to run the design inside the wrapper, and the overhead is marginal (5% size, <10% time)
290 5516 0:00.00 580 6808 0:00.01 1160 9200 0:00.01 2030 12676 0:00.03 2900 16228 0:00.04 5800 28088 0:00.08 11600 51880 0:00.17 20300 87528 0:00.29 29000 123120 0:00.41 58000 241696 0:00.78 116000 479028 0:01.55 203000 835028 0:02.78 290000 1191172 0:03.92 580000 2377824 0:07.98
The graphs will be auto-generated if you have installed gnuplot on your system.
![]()
![]()
I still have to perform dynamic comparisons and I have not even started re-implementing the gates probes.
Anyway the 10x speed&size gain with the "simple" version vindicates the choice and efforts to make 2 versions.
-
Benchmarking with a HUGE LFSR
11/16/2020 at 08:57 • 0 commentsAfter I solved the weird issues of logChasing a "unexpected feature" in GHDL, it's time to put the lessons to practice and implement that huge fat ugly LFSR. It's not meant to be useful, beyond the unrolling of many, many LFSR stages and see how your computer and my code behave. So I created test6_bigLFSR/ in the project.
The LFSR's poly is finally chosen, thanks to https://users.ece.cmu.edu/~koopman/lfsr/index.html which contains a huge collection of primitives. For 32 bits, I downloaded 32.dat.gz (186MB) which expands to 600MB. It's huge but practical because you can grep all you want inside it :-) The densest poly is 0xFFFFFFFA, which is also the last. It contains 29 continuous XORs, which makes coding easy !
For a quick test, I wrote lfsr.c which helps visualise the behaviour. The code kernel is a 2-steps dance, with rotation followed by selective XORing.
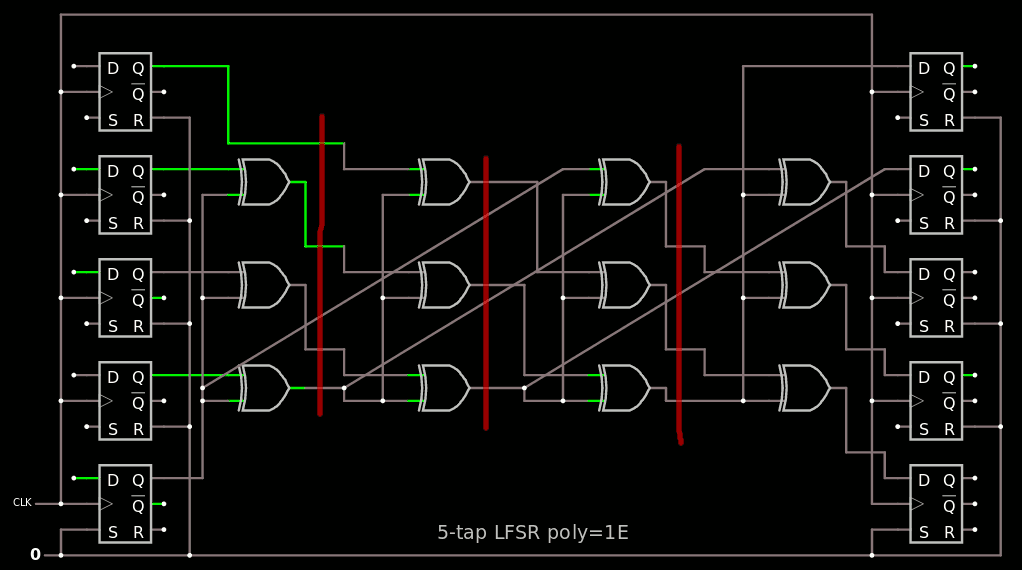
U32 lfsr() { U32 u=LFSR_reg; if (LFSR_reg & 1) u ^= LFSR_POLY; LFSR_reg = (u >> 1) | (u << 31); return LFSR_reg; }To help put this code in perspective, I also created a small LSFR with circuitjs using a 5-tap with another ultra-dense poly 0x1E.
![]()
One of the subtleties of LFSR poly notation is that the MSB (which is always 1) describes the link from the LSB to the MSB and does not imply a XOR gate.
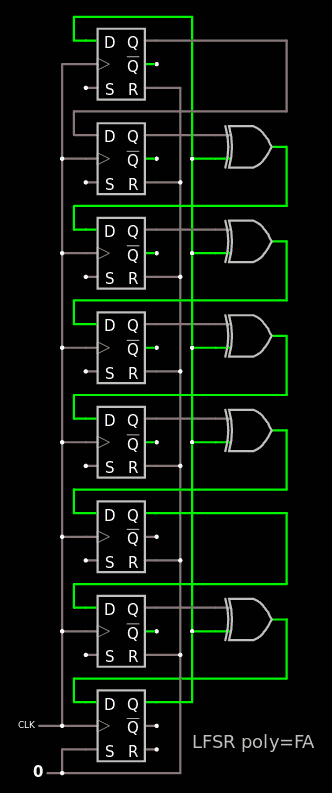
Unrolling the LFSR is pretty easy witch copy-paste. It is however crucial to keep the connections accurate.
![]()
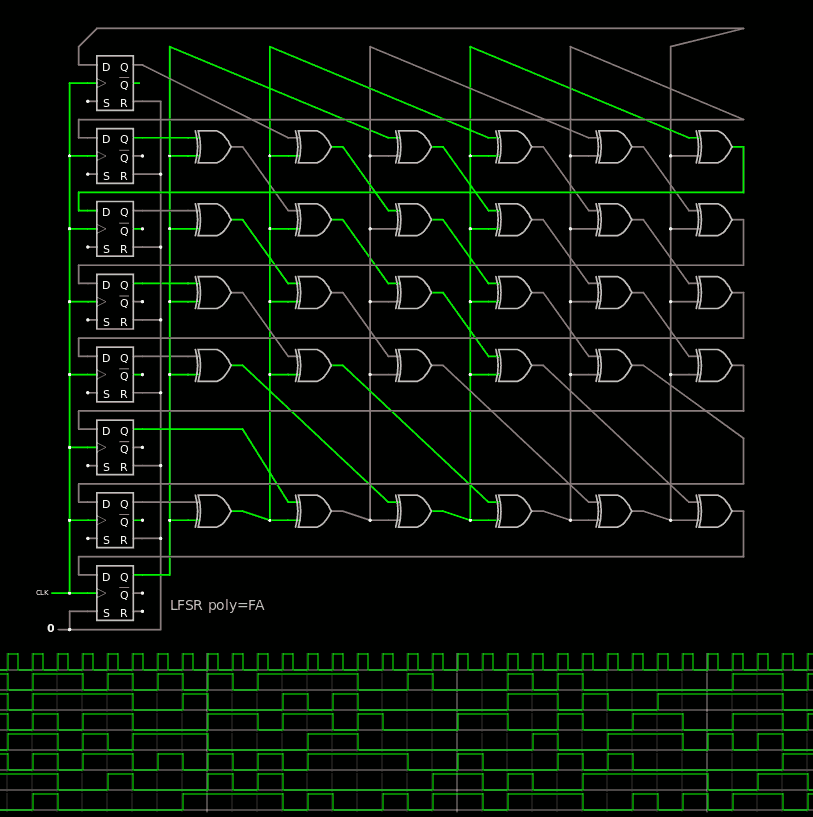
Each column of XOR2s has their own 5 signals so all is fine and should work. However we have seen already that GHDL has some issues with massive assignations, a shortcut is necessary. It's easy to spot when we move the wires around : there is no need to copy a stage to the other, just get the value from the appropriate previous stage directly.
![]()
Still 5 wires between each stage but only 3 need to be stored, the others are retrieved "from the past". From there the rule is obvious : the benchmark needs only as many storage elements as there are XOR gates, which is 29 for the 0xFFFFFFFA poly. The new issue now is that the 0x1E poly is not totally like 0xF...A : there is one bit of difference. I will now illustrate it with a reduced version 0xFA and extrapolate from there. Here it is with circuitjs:
![]()
By coincidence, 0xFA is also a primitive poly so it also provides a 255-cycles loop, just try it ! The 32-bits implementation will simply add 6×4 consecutive XORs to the circuit.
Unrolling is very similar. The critical part is to get the connections "right". Fortunately, the only difference is the absence of a XOR just above the LSB, which is translated by sending the result to the cycle after the current cycle. The resulting circuit is :
![]()
Note: there are 2×3=6 stages, while the LFSR has a period of 255=3×5×17 so the resulting circuit still has a period of 255. Not that it matters but 1) it's good to know in case you encounter this situation 2) it motivates me and brings challenging practical constraints into the benchmark :-)
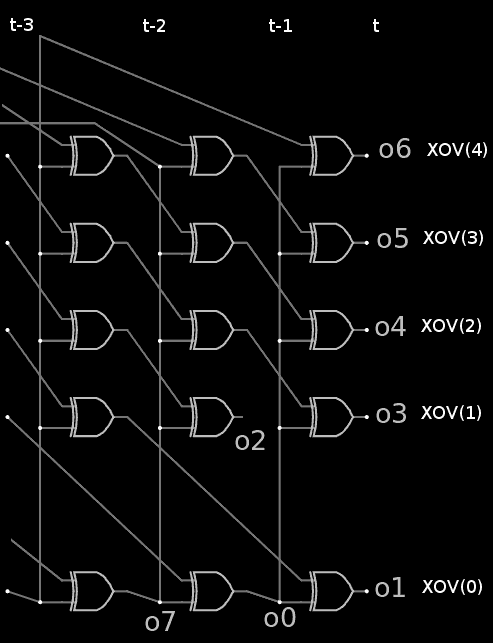
So all there is to do now is to add as many taps as necessary to get back to 0xFFFFFFFA. Oh, and also deal with the initial and final taps... So let's map the 32 taps to the 29-xor vector, called XOV, at time t:
- All gates receive one signal from XOV(t-1)(0)
- The other signal comes from t-1, t-2 and t-3:
- For XOV(t)(0) : XOV(t-2)(1)
- For XOV(t)(1 to 'last-1) : XOV(t-1)(2 to 'last)
- For XOV(t)('last) : XOV(t-3)(0)
This list of spatio-temporal links is illustrated below:
![]()
From the theory point of view, this shows how the Galois and Fibonacci structures are 2 ways to express the same thing or process:
- The Galois performs in parallel, all the elements are available for one point in time.
- The Fibonacci structure is serialised, with only one value changed but with visibility into the "past", the previous values.
The circuit described here is in the weird crossover region between these approaches. The above list shows how to wire the XOR gates and the outputs.
Connecting the inputs is a bit less trivial though.
-
Completeness of a simple heuristic
11/16/2020 at 04:38 • 0 commentsThe archive contains several tests, including some exhaustive fault injection scans. The scan algorithm ignores all the gates with fewer than 4 inputs because
- No-input gates are constants and are not really implemented in ASIC. Nothing more to say about it.
- 1-input gates can only be inverters or buffers and they amount to a wire: the logic value is propagated (even if inverted) but if the gate is altered, it then behaves like a fixed value (a no-input gate) which can be detected.
Let's consider a gate BUF ( input A, output B) with LUT2(0,1):
- altering bit 0 will flip the 1 to 0, giving the LUT(0,0) and working like a GND,
- altering bit 1 will flip the 0 to 1, giving the LUT(1,1) and working like a VCC.
So as long as the A input is toggled, the Y output will change (or not if there is a fault). This change is propagated by
- output ports, or
- gate sinks which will in turn toggle output ports.
In conclusion, only gates with 2 or more inputs need a "LUT bit flips" to check the circuit.
This is a stark contrast with verification methods from the 60's where logic was wired (often manually) and the connexions themselves were delicate. Any fault needed to be identified, located and fixed, so the automated systems focused on the observability of each wire, sometimes forcing the addition of extra "observability wires" to circuits.
This old method has been carried over to IC design but the needs have changed: we only need to know if a circuit works correctly, we don't care much about why or where is fails (except for batch reliability analysis) so there is no need to focus on the wires.
However, some inference algorithms are shared because we still have to determine 2 things:
- How to observe a gate's output
- How to force a gate's input to a given value
This is where things will be difficult.
-
Polishing and more bash hacking
11/12/2020 at 11:35 • 9 commentsBefore digging too deep into the netlist extractor, I wanted to review and massage the files a bit. @llo helped and installed the latest GHDL on Fedora over WSL: several warnings uncovered some variable naming issues, now solved. Thanks Laura !
The archive seems to be almost easy to use, but speed could still be better. Building the library is essentially linear, but the various tests could be run in parallel. It does not matter much because they are pretty short, except for the longest step in ALU8 where all the 500+ faults are injected, and it takes a while... The fault verification of INC8 could also use less time if all 4 cores could run simultaneously in this "trivially parallel" application.
I still don't want to use make. There are other paralleling helpers such as xargs or GNU parallel but they create too many complications for passing information back and forth. I also want to avoid semaphores, critical sections or locks... and I finally found the right ingredients using only bash! Here is the structure:
# if NBTHREADS is not set or invalid, then query the system [[ $(( NBTHREADS + 0 )) -eq 0 ]] && NBTHREADS=$( { which nproc > /dev/null 2>&1 ; } && nproc || grep -c ^processor /proc/cpuinfo ) echo "using $NBTHREADS parallel threads" function TheWorkload () { echo "starting workload #$1" sleep $(( (RANDOM % 5) + 1 )) echo "end of workload #$1" } { threads=0 for i in $( seq 1 20 ) do threads=$(( $threads + 1 )) echo "loop #$i, $threads running threads" TheWorkload $i & if [[ $threads -ge $NBTHREADS ]] ; then echo "waiting ..." wait -n threads=$(( $threads - 1 )) fi done wait echo "End of script !" } 2> /dev/null # hide bash's termination messagesSomething is still missing: the loop must stop if one workload fails. It's quite delicate with more sophisticated tools but in bash, it's as easy as detecting the fault and break the loop. This leads to this new version:
[[ $(( NBTHREADS + 0 )) -eq 0 ]] && NBTHREADS=$( { which nproc > /dev/null 2>&1 ; } && nproc || grep -c ^processor /proc/cpuinfo ) echo "using $NBTHREADS parallel threads" err_flag=0 function TheWorkload () { echo "starting workload #$1" sleep $(( (RANDOM % 5) + 1 )) echo "end of workload #$1" # make the 12th run break the loop [[ "$1" -eq "12" ]] && { err_flag=1 echo "$1 reached !" } } { threads=0 for i in $( seq 1 20 ) do threads=$(( $threads + 1 )) echo "loop #$i, $threads running threads" TheWorkload $i & if [[ $threads -ge $NBTHREADS ]] ; then echo "waiting ..." wait -n && { echo "Got an error !" ; err_flag=1 ; break ; } [[ $err_flag -eq "1" ]] && { echo "found an error !" ; break ; } threads=$(( $threads - 1 )) fi done wait [[ $err_flag -eq "0" ]] && { echo "it worked." } || echo "premature termination" } 2> /dev/null # hide bash's job termination messagesSince everything is controlled by a single loop in the script, and the flag can only be written by the workload, there is no risk of race condition, so no need of semaphore or what else... The only tricky part is to ensure that the remaining tasks, have to complete and check their errors too.
I have seen other similar examples that use the jobs command to list the spawned threads but there is the risk of catching sub-sub-threads if the workload forks... Using a thread counter is faster (no fork-exec of other tools) and limits the scope of the test, which removes interferences.
There are more issues to solve such as adapting the result of each invocation of the GHDL-generated binary. But another place where significant time can be saved is during the simulation setup: the binary is restarted all the time despite only tiny changes are made. The VHDL simulation system must also be updated...
--------------------------------------------------------------------------
Hmmm it seems I botched the script and made wrong assumptions. It is not possible to send a value back to the main script once a workload has forked. Yet this code works because the return value is available from wait:
err_flag=0 function TheWorkload () { echo "starting workload #$1" sleep $(( (RANDOM % 5) + 1 )) echo "end of workload #$1" [[ "$1" -eq "19" ]] && { echo "$1 reached !" } # the return value here indicates success } { threads=0 for i in $( seq 1 20 ) do threads=$(( $threads + 1 )) TheWorkload $i & if [[ $threads -ge $NBTHREADS ]] ; then wait -n && { echo "Got an error !" ; err_flag=1 ; break ; } threads=$(( $threads - 1 )) fi done wait && { echo "Got a late error !" ; err_flag=1 ; } } 2> /dev/null # hide bash's job termination messages [[ $err_flag -eq "0" ]] && { echo "it worked." } || echo "premature termination"It is able to check for "late errors" but I can't easily send other values back from the workload. The err_flag is updated only from the main loop. Yet I'd like to collect statistics from the workloads.
--------------------------------------------------------------------------
sam. nov. 14 06:45:42 CET 2020
The new archive reduces the whole test time from 75s to 42s ! It makes use of all available CPUs for several parallel tests. More needs to be done but I'm glad I significantly shortened the tests.
Go get the latest archive !
Libre Gates
A Libre VHDL framework for the static and dynamic analysis of mapped, gate-level circuits for FPGA and ASIC. Design For Test or nothing !