ziggurat29
ziggurat29-
Dockerizing the FTP Daemon
11/20/2020 at 16:27 • 2 commentsSummary
I add another dockerized service to the collection -- this one based on pure-ftpd.
Deets
Usually I prefer SCP to old-school FTP, but I still find FTP handy for sharing things in a pinch with others without having to create a real system account or walk folks through installing additional software.
FTP is an archaic and quirky protocol. Hey, it's ancient -- from *1980* https://tools.ietf.org/html/rfc765. Here, I'm going to support PASV, virtual users, and then also TLS for kicks as well.
The ftp daemon I am using here is 'pure-ftpd', which has been around for a while and is respected. There does not seem to be a curated docker image for this, so as with fossil SCM, I will be cooking up a Dockerfile for it. Unlike fossil, this will be an independent service running via systemd.
Most of the work in this exercise is understanding pure-ftpd, and it took me about 3+ days of work to get to this point. What follows is the distillation of that, so I will cut to the chase and just explain some of the rationale rather than walking through the learning experience here.
First, I make a Dockerfile. This will be a multistage build.
Dockerfile:
######################## #build stage for creating pure-ftpd installation FROM alpine:latest AS buildstage #this was the latest at the time of authorship ARG PUREFTPD_VERSION="1.0.49" WORKDIR /build RUN set -x && \ #get needed dependencies apk add --update alpine-sdk build-base libsodium-dev mariadb-connector-c-dev openldap-dev postgresql-dev openssl-dev && \ #fetch the code and extract it wget https://download.pureftpd.org/pub/pure-ftpd/releases/pure-ftpd-${PUREFTPD_VERSION}.tar.gz && \ tar xzf pure-ftpd-${PUREFTPD_VERSION}.tar.gz && \ cd pure-ftpd-${PUREFTPD_VERSION} && \ ./configure \ #we deploy into /pure-ftpd to make it easier to pluck out the needed stuff --prefix=/pure-ftpd \ #humour is a deeply embedded joke no-one would see anyway, and boring makes the server look more ordinary --without-humor \ --with-boring \ #we will never be running from a superserver --without-inetd \ --without-pam \ --with-altlog \ --with-cookie \ --with-ftpwho \ #we put in support for various authenticator options (except pam; we have no plugins anyway) --with-ldap \ --with-mysql \ --with-pgsql \ --with-puredb \ --with-extauth \ #various ftp features --with-quotas \ --with-ratios \ --with-throttling \ --with-tls \ --with-uploadscript \ --with-brokenrealpath \ #we will have separate cert and key file (default is combined); certbot emits separate ones --with-certfile=/etc/ssl/certs/fullchain.pem \ --with-keyfile=/etc/ssl/private/privkey.pem && \ make && \ make install-strip #now the entire built installation and support files will be in /pure-ftpd ######################## #production stage just has the built pure-ftpd things FROM alpine:latest AS production COPY --from=buildstage /pure-ftpd /pure-ftpd RUN apk --update --no-cache add \ bind-tools \ libldap \ libpq \ libsodium \ mariadb-connector-c \ mysql-client \ openldap-clients \ openssl \ postgresql-client \ tzdata \ zlib \ && rm -f /etc/socklog.rules/* \ && rm -rf /tmp/* /var/cache/apk/* \ #forward log to docker log collector && mkdir -p /var/log/pure-ftpd \ && ln -sf /dev/stdout /var/log/pure-ftpd/pureftpd.log \ # setup ftpgroup and ftpuser; explicitly use 1001 just to match what I'm using on the host (can I do this in config instead?) && addgroup --gid 1001 -S ftpgroup \ && adduser --uid 1001 -G ftpgroup -S ftpuser -h /home/ftpusers -s /sbin/nologin #these avoid having to specify long command lines for tools like pure-pw ENV PATH="/pure-ftpd/bin:/pure-ftpd/sbin:${PATH}" \ PURE_PASSWDFILE=/pure-ftpd/etc/pureftpd.passwd \ PURE_DBFILE=/pure-ftpd/etc/pureftpd.pdb #from time-to-time you will want to shell in to update the virtual users; e.g.: # pure-pw useradd easy123 -m -u ftpuser -d /srv/ftp/virtual/easy123 #(unless you have the pure-pw tool on your host, and can do it from there) #the 30000-300009 are for PASV; remember to specify a value for ForcePassiveIP in the .conf if you are behind NAT EXPOSE 21 30000-30009 # startup CMD pure-ftpd /pure-ftpd/etc/pure-ftpd.confThis one builds quickly -- just a few minutes. The build stage image is about 450 MiB, but the production stage is about 60 MiB. Better!
I documented some of the build options in the 'configure' step, but I do want to point out that --with-certfile and --with-keyfile are done the way they are because the default for pure-ftpd is to assume that all the certs and also private key are contained in one file. This is a hassle for us, because our certbot (from earlier) will be creating separate files. So either I would need some step added to concatenate those, or rather I can explicitly tell pure-ftpd that they are separate. The latter seemed the easier way to go. The paths aren't critical -- it's just what an openssl installation would use by convention, and I have the flexibility to mount wherever I want, anyway.
There is a wart in this spec: the 'addgroup' and 'adduser' specify specific IDs to use. This is because of the vexing permissions issue with docker and bound filesystem objects: The ID space on the host is disjoint from the ID space in the container. Many times this doesn't matter if the program in the container is running as root (the default), but here the process is running as a well-known user. I also had this problem with the PHP-FPM processor, but there it was easier to solve since the config allowed specifying the user:group under which to run (and numerically, at that). I have not found such an option with pure-ftpd, alas. I'll try to revisit this in the future; maybe I can do some magic with env vars from the host, and a script in the container to diddle those values at startup.
Pure-ftpd supports 'virtual users' and that's really the only way I plan on using it. These virtual users are separate entities from the conventional systems users, and their identity is maintained in a separate database. Two, actually. There's a text-based passwd-esque file conventionally named 'pureftpd.passwd' and a binary equivalent named 'pureftpd.pdb'. You use a separate tool 'pure-pw' to add/remove/update details of users. This tool will update the text version, then you are meant to issue a separate command to transfer that data into the binary version.
pure-pw mkdb pure-ftpd.pdb -f pure-ftpd.passwdThe daemon only uses the binary version. Tedious! It must have been considered tedious by the authors as well, because I eventually found a switch '-m' that causes the binary version to be updated when performing add/remove/update operations on the text version.
The build stage builds the daemon with the '--prefix' option. This causes all the built artifacts to be installed into a sub-directory of your choosing, rather than into system locations such as /bin and /sbin. Using this makes copying into the production stage much easier, but it also makes specifying the path to the components a bit more tedious. A few environment variables are modified/added to help with this. It's useful to note that the ENV directive uses the multi-value setting form, instead of one ENV per variable. This is considered a 'best practice', because the ENV creates another 'layer'. Well, so says the docs https://docs.docker.com/develop/develop-images/dockerfile_best-practices/#env , at least. Updating the path is welcome, and the two variables PURE_PASSWDFILE and PURE_DBFILE seem to at least sometimes be used by the tools and thereby avoid needing to explicitly specify those on the command line.
This image has a bunch of ports to expose on the host, thanks to the vagaries of FTP. Note that the EXPOSE directive is purely for documentation; it doesn't cause anything to actually be exposed. You still have to explicitly do that when creating the container on the host.
Lastly, the CMD directive causes the pure-ftpd daemon to be launched in accordance to a config file. The pure-ftpd docs seem to suggest that its authors prefer to do this via the command line, but I much prefer a config file here. I can just edit the config file on the host and restart, rather than edit the specification that starts the container. But you could still do that if you really want, because the arguments to the 'docker run …' command will override whatever is in the CMD directive.
So, first I build:
docker image build -t pure-ftpd .Now it's time to config!
pure-ftpd.conf and virtual users
As mentioned, I want PASV mode support, TLS support, and some virtual users. There is an initial pure-ftpd.conf that was installed in /pure-ftpd/etc. I'll pull that out of the image and start editing:
docker cp pure-ftpd:\pure-ftpd\etc\pure-ftpd.conf pure-ftpd.confThis is a pretty big file, so I'm just going to show the diff's I made:
*** pure-ftpd.orig.conf --- pure-ftpd.conf *************** *** 45,47 **** ! Daemonize yes --- 45,47 ---- ! Daemonize noI definitely don't want to daemonize here, because that would cause the container to immediately exit. Remember, the container stays live so long as the first process started therein has not exited, and daemonizing would spawn (and detach) a child, while the shell that started it (the main process) would then exit.
*** pure-ftpd.orig.conf --- pure-ftpd.conf *************** *** 124,126 **** ! # PureDB /etc/pureftpd.pdb --- 124,126 ---- ! PureDB /pure-ftpd/etc/pureftpd.pdbSpecifying the PureDB authentication method is what enables our virtual users. Also, specify the path into our sub-tree for the user database rather than the default in the system tree.
*** pure-ftpd.orig.conf --- pure-ftpd.conf *************** *** 178,180 **** ! # PassivePortRange 30000 50000 --- 178,180 ---- ! PassivePortRange 30000 30009 *************** *** 186,188 **** ! # ForcePassiveIP 192.168.0.1 --- 186,189 ---- ! ForcePassiveIP example.com ! #192.168.173.43I want to support PASV mode for the benefit of those outside the NAT firewall. The PassivePortRange is a pool of ports to be used for PASV, and is suggested to be as broad as possible. However, I don't really want to forward 20,001 ports on my firewall, and have docker publish just as many, so I reduce that number to 10. For this ad-hoc server that is expected to be rarely used when in-a-pinch, this should be quite sufficient.
When PASV mode is in effect, the server tells the client where it should connect, and by default it will do this by telling the IP address on which the client connected. However, I am behind NAT, so that's not going to be reachable! So I use the ForcePassiveIP option to have pure-ftpd to say something different. If I have a static public IP, that would be suitable, but I am on a dynamic DNS, so the DNS name is more appropriate. Pure-ftpd will look up that name and report its IP.
This has a consequence: if you are on the local network, PASV will probably not work! That's because your client will be trying to connect to the public IP, and when coming from inside the network, that connection will probably not be NAT'ed back into the network. I believe there are some router shenanigans you can do if you have that much control over your router, but I prefer just to remember: 'only use active mode inside the network'. However, for testing, you can temporarily supply the internal IP address, and use the hosts file on your client machine to direct the DNS name to the internal network address, and PASV will work there. This is just for testing, because PASV will then /not/ work for clients outside the network! Testing only!
*** pure-ftpd.orig.conf --- pure-ftpd.conf *************** *** 368,370 **** ! MaxDiskUsage 99 --- 369,371 ---- ! MaxDiskUsage 75This is to-taste. It's to start refusing uploads when the volume on which the (virtual) user's home directory has been consumed to a certain amount. Since this volume is shared with a bunch of unrelated services, I cranked this down quite a bit so that it is less likely to cause other services to fail.
*** pure-ftpd.orig.conf --- pure-ftpd.conf *************** *** 418,420 **** ! # TLS 1 --- 419,421 ---- ! TLS 1 *************** *** 439,441 **** # CertFile /etc/ssl/private/pure-ftpd.pem ! # CertFileAndKey "/etc/pure-ftpd.pem" "/etc/pure-ftpd.key" --- 440,442 ---- # CertFile /etc/ssl/private/pure-ftpd.pem ! CertFileAndKey "/etc/letsencrypt/live/example.com/fullchain.pem" "/etc/letsencrypt/live/example.com/privkey.pem"With this installation I am going to support FTP-over-TLS, so I selected option '1'. This means 'do TLS or plaintext -- whatever the client requests'. Option '2' is TLS only, and option '0' is plaintext only.
The CertFileAndKey option allows us to specify /separate/ certificate and key files, which is what certbot is going to automatically manage for us. Much like with the other services, I am going to mount the certbot tree in the conventional location, hence the paths chosen here.
Sticking Stuff in Places
As with the other services, I created a directory:
/mnt/datadrive/srv/config/pure-ftpd
That contains config-related files. In this directory I made a sub-directory 'etc' that contains the stuff I will mount onto /pure-ftpd/etc. It will contain three files:
- pure-ftpd.conf - the server config describe above
- pureftpd.passwd - the textual virtual user list that humans read
- pureftpd.pdb - the binary virtual user database that the daemon uses
At this juncture I will just have pure-ftpd.conf. Time to make some virtual users.
Making (l)users
Before I get to testing, I need to have a couple virtual users in existence so I can log in. I don't have the pure-ftpd tools to do that on the host machine, so I do that from inside the container. For this purpose the container will be launched interactively like this:
docker run -it --rm --name ftptest \ --mount 'type=bind,src=/mnt/datadrive/srv/data/ftp/virtual,dst=/srv/ftp/virtual' \ --mount 'type=bind,src=/mnt/datadrive/srv/config/pure-ftpd/etc,dst=/pure-ftpd/etc' \ pure-ftpd shThis is a 'minimal' launch in that I haven't mounted stuff or published ports necessary to actually run the daemon (so I can do this even if another one is running that /does/ expose those ports), but I do just enough to run some tools.
As mentioned, pure-ftpd has two user databases that must be in sync, but I found the special option '-m' that will allow you to keep them in sync when making changes. So I can create our first user:
pure-pw useradd easy123 -m -u ftpuser -d /srv/ftp/virtual/easy123Because I set the PURE_PASSWDFILE and PURE_DBFILE variables, I don't have to specify those filenames on the command line.
On the host machine there was already a directory for this user:
/mnt/datadrive/srv/data/ftp/virtual/easy123and specify the password twice. No, isn't especially scriptable, and the pure-ftpd docs explain the rationale for that. It also goes into a couple shenanigans one can pull if you /really/ needed to do it. For my rarelu-sued-except-when-in-a-pinch server, I will bit the bullet and do it interactively on the few occaisions I need to do so.
Now I exit and can test!
Testing
I am going to test both active and passive mode internally, so first I will edit the /mnt/datadrive/srv/config/pure-ftpd/etc/pure-ftpd.conf to temporarily specify ForcePassiveIP to be the machine's internal IP address '192.168.173.43'. I won't leave it this way for production, but this way PASV will work from within the network.
I also modified my client machine's hosts file to point my 'example.com' domain to the internal IP address, so that I can reach it from the local network, and test out TLS. My certbot has already been run some time back, so I already have the "/etc/letsencrypt/live/example.com/fullchain.pem" and "/etc/letsencrypt/live/example.com/privkey.pem". Since this domain is on dynamic DNS, I can't have subdomains with my provider, so it is fine for me to use the same cert/key that I use for WWW.
Now I can launch fer real!
docker run -d --rm -p 21:21 -p 30000-30009:30000-30009 --name ftptest \ --mount 'type=bind,src=/mnt/datadrive/srv/config/certbot/etc/letsencrypt,dst=/etc/letsencrypt' \ --mount 'type=bind,src=/mnt/datadrive/srv/config/nginx/dhparam.pem,dst=/etc/ssl/private/pure-ftpd-dhparams.pem' \ --mount 'type=bind,src=/mnt/datadrive/srv/data/ftp/virtual,dst=/srv/ftp/virtual' \ --mount 'type=bind,src=/mnt/datadrive/srv/config/pure-ftpd/etc,dst=/pure-ftpd/etc' \ pure-ftpdThis detaches from the tty (i.e. returning control back to the user and effectively running in the background), and self-cleans-up on main process exit, publishes the ports I need. Note that here I can use port-range syntax for the PASV stuff. The cert/key stuff is mounted in the typical (for certbot) location, much as before. Pure-ftpd has a hard-coded path for Diffie-Hellman parameters, so I mount those at the expected path. Strictly, you don't need to supply this at all since there is a baked-in default in the pure-ftpd source code. I find it amusing that pure-ftpd seems to know that DH params are non-secret, yet the hard-coded path seems to indicate that they are private things. Whatever. The baked-in default is 2048 bits, I believe. But since I have some 4096 already cooked up from before, why not use them? My data tree for ftp on the datadrive is mounted into the expected place. And finally the /pure-ftpd/etc is mounted. I should talk about this briefly.
I found through a fair amount of pain that you need to mount the /pure-ftpd/etc as a directory which contains the files therein, rather than mounting those files directly. In particular, for the user database stuff. If you mount the three files directly, then pure-pw will not work! That tool deletes and re-creates files, rather than opening and modifying. This scenario apparently doesn't work with docker mounted files. But mounting the directory as a whole enables such deletion/recreation activities. Caveat configurator!
With this now running, I can finally test. I am using WinSCP on the client machine. There are a couple caveats with that:- when you create a 'new site' with the FTP protocol, the default will be to have chosen 'PASV' mode. Here we will be specifically testing that, and have set up for such, but later in production this will not work for LAN connections, and you must take care to go under 'Advance, Connection', and de-select 'Passive mode'.
- when you use TLS, you must select 'Encryption: TLS/SSL Explicit encryption'.
I created a 'site' definition for the 'easy123' user I set up earlier, and tried connecting and uploading, downloading, and deleting files. I tried that under TLS and unencrypted, and I tried that under active and PSV modes. Yay! For fun, I also tried in a separate session to the host machine copying files into and out of /mnt/datadrive/srv/data/ftp/virtual/easy123, and saw that those showed up and were similarly accessible through the ftp site.
OK, testing is finished! I use:
docker container stop ftptestto stop and auto-remove that container. Now it's time to make it into a real service.
Since we're going to production, first, I undo the hack I did for testing PASV in pure-ftpd.conf to ForcePassiveIP, and return that to my dynamic DNS name 'example.com'.
systemd
This service doesn't need to be part of the web-related suite of services, so I am going to make a separate configuration for it. This way I can start/stop/enable/disable independently of the web stuff.
My docker-compose@.service that I created way back does not need to be changed. That rather delegated the service-specific activities to a docker-compose.yml file in a named subdirectory of /etc/docker/compose. Here it will be called 'ftp':
/etc/docker/compose/ftp/docker-compose.yml:
version: '3' services: #pure-ftpd service ftp: image: pure-ftpd container_name: ftp restart: unless-stopped tty: true ports: - "21:21" - "30000-30009:30000-30009" volumes: - /mnt/datadrive/srv/config/certbot/etc/letsencrypt:/etc/letsencrypt - /mnt/datadrive/srv/config/nginx/dhparam.pem:/etc/ssl/private/pure-ftpd-dhparams.pem - /mnt/datadrive/srv/data/ftp/virtual:/srv/ftp/virtual - /mnt/datadrive/srv/config/pure-ftpd/etc:/pure-ftpd/etcThis is pretty much just a transcoding of the command-line options we used when testing.
Then the yoosh of:
sudo systemctl enable docker-compose@ftpand for this session, manually start:
sudo systemctl start docker-compose@ftpAnd do another final test cycle (except for PASV).
Finis!
Next
A quicky for MQTT via stock eclipse-mosquitto.
-
Making a Docker Image from Scratch for Fossil-SCM
11/18/2020 at 17:59 • 0 commentsSummary
My next stop in this Odyssey involves getting a little more hands-on with Docker. Here, I create a bespoke image for an application, and integrate that into my suite of services. We explore 'multi-stage builds'.
Deets
Another of my services to be restored is my source code management (SCM) system. Indeed, it is due to data failures in the SCC that first alerted me to the fact that my server was failing. It's a separate topic as to how I did data recovery for that, but the short story is that it was a distributed version control system (DVCS), so I was able to recover by digging up some clones on some of my other build systems.
The SCM I am presently using for most of my personal projects is Fossil. I'm not trying to proselytize that system here, but I should mention some of it's salient features to give some context on what is going to be involved in getting that service back up and running.
Fossil is a DVCS, in the vein of Git and Mercurial, and for the most part the workflow is similar. The features I like about Fossil is that it also includes a wiki, bug tracking/ticketing system, technical notes, a forum (this is new to me), in addition to the source code control. All of this is provided in a single binary file, and a project repository is similarly self-contained in a single file. The gory details of the file format are publicly documented. It was created by the SQLite folks, who use it for SQLite source, and also now SQLite's public forum is hosted from it as well. It's kind of cool! If you choose to check it out, know also that it can bi-directionally synchronize with git. (I have done this but I'm not going to discuss that here.)
DVCS was an important thing for the Linux kernel development, but pretty much everything else I have seen doesn't really leverage the 'distributed' part of it. DVCS systems are still mostly used in a master/slave kind of arrangement. What seems to me to be the reason they took off so strongly was that they have really, really, good diff and merge capabilities relative to prior systems. Not because prior systems couldn't, but rather they didn't need to as badly, and DVCS just wouldn't be viable at all if they didn't have really good branch-and-merge capabilities. So I think it's the improvement in branch-and-merge that led to their widespread adoption more than the 'distributed' part of it. (Which when you think about it, is kind of a hassle: I've got to commit AND push? lol.)
Anyway, Fossil is less commonly used, so you usually build it from source. No biggie -- it's really easy to build, and it's just a single binary file you put somewhere in your path, and you're done.
Providing a server for it means starting the program with some command-line switches. In the past, I set up an xinetd to spawn one on-demand. Now, I'll just run it in a docker container in the more pedestrian command-line mode.
The protocol Fossil uses is http-based. This means that I can use nginx to proxy it. Historically, I opened a separate port (I arbitrarily chose 8086), but I now can use a sub-domain, e.g. fossil.example.com, and have nginx proxy that over the the fossil server, and avoid opening another port.
Alas, not so fast for me. I am using a dynamic DNS service, which doesn't support subdomains on the free account, so I'll still have to open that port, alas. I do have a couple 'spare' domains on GoDaddy, so I can test out the proxy configuration, anyway, though.
The other benefit of proxying through nginx (when you can), is that you can do it over TLS. Fossil's built-in web server doesn't do TLS at this time -- you have to reverse proxy for that.
OK! Time to build!
Building Fossil
I did first build on the host system because I find the fossil exe handy for inspecting the repositories in an ad-hoc manner, and also by using the test-integrity command from time-to-time to detect corruption (shouldn't happen, but the defective SD card is what brough me to this Odyssey). I won't cover that here. But I did do the same in the 'alpine:latest' container to develop and test the commands that I will ultimately put in my Dockerfile.
#start an interactive container for development of Dockerfile
docker container run -it --rm alpine:latest shand then I tried it out until I wound up with this recipe:
#try out the following to verify we can build and install fossil mkdir build cd build apk add --update alpine-sdk build-base tcl-dev tk openssl-dev wget https://fossil-scm.org/home/uv/fossil-src-2.12.1.tar.gz tar zxvf fossil-src-2.12.1.tar.gz cd fossil-2.12.1 ./configure --with-th1-docs --with-th1-hooks --json make strip fossil make installThe only trick here was figuring out the different packages to install for Alpine. On Ubuntu, the main thing is 'build-essentials', but here it is 'alpine-sdk' and 'build-base'. You'll need those for building stuff from source in the future as well.
The Dockerfile can look like this at this point:
/mnt/datadrive/srv/docker/fossil/Dockerfile
FROM alpine:latest ARG FOSSIL_VERSION=2.12.1 WORKDIR /build RUN set -x && \ apk add --update --no-cache alpine-sdk build-base tcl-dev tk openssl-dev && \ wget https://fossil-scm.org/home/uv/fossil-src-${FOSSIL_VERSION}.tar.gz && \ tar zxvf fossil-src-${FOSSIL_VERSION}.tar.gz && \ cd /build/fossil-${FOSSIL_VERSION} && \ ./configure --with-th1-docs --with-th1-hooks --json && \ make && \ strip fossil && \ make install ENV FOSSIL_PORT=8086 ENV FOSSIL_REPO_LOC=/srv/fossil/repos EXPOSE ${FOSSIL_PORT} ENTRYPOINT fossil server --port ${FOSSIL_PORT} --repolist ${FOSSIL_REPO_LOC}and then build:
docker image build -t fossil-server .This builds the docker image, and sets up the appropriate stuff to have the fossil server run when the container starts.
You'll notice two directives 'ARG' and 'ENV'. They're mostly the same, but subtly different. 'ARG' will provide an environment variable that is defined only when building. ENV will provide an environment variable that is defined both when building and also when later running.
I used these variables here simply so that I could more easily change some parameters as needed in the future.
It takes a while to compile the stuff; about 35-40 minutes.
Afterwards:
bootilicious@rpi3server001:/mnt/datadrive/srv/docker/fossil$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE fossil-server latest f63d681b8b16 34 seconds ago 334MB nginx-certbot latest 2d7ad5eed815 3 days ago 83.1MB php fpm-alpine 31b8f6ccf74b 12 days ago 71.5MB nginx alpine 3acb9f62dd35 2 weeks ago 20.5MB alpine latest 2e77e061c27f 2 weeks ago 5.32MB334 MB! Sweet Jesus! That's way too much. Most of it is the intermediate build artifacts.
Multi-stage Builds
This is a common problem, and Docker introduced a concept called 'multistage builds' to cope with it. The gist is that your docker file specifies several build operations, and that you copy the desired pieces from one to another. So, in this case, you can do the first build (resulting in the 334 MB image, but then do another build by plucking out the desired pieces for the next stage.
The methodology is fairly straight-forward: each 'FROM' directive terminates a previous build stage and starts a new one. The build stages are internally numbered starting from 0, and can be referred to that way, but there is a convenience feature where you can give them a name and refer to them that way. So in our case, we'll label what we've done so far as 'buildstage', and then add a new stage called 'production' that simply copies in the desired build artifact, and that's what we'll use.
/mnt/datadrive/srv/docker/fossil/Dockerfile
#build stage for creating fossil executable FROM alpine:latest AS buildstage ARG FOSSIL_VERSION=2.12.1 WORKDIR /build RUN apk add --update --no-cache alpine-sdk build-base tcl-dev tk openssl-dev && \ wget https://fossil-scm.org/home/uv/fossil-src-${FOSSIL_VERSION}.tar.gz && \ tar zxvf fossil-src-${FOSSIL_VERSION}.tar.gz && \ cd /build/fossil-${FOSSIL_VERSION} && \ ./configure --with-th1-docs --with-th1-hooks --json && \ make && \ strip fossil && \ make install #production stage just has the build fossil executable, and serves the repos #note, this presumes the repos have been bind-mounted in ${FOSSIL_REPO_LOC} FROM alpine:latest AS production ENV FOSSIL_PORT=8086 ENV FOSSIL_REPO_LOC=/srv/fossil/repos COPY --from=buildstage /usr/local/bin/fossil /usr/local/bin/fossil EXPOSE ${FOSSIL_PORT} ENTRYPOINT fossil server --port ${FOSSIL_PORT} --repolist ${FOSSIL_REPO_LOC}build as per yoosh; then docker image ls:
bootilicious@rpi3server001:/mnt/datadrive/srv/docker/fossil$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
fossil-server latest ef792c58af18 About a minute ago 22.9MB
<none> <none> c3e0b8734019 About a minute ago 334MB
nginx-certbot latest 2d7ad5eed815 3 days ago 83.1MB
php fpm-alpine 31b8f6ccf74b 12 days ago 71.5MB
nginx alpine 3acb9f62dd35 2 weeks ago 20.5MB
alpine latest 2e77e061c27f 2 weeks ago 5.32MBbootilicious@rpi3server001:/mnt/datadrive/srv/docker/fossil$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE fossil-server latest ef792c58af18 About a minute ago 22.9MB <none> <none> c3e0b8734019 About a minute ago 334MB nginx-certbot latest 2d7ad5eed815 3 days ago 83.1MB php fpm-alpine 31b8f6ccf74b 12 days ago 71.5MB nginx alpine 3acb9f62dd35 2 weeks ago 20.5MB alpine latest 2e77e061c27f 2 weeks ago 5.32MBSo, well, the multi-stage build saved 310 MB. Hmm, I guess that works! I don't know how to automatically get rid of the intermediate image labelled as <none>:<none>, but a 'docker image rm c3e0' casts it aside.
Now that we have our smaller image, we can test it:
#test docker run --rm -d --name fossil-server \ --mount 'type=bind,src=/mnt/datadrive/srv/data/fossil/repos,dst=/srv/fossil/repos' \ -p 8086:8086 \ fossil-serverWe should be able to browse at host IP address, port 8086, and see the repository list. (We can add repo name to url for specific repository -- this is all Fossil-specific stuff.)
Now we are ready to integrate it into the 'myservices' collection for systemd.
Systemd
Adding the additional service to the 'myservices' group is relatively straightforward:
/etc/docker/compose/myservices/docker-compose.yml
version: '3' services: #Fossil service fossil: image: fossil-server container_name: fossil-server restart: unless-stopped tty: true #I can proxy this through nginx, however since the DNS provider (noip.com) #does not support sub-domains, it is still necessary in my case to continue #to provide the port through my firewall for Internet access. If your DNS #does not have this limitation, then you can comment this out. ports: - "8086:8086" volumes: - /mnt/datadrive/srv/data/fossil/repos:/srv/fossil/repos networks: - services-network #PHP-FPM service (must be FPM for nginx) php: image: php:fpm-alpine container_name: php restart: unless-stopped tty: true #don't need to specify ports here, because nginx will access from services-network #ports: # - "9000:9000" volumes: - /mnt/datadrive/srv/config/php/www.conf:/usr/local/etc/php-fpm.d/www.conf - /mnt/datadrive/srv/data/www:/srv/www networks: - services-network #nginx www: depends_on: - php image: nginx-certbot container_name: www restart: unless-stopped tty: true ports: - "80:80" - "443:443" volumes: - /mnt/datadrive/srv/config/nginx/default.conf:/etc/nginx/conf.d/default.conf - /mnt/datadrive/srv/data/www:/srv/www - /mnt/datadrive/srv/config/certbot/etc/letsencrypt:/etc/letsencrypt - /mnt/datadrive/srv/data/nginx/dhparam.pem:/etc/ssl/certs/dhparam.pem networks: - services-network #Docker Networks networks: services-network: driver: bridgeThe additional service is added. In my case, since my DNS does not support sub-domains, I still need to expose the port directly in order for it to be accessible from the outside world. However, I also did augment the nginx configuration to proxy. This works if your DNS allows subdomains, and then you don't need to open additional ports -- you simply prefix your domain with 'fossil'; e.g. 'fossil.example.com'.
Nginx
XXXX
/mnt/datadrive/srv/config/nginx/default.conf
#this overrides the 'default.conf' in the nginx-certbot container #this is for the example.com domain web serving; we have php enabled here #this does http-to-https redirect server { listen 80; listen [::]:80; server_name example.com; return 301 https://$server_name$request_uri; } #this does the https version server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name example.com; ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem; ssl_protocols TLSv1.2; ssl_prefer_server_ciphers on; ssl_dhparam /etc/ssl/certs/dhparam.pem; ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384; ssl_ecdh_curve secp384r1; ssl_session_timeout 10m; ssl_session_cache shared:SSL:10m; ssl_session_tickets off; ssl_stapling on; ssl_stapling_verify on; resolver 8.8.8.8 8.8.4.4 valid=300s; resolver_timeout 5s; add_header X-Frame-Options DENY; add_header X-Content-Type-Options nosniff; add_header X-XSS-Protection "1; mode=block"; #charset koi8-r; #access_log /var/log/nginx/host.access.log main; root /srv/www/vhosts/example.com; index index.html index.htm index.php; location / { try_files $uri $uri/ /index.php?$query_string; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # pass the PHP scripts to FastCGI server listening on (docker network):9000 # location ~ \.php$ { try_files $uri = 404; fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass php:9000; fastcgi_index index.php; include fastcgi_params; fastcgi_param REQUEST_URI $request_uri; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_path_info; } } #this is our proxied fossil server; keep in mind the host name in 'proxy_pass' is #the docker hostname on the internal network, which happens also to be the name of #the container server { listen 80; listen [::]:80; server_name fossil.example.com; location / { proxy_pass http://fossil-server:8086/; proxy_redirect off; proxy_set_header Host $host; } }Well, that was a bit of an Odyssey! I still have more services to dockerize, though. I need to do FTP next. I haven't completely decided if I'm going to do MySQL, or instead migrate my legacy MySQL database to SQLite form, and redesign my legacy apps to use that, instead (obviating the need for a server). Also, my legacy SVN repositories might be migrated to fossil. There is also VPN, though I think that will be best served by running on the host system, anyway. We'll see!
Next
Tackling FTP.
-
Let's Do Encrypt; And Why Not?
11/16/2020 at 19:19 • 0 commentsSummary
Here I modify the nginx configuration to also support TLS, and redirect unencrypted requests to our encrypted version. I also modify the base nginx image to include the Let's Encrypt certbot tool to keep the certificates renewed automatically.
Deets
In this modern world, who does plaintext HTTP anymore except in special circumstances? Also, since I can now get free certificates from Let's Encrypt, why would I not want to upgrade to TLS?
Let's Encrypt
Let's Encrypt is a non-profit set up to encourage the use of encryption on the Internet by providing free TLS certificates. It uses an automated issuance process, and so has some limitations (you can't get OV or EV certs), but it is useful for the vast majority of use cases.
The automated issuance is done with a tool called 'certbot'. It is a python application that handles generating of keys, supplying a 'challenge' to prove domain ownership, generating certificate signing requests, and retrieval of issued certificates. It also can handle renewal, since the Let's Encrypt certificates are valid for 90 days only.
There are several modes of proving domain ownership, and the two most common are 'HTTP' and 'DNS'. In the HTTP challenge (elsewhere called 'webroot') proof of ownership of the domain is established by the presence of well-known resources on a server than can be accessed via the DNS name being challenged. In the DNS challenge, some special TXT records are used to prove domain ownership.
The DNS challenge gives more options, because that is the only way that you can get a 'wildcard' certificate issued -- they won't issue such when using the webroot challenge. However, the challenge with that challenge is that the certbot needs to understand how to manipulate the DNS records. It does this via 'plugins' that you can install that understand various APIs, however the DNS providers I have (GoDaddy, Google Domains, no-ip.com) do not have such APIs, and hence I will have to use the 'webroot' mechanism. This isn't too bad, because even though I can't get a wildcard certificate, I can get a certificate with multiple server names, such as 'example.com', 'www.example.com', 'ftp.example.com', etc.
Nginx
Setting up TLS on nginx is not particularly difficult; you specify another 'server' block, listen on 443 with the TLS protocol, and specify various TLS options. There is one gotcha though: it wants the certificates to exist upon startup. And I haven't gotten any yet! So, chickens and eggs. As such, I'm going to have to get the certbot working first to 'prime the pump', and then reconfigure nginx for HTTPS afterwards.
Certbot
My original thought was to get certbot running in yet another containers. I still think this is a plausible idea, but there were two things that nagged me:
- when renewing the certificate, the nginx needs to be told to 'reload' so that it will pick up the new cert. It is not currently clear to me how to do that easily container-to-container (I have no doubt there are some clever ways, and maybe even orthodox ones, but I don't know of them yet.)
- it vexes me to have a container running just to support a cron job that runs once a day. Maybe I'm being miserly with system resources, but it seems a waste, and this Pi3 just has 1 GB ram.
So, I decided to not run certbot in a separate container, but rather derive a new image from the curated 'nginx' that also includes certbot inside it, and has a cron job to test for renewal each day, and cause nginx to reload if needed. If nothing else, it's practice building a derivative docker image. The first time I'll build one of our own!
Dockerfile
Creating new docker images involves specifying what's going to be inside and what code to run when it starts up. As mentioned before, things are usually run as conventional processes rather than daemons in the docker scenario, because the daemonic aspect is being done via the container, rather than the application in the container. The file that specifies all this stuff uses the well-known name 'Dockerfile' (case-sensitive!) (you can override this default if you want, but why bother?).
In the Dockerfile, you specify what is the base image, perhaps add some things like copying files into the image from the host, or running tools to install needed packages. Then you specify what is to be automatically run. There are myriad options; the normative reference is https://docs.docker.com/engine/reference/builder/. I will cover only what is relevant here. Incidentally, for the images you find on Dockerhub, you can typically also see the Dockerfile that was used to create it. I found this very helpful and cut-and-pasted things from other images which struck my fancy.
I created a working directory hierarchy on my datadrive to develop these Dockerfiles. In this case one at /mnt/datadrive/srv/docker/www/Dockerfile
FROM nginx:alpine RUN set -x \ #get the certbot installed && apk add --no-cache certbot \ && apk add --no-cache certbot-nginx \ #forward log to docker log collector && mkdir -p /var/log/letsencrypt \ && ln -sf /dev/stdout /var/log/letsencrypt/letsencrypt.log \ #get the crontab entry added && { crontab -l | sed '/^$/d' ; \ printf '0 1 * * * certbot renew --quiet && nginx -s reload\n\n' ; } \ | crontab - #these were copied from the nginx:alpine Dockerfile; I think I need to do this but not really certain ENTRYPOINT ["/docker-entrypoint.sh"] EXPOSE 80 STOPSIGNAL SIGTERM CMD ["nginx", "-g", "daemon off;"]The FROM directive specified nginx:alpine as the base image, and at the bottom were the startup things that I simply copied from the original Dockerfile used to create 'nginx:alpine', since I still want it to run nginx.
The stuff in the middle is what installs certbot and setup up the cron job to do renewals. This is done via a RUN directive that installs the certbot, sets up for logging in a way compatible with docker, and then manipulates the crontab.
One thing about RUN (and also COPY) is that each invocation creates a new 'layer' in the virtual filesystem of the image. Consequently it is a common design pattern to concatenate commands with the '&&' shell operator into one giant RUN directive. This way there is only one new layer created. But feel free to use multiple -- sometimes I find that handy when first developing the file, then when it is working like I want, I come back and combine them into the concatenated form.
Another common pattern is the use of '--no-cache' when doing the 'apk add' (relevant for Alpine Linux). This avoids taking up filesystem space with cached packages that will never be used.
The use of 'set -x' causes the various RUN commands to be echoed back out when executed, and this is handy to see when building the image, but otherwise is not required.
The crontab part was a little tricky for me to get right. I simply needed to append a line of text fixed to the crontab, but this was complicated for several reasons:
- crontab is picky about line endings
- crontab is better edited with the crontab tool, which will operate on the correct crontab for your platform
- when using crontab to update the underlying file, it replaces the entire file. There isn't an 'append' option.
So, I used 'crontab -l' to spew out the current crontab, and then sed to remove stray end-of-lines. Then I use a shell command group (between '{' and '}') to cause that first bit to be run to completion, then a simple 'printf' to spew the new crontab entry with two newlines. All of that result gets piped into 'crontab -', which will replace the crontab with this new content.
The creation of the log path for certbot and the symlink for the logfile will cause the certbot log lines to be collected by docker.
Once you've got the Dockerfile done, you build it with docker:
docker image build -t nginx-certbot .Ideally this will complete successfully. Then you can see it with 'docker image ls' in your local registry:
REPOSITORY TAG IMAGE ID CREATED SIZE nginx-certbot latest 2d7ad5eed815 3 days ago 83.1MB php fpm-alpine 31b8f6ccf74b 11 days ago 71.5MB nginx alpine 3acb9f62dd35 2 weeks ago 20.5MB alpine latest 2e77e061c27f 2 weeks ago 5.32MB
So, I will eventually update our /etc/docker/compose/myservices/docker-compose.yml file to refer to this image instead of the stock nginx:alpine image. But first I need to prime the pump with the certificates, so I don't yet stop the existing running web server for this step.
Priming the Pump
I need to run certbot at least once to get the initial certificates. I will do this by running our new image with 'sh', and this will prevent nginx from running within it. I will also mount some more paths.
Certbot tends to like to put stuff in /etc/letsencrypt. So I'll create another directory on the datadrive:
mkdir -p /mnt/datadrive/srv/config/certbot/etc/letsencryptand I'll mount that into this image (and eventually into the www image as well).
#run it interactively so I can generate the initial certificates docker run -it --rm --name certbottest \ --mount 'type=bind,src=/mnt/datadrive/srv/config/certbot/etc/letsencrypt,dst=/etc/letsencrypt' \ --mount 'type=bind,src=/mnt/datadrive/srv/data/www,dst=/srv/www' \ nginx-certbot shand once running inside that container, I can generate our original certificate:
#within the container, generate certificates certbot certonly --webroot --agree-tos -n --email person@whatever.com \ -d example.com \ -w /srv/www/vhosts/example.com --dry-runThe email person@whatever.com should be changed -- it is used to receive notifications from Let's Encrypt about impending expiration. Also the domain -d should be changed to whatever is relevant in your case, and then also -w should be similarly changed to whatever is actually your web's root dir.
This will do some crypto stuff and generate a well-known resource in your web root, and then contact Let's Encrypt's backend. If that backend can reach the well-known challenge resource via the domain name you have provided, then a certificate will be issued.
I ran the command specifying '--dry-run', so I aren't really going to get a certificate this time. This is for debugging that you've got everything set up correctly. If it is correct, then run it once more, but without --dry-run, and you will get your certificate for real! It will be placed in a directory '/etc/letsencrypt/live/example.com' (Obviously the last component changed to your actual domain.) The important files in here are:
- /etc/letsencrypt/live/example.com/fullchain.pem
- /etc/letsencrypt/live/example.com/privkey.pem
The first is the public data (certificate chain), and the second is private (the private key). I now can start working on our nginx configuration. But before that, here are a comple parting notes:
- this worked because I still had a separate web server running servicing that domain. If I did /not/ have a separate web server, I could have use the '--standalone' option with certbot to have certbot run a minimal web server itself. In that case, the container needed to be started with publishing the port 80 so that the standalone server in this container could be reached by the Let's Encrypt backend for validation.
- you can use the '-d' option multiple times to specify multiple server names. E.g. '-d example.com -d www.example.com -d ftp.example.com'. Let's Encrypt's backend must be able to reach every one of those in order to issue the certificate, but this way you can support multiple subdomains. Supporting multiple subdomains is quite handy if you want to have several services proxied through nginx. That way you don't have to open a bunch of ports -- they get routed based on the http headers. It's also handy from special services like FTP even though those will eventually be on a different port anyway.
- as a counterpoint, free DNS providers like 'no-ip.com' do /not/ support subdomains on their free accounts, anyway, so that won't work for you. But if you have a full DNS provider like GoDaddy or Google Domains, then you can.
Making Diffie-Hellman Parameters
A brief excursion: I will be using ephemeral Diffie-Hellman key agreement, so I'm going to need some parameters. On your desktop machine, use openssl:
openssl dhparam -out dhparam.pem 4096This will take about an hour -- maybe more, so I do recommend doing it on a desktop machine instead of the RPi.
Diffie-Hellman parameters are non-secret data, so if you have a set of them already from other things, feel free to re-use them.
When done, copy those into:
/mnt/datadrive/srv/config/nginx/dhparam.pem
Modding Systemd and Nginx Configs
OK, for the final steps, I modify the configs of our systemd service (actually, the docker-compose.yml for that service) to use the new image, and the nginx config to do TLS.
Stop the services:
sudo systemctl stop docker-compose@myserviceEdit the /etc/docker/compose/myservices/docker-compose.yml:
version: '3' services: #PHP-FPM service (must be FPM for nginx) php: image: php:fpm-alpine container_name: php restart: unless-stopped tty: true #don't need to specify ports here, because nginx will access from services-network #ports: # - "9000:9000" volumes: - /mnt/datadrive/srv/config/php/www.conf:/usr/local/etc/php-fpm.d/www.conf - /mnt/datadrive/srv/data/www:/srv/www networks: - services-network #nginx www: depends_on: - php image: nginx-certbot container_name: www restart: unless-stopped tty: true ports: - "80:80" - "443:443" volumes: - /mnt/datadrive/srv/config/nginx/default.conf:/etc/nginx/conf.d/default.conf - /mnt/datadrive/srv/data/www:/srv/www - /mnt/datadrive/srv/config/certbot/etc/letsencrypt:/etc/letsencrypt - /mnt/datadrive/srv/config/nginx/dhparam.pem:/etc/ssl/certs/dhparam.pem networks: - services-network #Docker Networks networks: services-network: driver: bridgeThe salient changes are in the 'www' service, the changing of the 'image', the addition of the 443 to 'ports', and the mounting of the '/etc/letsencrypt' directory and 'dhparam.pem' file.
Don't restart yet, I need to modify the nginx config now:
/mnt/datadrive/srv/config/nginx/default.conf
#this overrides the 'default.conf' in the nginx-certbot container #this is for the example.com domain web serving; I have php enabled here #this does http-to-https redirect server { listen 80; listen [::]:80; server_name example.com; return 301 https://$server_name$request_uri; } #this does the https version server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name example.com; ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem; ssl_protocols TLSv1.2; ssl_prefer_server_ciphers on; ssl_dhparam /etc/ssl/certs/dhparam.pem; ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384; ssl_ecdh_curve secp384r1; ssl_session_timeout 10m; ssl_session_cache shared:SSL:10m; ssl_session_tickets off; ssl_stapling on; ssl_stapling_verify on; resolver 8.8.8.8 8.8.4.4 valid=300s; resolver_timeout 5s; add_header X-Frame-Options DENY; add_header X-Content-Type-Options nosniff; add_header X-XSS-Protection "1; mode=block"; #charset koi8-r; #access_log /var/log/nginx/host.access.log main; root /srv/www/vhosts/example.com; index index.html index.htm index.php; location / { try_files $uri $uri/ /index.php?$query_string; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # pass the PHP scripts to FastCGI server listening on (docker network):9000 # location ~ \.php$ { try_files $uri = 404; fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass php:9000; fastcgi_index index.php; include fastcgi_params; fastcgi_param REQUEST_URI $request_uri; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_path_info; } }OK! Most of the server is now in a separate section listening on port 443 for TLS connections. I added a bunch of TLS- related parameters, most importantly specifying the location of the cert chain and private key. I also added a server on unencrypted transport on port 80, which simply responds with a redirect to the equivalent on 443.
Now I can restart the services, and with luck I should now be serving up HTTPS version of our web site, PHP-enabled, and with certbot running periodically to keep our certificates renewed. Done with this service!
Another service I need to dockerize is my source code management system. I use several -- a legacy SVN server, and a more modern Fossil-SCM system. Fossil appeals to me for several reasons that I will lay out, but proselytizing that is not my intent here. Rather, this will require me to build a docker image 'from scratch' (well, sort of), so I'll be able to see how to do that.
Next
Making a docker image from scratch for fossil-scm.
-
Using docker-compose and systemd
11/15/2020 at 18:37 • 0 commentsSummary
Here, I define a group of related services (in this case, nginx and php-fpm) using the 'docker-compose' tool. This allows us to start (and restart) collections of related containers at once. I also define a systemd 'unit' that will start services defined by docker-compose definitions.
Deets
First, a brief excursion: my data drive is getting a little messy now with docker build configurations, container configuration files, and then the legacy data. So I made some directories:
- /mnt/datadrive/srv/config
- /mnt/datadrive/srv/data
I moved my legacy data directories (formerly directly under 'srv') into 'data', and the existing container configuration file stuff under 'config'. OK, back to the story.
I got the two containerized services working together, but I started those things up manually, and had to create some other resources (i.e. the network) beforehand as well. There is a tool for automating this called 'docker-compose'. Try 'which docker-compose' to see if you already have it, and if not get it installed on the host:
# Install required packages sudo apt update sudo apt install -y python3-pip libffi-dev sudo apt install -y libssl-dev libxml2-dev libxslt1-dev libjpeg8-dev zlib1g-dev # Install Docker Compose from pip (using Python3) # This might take a while sudo pip3 install docker-composeSo, docker-compose uses YAML to define the collection of stuff. The containers to run are called 'services', and the body defines the various parameters that would passed on the docker command line as I have been doing up to this point. But it's formatted in YAML! So get used to it.
Authoring the Compose File
Now I'm going to get a little ahead of myself and tell you that the end goal is to have this docker-compose definition be hooked up as a systemd service, and so I am going to put the file in the place that makes sense for that from the start. But don't think these files have to be in this location; you could have them in your home directory while you develop them, and maybe this is easier. You could move them into final position later.
You can find deets on the tool at the normative location https://docs.docker.com/compose/gettingstarted/ ; I am only going to discuss the parts that are meaningful in this project.
First, create the definition in the right place:
sudo mkdir -p /etc/docker/compose/myservicesUltimately, I am going to create a 'generic' systemd unit definition that will work with any docker-compose yaml, not just the one I am creating here. If I wind up making more compose scripts for other logical service groups, then I would create a new directory under /etc/docker/compose with a separate name, and store its docker-compose.yml in that separate directory. So, basically, the directory names under /etc/docker/compose will become part of the systemd service name.
But again I'm getting ahead of myself (sorry). Onward...
Create the docker-compose definition:
/etc/docker/compose/myservices/docker-compose.yml
version: '3' services: #PHP-FPM service (must be FPM for nginx) php: image: php:fpm-alpine container_name: php restart: unless-stopped tty: true #don't need to specify ports here, because nginx will access from services-network #ports: # - "9000:9000" volumes: - /mnt/datadrive/srv/config/php/www.conf:/usr/local/etc/php-fpm.d/www.conf - /mnt/datadrive/srv/data/www:/srv/www networks: - services-network #nginx www: depends_on: - php image: nginx-certbot container_name: www restart: unless-stopped tty: true ports: - "80:80" volumes: - /mnt/datadrive/srv/config/nginx/default.conf:/etc/nginx/conf.d/default.conf - /mnt/datadrive/srv/data/www:/srv/www networks: - services-network #Docker Networks networks: services-network: driver: bridgeIf you take a moment to read it, it should be intelligible if you were able to follow along up to this point regarding all those docker command line invocations and understand the switches I used. The particularly interesting things here (at least I think) are:
- the first line specified the docker-compose format version, and it simply is a requirement that this line be present
- the 'services' have names, and these become the names of the containers (rather than the docker-generated random two-part names). This is particularly useful because these will also become the container's machine name.
- the 'depends_on' key tells docker-compose that 'www' must be started after 'php', so I can control start order
- at the bottom I defined explicitly a network, named 'services-network' (can be whatever you like), using the bridge driver, and I explicitly connected www and php onto that network. Now www can communicate with php. Because of that, I don't need to have php publish its ports on the host machine -- no one needs to mess with those other than nginx.
There are other things that can be defined here, such as persistent docker volumes, but I am using the 'bind' method to make available storage resources on the host, so I don't have a 'volumes' section in this example.
You can get the thing running:
docker-compose -f /etc/docker/compose/myservices/docker-compose.yml up
(it's usually easier to be in the directory with the docker-compose.yml, then you can omit the -f option and simply issue 'docker-compose up')
and to bring them down:
docker-compose -f /etc/docker/compose/myservices/docker-compose.yml down
If all that is working, then I'm ready to wire it into systemd. (If it's not working, you might consider 'docker-compose logs'.)
systemd
OK, if you did perchance create the 'docker.www' systemd service from before, it's time to replace it, so first:
sudo service docker.www stop sudo systemctl disable docker.www sudo rm /etc/systemd/system/docker.www.serviceNow I will make a fancier one:
/etc/systemd/system/docker-compose@.service:
[Unit] Description=%i service with docker compose Requires=docker.service After=docker.service [Service] Type=oneshot RemainAfterExit=true WorkingDirectory=/etc/docker/compose/%i # Remove old containers, images and volumes ExecStartPre=/usr/local/bin/docker-compose down -v ExecStartPre=/usr/local/bin/docker-compose rm -fv ExecStartPre=-/bin/bash -c 'docker volume ls -qf "name=%i_" | xargs docker volume rm' ExecStartPre=-/bin/bash -c 'docker network ls -qf "name=%i_" | xargs docker network rm' ExecStartPre=-/bin/bash -c 'docker ps -aqf "name=%i_*" | xargs docker rm' ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans ExecStop=/usr/local/bin/docker-compose down [Install] WantedBy=multi-user.targetThis fancier one defines a general class of services that are all named 'docker-compose' followed by the particular service name, and separate by '@'. In our case, I've created 'docker-compose@myservices'. The 'myservices' part gets passed in as '%i', and the rest of the definition does the magicry of things in the working directory 'etc/docker/compose/%i', which has the particular docker-compose stuff for that service.
After creating that, I need to do the usual enable and first-time start:
sudo systemctl enable docker-compose@myservices sudo systemctl start docker-compose@myservicesNow the www and php service should be up and running. And of course you can stop it or restart it the usual systemctl ways.
All this is nifty, but in this modern era who does unencrypted HTTP anymore? And especially since you can get TLS certificates for free from Let's Encrypt, I really should try to move towards that.
Next
Modifying the base nginx image to also include tools needed to use Let's Encrypt certificates, and renew them automatically.
-
Adding a Dockerized Service Dependency: PHP-FPM
11/13/2020 at 18:06 • 0 commentsSummary
Here we get a little bit more fancy by adding another microservice to the group: this one for handling PHP processing. We explore some things about networking in docker.
Deets
I have at least one PHP application on my personal web site, so I need PHP processing capability. In the prior days of Apache2, that involved installing and configuring mod_php, but I am using nginx now, and apparently the way that is done is with PHP-FPM. FPM (FastCGI Process Manager) is an alternative PHP FastCGI implementation.
One option is to derive a new docker image from the existing nginx one, and install PHP-FPM in it, alongside nginx. However in this case I am going to use a curated PHP-FPM image from Dockerhub, and let the two containers cooperate. This saves me the trouble of building/installing the PHP -- I should just have to configure it. There is an 'official' image maintained by the PHP people that is for this machine architecture ('ARM64') and for Alpine Linux: 'php:fpm-alpine'
But first, a little bit about networking in Docker.
A Little Bit About Networking in Docker
Docker creates a virtual network for the various containers it runs. There is a default one named 'default', however there is a quirk with it on Linux. The machines (containers) on it do not have names, so it is a hassle to refer to other services. If, however, you create a named network, then magically those machines (containers), will have DNS names, and they happen to be the name of the container.
There are several networking technologies you can use in Docker -- this is provided by what Docker calls a 'driver' -- and the most common technology for stuff like we are doing is to use a network bridge. You may need to ensure you have bridge-utils installed first:
sudo apt install bridge-utilsThen we can create a named network that we will have Docker place its containers on:
docker network create -d bridge localnetThis network definition is persistent, so you can destroy it later when you're done with it:
docker network rm localnetOK! Now our containers will be able to communicate using hostnames.
PHP, Der' It Is!
The PHP-FPM has its own set of configuration files. The curated Docker image 'php:fpm-alpine' has sane defaults for our need, but there is some sand in that Vaseline: filesystem permissions on mounted directories/files. These docker containers are running their own Linux installation, and so user ids and group ids are completely separate from those on the host filesystem. For example, all my 'datadrive' files are usually owned by me, with UID:GID of 1001:1001. However, this user does not exist in the PHP container. The process there is running as 'www-data:www-data' (I don't know the numbers).
There's several ways of dealing with this, but I chose to simply alter the config file that specifies the uid:gid to be 1001:1001. The relevant file is located at '/usr/local/etc/php-fpm.d/www.conf', so I need to alter that. Much like with nginx, I create a directory on datadrive that will hold my configuration overrides for the PHP stuff, and then mount that file into the container (thereby overriding what's already there). First, I make my directory for that:
mkdir -p /mnt/datadrive/srv/phpOK, and here's a little trick: if you mount a file or directory that does not exist on the host, then the first time you start the container, docker will copy the file/directory back onto the host. This only happens if it's not there already. It's really a bit lazy, but interesting to know. Other mechanisms are good old fashioned cat, copy-paste, and there are also docker commands to explicitly extract files from images. So, for the hacky way:
docker run --rm -it \ --mount 'type=bind,src=/mnt/datadrive/srv/php/www.conf,dst=/usr/local/etc/php-fpm.d/www.conf' \ php:fpm-alpine shand then you can immediately exit, thereby terminating and removing the container. You should have seen that '/mnt/datadrive/srv/php/www.conf' has been magically created on your host system. Edit it; around like 20-ish, make this happen:
... ; Unix user/group of processes ; Note: The user is mandatory. If the group is not set, the default user's group ; will be used. ;user = www-data user = 1001 ;group = www-data group = 1001 ...Now PHP in the container will be able to access those files as if it were you on the host system. Obviously, set the UID:GID to what yours actually are.
So now we need to tell NGinx about how to handle PHP requests. We need to modify /mnt/datadrive/srv/nginx/default.conf
server { listen 80; listen [::]:80; server_name example.com www.example.com; #charset koi8-r; #access_log /var/log/nginx/host.access.log main; root /srv/www/vhosts/example.com; index index.html index.htm; location / { } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # pass the PHP scripts to FastCGI server listening on (docker network):9000 # location ~ \.php$ { try_files $uri = 404; fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass php:9000; fastcgi_index index.php; include fastcgi_params; fastcgi_param REQUEST_URI $request_uri; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_path_info; } }So here we have added a section that basically says: 'for objects whose name ends in ".php", process them with the FastCGI interface to a system named 'php' on port 9000'. And a few other incantations. Especially note the 'fastcgi_pass php:9000', because the 'php' there is the machine name of our PHP_FPM container!
Testing
OK, now we are ready to test the two containers working together on the 'localnet' pseudo-network (don't forget to stop any other nginx containers that maybe you have running from other experiments):
docker run --rm -d -p 9000:9000 --name php \ --network localnet \ --mount 'type=bind,src=/mnt/datadrive/srv/php/www.conf,dst=/usr/local/etc/php-fpm.d/www.conf' \ --mount 'type=bind,src=/mnt/datadrive/srv/www,dst=/srv/www' \ php:fpm-alpinedocker run -it --rm -d -p 80:80 --name www \ --network localnet \ --mount 'type=bind,src=/mnt/datadrive/srv/www,dst=/srv/www' \ --mount 'type=bind,src=/mnt/datadrive/srv/nginx/default.conf,dst=/etc/nginx/conf.d/default.conf' \ nginx:alpineIn the root of my website is the venerable info.php:
<html> <head> <title>Info</title> </head> <body> <p> <?php echo phpinfo(); ?> </p> </body> </html>And now if I visit http://www.example.com/info.php, I should see all the infos! The nginx noticed the file was a php kind, and asked the php-fpm system to process it for it! Over the pseudo-network created by docker!
If for some reason things do not seem to be working, you can use
docker logs wwwdocker logs phpand the -f option can be used to follow. Docker provides aggregated logging from the container by catching stdout/stderr, so these containers are often set up with files in /var/log symlinked to /dev/stdout and /dev/stderr. This way you can see the logs easily on the host system, and also filter by container.
When you're done with testing, you can delete the docker network we created:
docker network rm localnetOK, so now that is working, we need to get it working with systemd. I could make another system service like I showed yesterday, but instead I'm going to use a tool called 'docker-compose' to specify a group of related docker images that need to be run together. It also takes care of creating the network we will be needing.
Next
using docker-compose, and also with systemd
-
Using An Existing Image (nginx)
11/11/2020 at 17:59 • 2 commentsSummary
We do something a little more interesting by using a curated image with a useful application running inside. In this case, we run nginx as our web server.
Deets
The Dockerhub is a great place to look for images that have already been created for common things. In this episode I will use an existing docker image for nginx to host a website. This will consist of setting up configuration, mounting volumes, publishing ports, and setting up systemctld to run the image on startup.
Getting the Image and Getting Ready
The image we will use is an nginx deployed on Alpine.
docker image pull nginx:alpineDocker has the sense to figure out CPU architecture, but not all docker images out there have been built for all architectures, so do take note of that when shopping at Dockerhub. This will be running on a Raspberry Pi 3, so it needs to be ARM64.
Docker creates private networks that the various containers run on. Typically these are bridges, so you poossibly need to install the bridge-utils package on the host so that docker can manage them:
sudo apt install bridge-utilsGetting Busy
We can do a quick test:
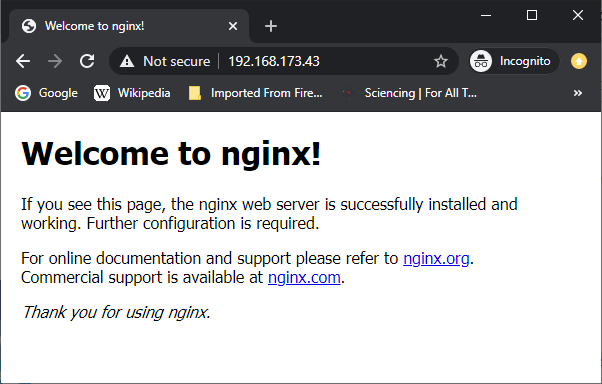
docker run -it --rm -d -p 80:80 --name devweb nginx:alpineThe new things here are '-d', which is shorthand for '--detach', which lets the container run in the background, and '-p', which is shorthand for '--publish', which makes the ports in the container be exposed on the host system. You can translate the port numbers, hence the '80:80' nomenclature -- the first number is the host's port and the second is the container's. Here they are the same. Also, we explicitly named the container 'devweb' just because.
You can drive a web browser to the host system and see the default site:
![]()
OK, that's a start, but we need to serve our own web pages. Let's move on...
docker stop devwebAs mentioned before, my server has a 'datadrive' (which used to be a physical drive, but now is just a partition), and that drive contains all the data files for the various services. In this case, the web stuff is in /mnt/datadrive/srv/www. Subdirectories of that are for the various virtual servers. That was how I set it up way back when for an Apache2 system, but this go-round we are going to do it with Nginx. Cuz 2020.
Docker has a facility for projecting host filesystem objects into containers. This can be specific files, or directory trees. We will use this to project the tree of virtual hosts into the container, and then also to project the nginx config file into the container as well. So, the config file and web content reside on the host as per usual, and then the stock nginx container from Dockerhub can be used without modification.
There are two ways of projecting the host filesystem objects into the container. One is by using a docker 'volume', which is a virtual filesystem object like the docker image itself, or a 'bind', which is like a symbolic link to things in the host filesystem. Both methods facilitate persistence across multiple runnings of the image, and they have their relative merits. Since I have this legacy data mass and I'm less interested right now in shuffling it around, I am currently using the 'bind' method. What I have added is some service-specific directories on the 'datadrive' (e.g. 'nginx') that contain config files for that service, which I will mount into the container filesystem and thereby override what is there in the stock container. In the case of nginx, I replace the 'default.conf' with one of my concoction on the host system. I should point out that the more sophisticated way of configuring nginx is with 'sites-available' and symlinks in 'sites-enabled', but for this simple case I'm not going to do all that. I will just override the default config with my own config.
default.conf:
server { listen 80; listen [::]:80; server_name example.com www.example.com; #charset koi8-r; #access_log /var/log/nginx/host.access.log main; root /srv/www/vhosts/example.com; index index.html index.htm; location / { } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }I stowed this config in a directory on the data drive /mnt/datadrive/srv/nginx/default.conf
Then I can test it out:
docker run -it --rm -d -p 80:80 --name devweb \ --mount 'type=bind,src=/mnt/datadrive/srv/nginx/default.conf,dst=/etc/nginx/conf.d/default.conf' \ --mount 'type=bind,src=/mnt/datadrive/srv/www,dst=/srv/www' \ nginx:alpineAnd now if I drive to 'example.com' (not my actual domain, of course), I will get the web site. Note: if you try to reach the web site from the domain name on your local network, you might have some troubles if your server is behind NAT (which is likely). This is because the domain name will resolve to your external IP, and the router will probably not forward that request back inside if it coming from the inside already. You can work around this by adding some entries to your hosts file that resolve the names to your internal IP address, then it should work as expected even from inside the network.
Systemd
The Ubuntu on the host uses 'systemd' to start daemons (services). We want the nginx to start serving web pages on boot, so we need to do a little more config. First we need to create a 'service descriptor file' on the host:
/etc/systemd/system/docker.www.service
[Unit] Description=WWW Service After=docker.service Requires=docker.service [Service] TimeoutStartSec=0 Restart=always ExecStartPre=-/usr/bin/docker exec %n stop ExecStartPre=-/usr/bin/docker rm %n ExecStartPre=/usr/bin/docker pull nginx:alpine ExecStart=/usr/bin/docker run --rm --name %n \ --mount 'type=bind,src=/mnt/datadrive/srv/nginx/default.conf,dst=/etc/nginx/conf.d/default.conf' \ --mount 'type=bind,src=/mnt/datadrive/srv/www,dst=/srv/www' \ -p 80:80 \ nginx:alpine [Install] WantedBy=default.targetThis simply runs the nginx container much as we did before. It does a little cleanup beforehand to handle things like unexpected system crashes that might leave a container around.
After that file is in place, we tell systemd that we want it to be started automatically:
systemctl enable docker.wwwThis won't do anything for the current session, so this time we manually start it:
sudo service docker.www startUltimately, this is not how I'm going to be operating this particular service, but it's useful as a simple example, and it is perfectly fine in many cases. However, I also need PHP for my web site. PHP with nginx is done via 'PHP-FPM', which is a separate process. I am going to run that as a separate docker image. Since my www service will effectively be consisting of two docker images (at this point), I'm going to next use a tool called 'docker-compose' for that. It is a convenient way of composing services from multiple docker images, and is perfectly serviceable when you don't need full-blown container orchestration like with kubernetes.
Next
Add another service that provides PHP processor capability.
-
Dicker with Docker
11/10/2020 at 17:11 • 0 commentsSummary
Just exploring some Docker basics, with a bent towards Raspberry Pi when relevant.
Deets
The path to here is long and tortuous. Multics. Unix. VAX. 386. V86 mode. chroot. Solaris Zones. cgroups. LXC. and now, Docker.
The concept is similar to a chroot jail, which partitions off part of the filesystem namespace, except that much more is also partitioned out. Thinks like PIDs, network sockets, etc. The low-level technology being used on Linux is 'cgroups'. Windows also now has a containerization capability that is based on completely different technology.
'Docker' is a product built upon the low-level containerization technology that simplifies the use thereof. (lol, 'simplifies'. It's still a bit complex.) When you use the technology, you are creating a logical view of a system installation that has one purpose -- e.g. web server. This logical view of the system is packaged in an 'image' that represents the filesystem, and then is reconstituted into a 'container' that represents the running instance. The Docker program also helps with creating logical networks on which these containers are connected, and logical volumes that represent the persistent storage. The result is similar to a virtual machine, but it's different in that the contained applications are still running natively on the host machine. As such, those applications need to be built for the same CPU architecture and operating system -- well, mostly. It needs to be for the same class of operating system -- Windows apps in Windows containers running on a Windows host, and Linux on Linux. But with Linux you can run a different distribution in the container than that of the host.
Containers are much more resource friendly than full virtualization, and part of keeping that advantage is selecting a small-sized distribution for the container's OS image. Alpine Linux is very popular as a base for containerized applications, and results in about a 5 MB image to start with.
For my host OS, I chose Ubuntu server (18.02). To wit, Docker requires a 64-bit host system, so that is the build I installed. Initial system update:
sudo apt update -y && sudo apt-get update -y && sudo apt-get upgrade -y && \ sudo apt dist-upgrade -y && sudo apt-get autoremove -y && \ sudo apt-get clean -y && sudo apt-get autoclean -yFor historic reasons, I created a separate partition called 'datadrive' and set it up to mount via fstab. This is an artifact from migrating the system over the years -- originally it was a separate, large, drive. It contains application data files, such as databases, www, ftp, source control, etc. This is not a required setup, and I don't know that I even recommend it.
sudo bash -c 'echo "LABEL=datadrive /mnt/datadrive ext4 noatime,nodiratime,errors=remount-ro 0 1" >> /etc/fstab'Then I make a swap partition:
sudo fallocate -l 2G /var/swapfile sudo chmod 600 /var/swapfile sudo mkswap /var/swapfile sudo swapon /var/swapfile sudo bash -c 'echo "/var/swapfile swap swap defaults 0 0" >> /etc/fstab'It's useful to note that swapfile has compatibility issues with Kubernetes (aka 'k8s'), so if you eventually want to do that then you'll probably wind up turning that back off. But I'm not planning on doing k8s on this machine, so I turn it on for now.
Then it's time to do some installing:
# Install some required packages first sudo apt update sudo apt install -y \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common # Get the Docker signing key for packages curl -fsSL https://download.docker.com/linux/$(. /etc/os-release; echo "$ID")/gpg | sudo apt-key add - # Add the Docker official repos echo "deb [arch=$(dpkg --print-architecture)] https://download.docker.com/linux/$(. /etc/os-release; echo "$ID") \ $(lsb_release -cs) stable" | \ sudo tee /etc/apt/sources.list.d/docker.list # Install Docker sudo apt update sudo apt install -y --no-install-recommends \ docker-ce \ cgroupfs-mount #set dockerd to run on boot (and get it running now) sudo systemctl enable docker sudo systemctl start docker # Install required packages sudo apt update sudo apt install -y python3-pip libffi-dev sudo apt install -y libssl-dev libxml2-dev libxslt1-dev libjpeg8-dev zlib1g-dev # Install Docker Compose from pip (using Python3) # This might take a while sudo pip3 install docker-compose # run docker without sudo (will not be effective until log out/in) sudo usermod -aG docker $(id -u -n) #change boot mode to non-gui sudo systemctl set-default multi-user.target # to go back, set to 'graphical.target'Some Basic Docker Concepts
Images
Docker uses a virtual filesystem backed by an 'image'. These images are are composed of 'layers' which make up an overlay filesystem. That is, the effective view of the filesystem is that of the layers merged together. The top layer is read/write, the others are read-only. This will make more sense when I discuss building images, because that's where they are created.
If you issue:
docker infoYou'll get a lot of details about your installation. In particular:
... Docker Root Dir: /var/lib/docker ...which is where the images will be stored (amongst other things). Where specifically depends on other aspects of the configuration. In my case, the 'Storage Driver' is 'overlay2', and so the images are in '/var/lib/docker/overlay2'. You don't mess with these directly, though. Rather, you use the main 'docker' tool to execute various commands; e.g.:
docker image lswill list all the images and present the data in a more friendly way. There are a boatload of commands, q.v. docs at http://docs.docker.com, but I'll walk through a couple of the common ones here.
Registry
Docker supports the notion of a 'registry' containing images. There is a local registry on your system at /var/lib/docker, and there are external ones hosted by others. The most common is 'Dockerhub' at http://hub.docker.com. This is also the default that is built into the docker tool. The act of fetching an image from the remote repository into your local repository is called a 'pull', and sensibly the act of sending an image to a remote repository is called a 'push'. You can register an account on Dockerhub and push your images there, though there are some restrictions on the free account for how long they will keep them for you.
As I mentioned, Alpine Linux is a popular, so we can pull it:
docker pull alpine:latestthe second part of the name 'alpine:latest' is called the 'tag'. It is free-form, but by convention it is typically a version number. The value of 'latest' is also by convention meant to mean the latest release. There is no magic to this -- only convention (with the possible exception that if you were to pull 'docker pull alpine' that the tool will assume the tag of 'latest').
This brings the image into your local registry. But it's just a virtual filesystem image -- it's not alive. You can list the images 'docker image ls' and see stuff:
REPOSITORY TAG IMAGE ID CREATED SIZE alpine latest 2e77e061c27f 2 weeks ago 5.32MBContainers
To get it running, you need a 'container'. The container is the execution environment instantiated on the image. Because the filesystem is overlaid, and because the top layer is the only read/write one, you can start multiple containers on the same image and these will not interfere with each other, because they will have distinct top layers.
docker container run -it alpine shand you'll be put in 'sh' inside the container, as root:
/ #You can poke around and see that you are definitely not on your host system. To exit, just 'exit' as per usual and you will be put back on your host system. Since the main application 'sh' has now exited, the container is also stopped. Stopped containers still take up resources, though. You can see them:
docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8ecf6e60bc1a alpine "sh" 9 minutes ago Exited (0) 8 seconds ago youthful_elionYou need the -a switch so that even the stopped ones will be shown. They will hang around forever, so you need to remove them explicitly:
docker container rm 8ecfYou can specify either the 'container id' or the 'name'. When we created the container, we didn't specify a name, so the docker tool made a random one up 'youthful_elion'. If you use the container id, you only need to specify enough leading hex digits to disambiguate from others -- I usually just use the first four.
I guess it became somewhat of an annoyance to manually removed stopped containers, because there is an option to have the container auto-remove whenever the main application has exited; e.g.:
docker container run -it --rm alpine shThe '--rm' means 'auto remove on stop'. I should mention at this time that the '-it' option means 'interactive' and also 'tty'. This means that the container will be connected to the terminal of the host, and that was what enabled us to interact with the program running inside, 'sh'. In most docker containers, you would be running something other than the shell. The image typically has a command specified to run, rather than your having to provide it when starting the container. This Alpine image is used as a base system, so it doesn't have that. More on this when we get to building a new image.
Now you can see that when you exit the 'sh' on the container, that it will have auto removed itself as per 'docker container ls -a'. The auto-remove feature is handy when doing development and testing.
Another handy thing is to be able to start another process in your container. It is handy to launch and interactive shell into the container so you can poke around from the container's viewpoint of its filesystem. To demonstrate, we'll get a container running, then return to the host system while leaving it running, then make a separate shell process that notionally we could use to poke around.
docker container run -it --rm alpine shOK, now you're in the container. You can leave the container without stopping it by using the key sequence 'Ctrl-P,Ctrl-Q'. You can see the container is still running:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 66e39b791db0 alpine "sh" 50 seconds ago Up 47 seconds hardcore_pikeNow you can exec a new shell in it to poke around:
docker container exec -it hardcore_pike sh / #you can run 'ps' and see the first shell (still running) and the new one we are running now:
ps -ef PID USER TIME COMMAND 1 root 0:00 sh 6 root 0:00 sh 12 root 0:00 ps -efNetworks
It's useful to notice that docker creates a network adapter in these containers:
/ # ifconfig eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02 inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0You can reach the host from within the container, and other systems on your network, however those systems cannot reach your container. To do that, you need to 'publish' some port from your container. We'll cover this later when we build some more interesting images.
If you 'exit' the (second) shell, you will be back at the host, with the container still running. Another way of getting back into the container is with an 'attach' command. This does not start a new process in the container, but rather re-establishes the link with the terminal session therein.
docker container attach hardcore_pikeThen you'll be back in. You can see that this is the original shell with 'ps -ef'. And now if you 'exit', the container will be 'stopped'. If it was started with '--rm' it will also be auto-removed.
Volumes
The containerized environment does not have access to the filesystem outside of the container. However, you can make that available as needed. There are two modes of doing so: 'volumes' and 'binds'. 'Volumes' are virtualized filesystems much like the docker image itself, and 'binds' are like a mount point, making a file or directory on the host visible within the container. I'm not going to show this now, but it will be used in later examples to make data on the 'datadrive' partition visible to the containerized application.
Next
Using an existing image.
-
Dockerize All the Things!
11/09/2020 at 18:31 • 0 commentsSummary
I had a 'hard drive' (really, SD card) crash, and now I am in data recovery mode. I will have to rebuild the server. I will lick my wounds in the modern, containerized, way.
Deets
Youth
I have run a home server for decades -- I assume most have at this point. Back in the day it was a relegated desktop system (a 66 MHz Pentium with the floating point bug, lol) but progressively it migrated to embedded devices like a WRT54GL, an NSLU2, a SheevaPlug, and finally to a RaspberryPi. The server provided WWW, FTP, SSH, SMB, MySQL, SCM, and later VPN. It primarily served media for the home, and a gateway into the home from outside. Over the years, some of that responsibility was delegated to other things (such as a dedicated NAS for storage), and I use client-server database less now (preferring embedded application-specific databases using sqlite). But it is still handy to have a server for the other things, either for legacy support or most critically for VPN.
The latest stage of that evolution led to using a Raspberry Pi 3, and a 32 GB SD card for the filesystem. Both of those things are wonderfully cheap and compact and silent and low power, but they are neither server-grade components. Hardware failures are more frequent with these consumer products. I lost my SheevaPlug after many years of service (the device had a well-known design defect in the power supply). Although it was a bit of a hassle to migrate to the Raspberry Pi replacement, it was surmountable -- just yet another lost weekend to home IT work.
Sorrow
My latest system failure was more catastrophic. As best as I can tell, I think the Raspberry Pi is OK, but rather the SD card is intrinsically defective. And I did not have recent backups, so I was faced with data loss and re-deploying software and configuration. Shame on me, of course, but there I was nonetheless, and that was the task before me.
I did at length (I think!) manage to recover the data -- that's the most critical thing -- but it took several IT weekends. My bulk storage was not on the server, and the web stuff and ancient database stuff hadn't been modified in many years, so I was able to recover that from old backups. The source code control was my big fright (indeed, that's how I found out about the fault -- I couldn't check in code), however one of the great things about modern distributed SCM is that the clones can be used to reconstitute the one you consider as the 'master'.
Resurrection
The obvious path is to just, yet again, install all the software, and configure it appropriately, and refer to the existing bulk data. Had I chosen that path, I would not be writing this log. That path would take a while to do, however I have decided to make my life harder and instead re-design the server's configuration. There is a more modern technology called 'containerization' that is increasingly becoming popular for deploying services, so why not use this opportunity to explore that?
'Containers' are somewhere in between a chroot jail and a virtual machine. There are several alternative technologies involved, but the most prominent one at present is 'docker'.
So I am setting out to reconstitute my server, but as much as possible containerize my former services using docker containers. What does this mean specifically? Well, I'm going to find out!
Next
Dicker with Docker
Dockerize All the Things
hard drive crash! recover, revive, and re-engineer server using docker contained services this time.