
Introduction
In this project I will explore the possibilities of the OpenAI API to generate code on the fly, without any human intervention.
OpenAI Codex is a new tool that opens new cool applications, especially if your platform runs an interpreted language, like micropython. Even more, there is an API that can be accessed from anywhere via simple HTTP POST.
The results are amazing, a 300 line python game that works without any needed modification (about 80% of the trials).
Hardware description
The platform I'm using is Pico-W, because it is present on my desk these days, but ESP32 is a perfect target for this application.
To have something to play with, I'm using a small SPI TFT board from Waveshare, with 240x135 pixels, a joystick and two buttons. This should be enough to have fun.

Connecting to OpenAI
Access to the OpenAI API is done via a standard HTTP POST operation, making micropython's urequets and ujson libraries perfect for this.
The code is shown below, in the example it connects to the internet, sends a "Hello " to Codex and Codex responds with "World!".
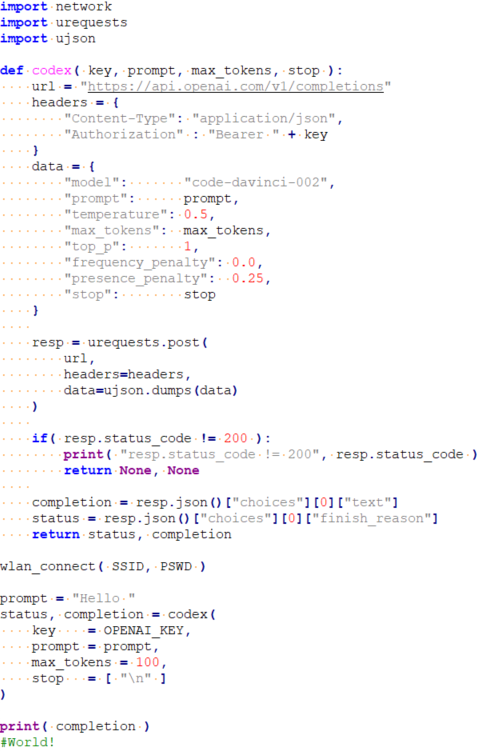
To access OpenAI Codex, we need some credentials, which we can obtain if we have registered for the service. Currently the cost of this “code-davinci-002” model is free, but other similar models cost $0.02 per 1000 tokens (1 token ≈ 1 word). The pong games we are testing are about 1000 words long, so they cost $0.02 for each new game.
In the request to OpenAI, we indicate the model that we want to use, the maximum size that we want to generate in tokens, the stop conditions and our text to continue or prompt.
We also have a parameter called "temperature" that will allow us to adjust the "randomness" of the response, with 0 it always responds the same and with higher values the responses are more varied and increasingly "crazy".
The number of queries that we can make through the API is limited to 20 queries per minute (this prevents Skynet from being born), so OpenAI will return an error if we make many queries in a row, but if this happens, we just have to wait a few seconds and everything It works again without needing to do anything else.
Prompt engineering
The interesting job, once we can connect to OpenAI, is to develop a program that Codex can continue to have a complete Pong game. For this, the first thing we need are some comments in which we will indicate the game, the classes that make it up and everything that comes to mind.
To detect when the game is finished and to be able to stop the generation in a python program without errors (not in the middle of a line or something like that) we indicate that a “print(“done”)” will mark the end and then we use this as parameter of stop when making the call to OpenAI.
The libraries used, the initialization of the HAL and the main function will give Codex a clearer idea of the type of code we want to generate as well as how the game should run.
The last line is the start of the Pong class that we want Codex to complete.

Some interesting things about the prompt:
- As Codex generates the API that it saw on Github and not the one you want, it often uses framebuff functions that are not in the v1.19.1 version that PicoW runs, so you have to put the LCD API as comments for Codex to use. This doesn't guarantee that it will get it right, but it usually works.

- At the beginning of the game the welcome message is shown to start the game, this is mainly done to give an example to Codex of how we want to display the text, color, position etc. If we put the text in white text and without “frills”, the generated games will be more “basic” too.
If we use a slightly more elaborate message, focused, with colors and a box, Codex will follow this pattern throughout the code and generate more visually appealing games.

Some issues with the completions:
Sometimes Codex makes a mistake and tries...
Read more »

 Kyall
Kyall
 Ken Yap
Ken Yap
 Louis Paul
Louis Paul
 Roni Bandini
Roni Bandini
Love it! Elliot spotted this over on IEEE Spectrum and tipped us off to it, so I just wrote it up for the blog. I'm dying to know if something more complex would work, like Tetris.
Very cool, good work. And thanks for hosting the project here -- hopefully we'll see some traffic come over from the Spectrum article. Thanks!