In the past weeks, I've been working on a new pcb design. That's now almost done.
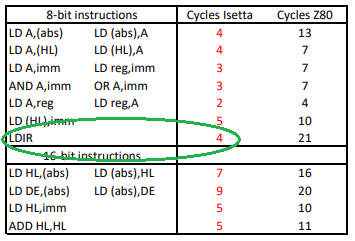
This weekend I looked at my TODO list, and I found, no surprise, the LDIR instruction.
In one of the previous logs I mentioned that there was an error in the LDIR instruction. It didn't behave correctly when an interrupt occurred.
What is the LDIR instruction ?
In the Z80 processor, this instruction can copy a whole section of memory in just a single instruction. It takes three 16-bit sized values as input:
- A source address in register pair HL
- A destination address in register pair DE
- A byte count in register pair BC
LDIR stands for Load, Increment, Repeat.
It will do the following actions:
- read a byte from the address at location HL
- write that byte at location DE
- increment the addresses in HL and DE
- decrement the byte counter in BC
- if the byte counter is not zero, repeat the actions
- if an interrupt occurs during this instruction, it will be handled and the actions will continue after interrupt is handled.
LDIR has a 2-byte opcode: ED B0
Optimizing the LDIR
The LDIR was already optimized, with 10 cycles per copied byte, but I had the strong feeling that something better was possible. I didn't try to find the problem in the old version, just started again from scratch.
Isetta has only a single hardware data pointer. But nothing keeps us from using the program counter as a data pointer ! For a normal instruction, that would cost way too many cycles, but for a repeated transfer instruction this will pay off. The LDIR microcode should just save the PC to a temporary location, and copy the HL register pair into the PC. Now the PC can be used to get the bytes out of memory. When all actions are completed, the PC is copied back to HL, and PC is restored from the temporary location. The existing, broken LDIR version also had this feature.
And as a bonus, the PC register can increment in the same cycle where it addresses a byte to be fetched.
The destination pointer (register pair D E) is copied to the hardware registers DPH and DPL. The byte, fetched with the address in PC, can now be stored at the address in DPH/DPL. There is a microinstruction that increments DPL, it can also detect a carry, but there is no possibility to increment the DPH register, because it can not be accessed after the change that is described HERE. But we could increment the D register and re-write DPH with the result. This will at least take 3 more cycles (microinstructions).
Then we must decrement the count in the BC registers. So first decrement C (2 cycles) and, when it drops below zero, decrement B (also 2 cycles).
The problems are in the counting, and in the increment of the upper byte (DPH),
But if we unroll the loop, in sections of 8 transfers, we don't have to count each byte. We simply subtract 8 from the LSB of the count, at the beginning of the unrolled loop. But when the count is lower than 8, we jump to a slow old-fashioned loop. This will decrement the MSB of the count when that is needed, and then go back to the unrolled loop. The slow loop will also check for zero to determine if the instruction has completed.
It would be nice if we never had to increment the upper byte (DPH)... What if we never increment the upper byte in the unrolled loop ? Before the unrolled loop starts, we could check if the lower byte (DPL) would overflow in that loop. That would happen if that lower byte is higher than 0xF7 (247), and in that case we do the old-fashioned loop, and when the upper byte has been incremented, we go to the unrolled loop again.
Now, the sections of the unrolled loop have only 3 cycles:
- A <- (PC++)
- (DPH/DPL) <- A
- inc DPL
Pseudo code of the fast copy loop:
- if LSB of the count < 8, goto slow loop
- if LSB of destination > 247, goto slow loop
- count = count - 8
- copy the DE registers (destination) into DPH/DPL
- destination = destination + 8;
- do the unrolled loop 8 times
- go back to fast copy loop
In this fast loop, there are 8 cycles of overhead, that brings the average number of cycles per byte transfer to 4.
Actually, the slow loop that occasionally must be executed during big transfers will bring the average to around 4.4.
Overhead at beginning and end of the instruction (saving PC, put HL in PC, saving A, restoring them) cost 27 cycles.
And here is the microcode
This listing is produced by the Javascript microcode generator. I added some comments.
---- page 0 ED B0 LDIR ---- // start with checking the interrupt. If interrupt, go to addr 32 in page_z80_ix 001600 066224 0132C0 F:[to_ir <- lit32,p_z80_ix] T:[reg_v <- acc_a] 001602 012220 010022 F:[to_dpl <- 0] T:[to_t <- pcl] 001604 013259 013259 reg_tl <- acc_t 001606 01524D 01524D pcl<-pch, to_pch <- reg_l 001608 010022 010022 to_t <- pcl 00160A 013258 013258 reg_th <- acc_t 00160C 01524C 01524C pcl<-pch, to_pch <- reg_h // obtain the value 0x98 (microcode can not use arbitrary immediate values) 00160E 0B0222 0B0222 to_t <- asl(lit8) 001610 0E0222 0E0222 to_t <- or(acc_t, lit8) 001612 0E0246 0E0246 to_t <- or(acc_t, reg_128) // store the opcode (0x98) of the fast loop at temp location reg_vga_acc 001614 01325B 01325B reg_vga_acc <- acc_t 001616 00625B 00625B to_ir <- reg_vga_acc,p_z80_ed // jump to opcode 0x98 001618 0132C0 0132C0 reg_v <- acc_a -- 0/13 + 2 cycles ---- page 0 ED 98 LDIR-LOOP ---- 001300 014249 014249 to_a <- reg_c 001302 3C42A2 3C42A2 to_a <- sub(acc_a, lit8) 001304 610A4B 610A4B to_t <- reg_e,tc_to_f // if F=0, move lit32 (0x20) to IR to go to the slow loop 001306 006224 0D0222 F:[to_ir <- lit32,p_z80_ed] T:[to_t <- add(acc_t, lit8)] 001308 612A4B 612A4B to_dpl <- reg_e,tc_to_f 00130A 01124A 006224 F:[to_dph <- reg_d] T:[to_ir <- lit32,p_z80_ed] 00130C 0132C9 0D0220 F:[reg_c <- acc_a] T:[to_t <- add(acc_t, 0)] 00130E 01324B 01324B reg_e <- acc_t 001310 014008 014008 to_a <- (pc++) 001312 E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 001314 2A2122 2A2122 to_dpl <- inc(dpl) 001316 014008 014008 to_a <- (pc++) 001318 E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 00131A 2A2122 2A2122 to_dpl <- inc(dpl) 00131C 014008 014008 to_a <- (pc++) 00131E E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 001320 2A2122 2A2122 to_dpl <- inc(dpl) 001322 014008 014008 to_a <- (pc++) 001324 E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 001326 2A2122 2A2122 to_dpl <- inc(dpl) 001328 014008 014008 to_a <- (pc++) 00132A E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 00132C 2A2122 2A2122 to_dpl <- inc(dpl) 00132E 014008 014008 to_a <- (pc++) 001330 E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 001332 2A2122 2A2122 to_dpl <- inc(dpl) 001334 014008 014008 to_a <- (pc++) 001336 E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 001338 2A2122 2A2122 to_dpl <- inc(dpl) 00133A 014008 014008 to_a <- (pc++) // if F=1, interrupt not active, go back to the start of the fast loop 00133C 010220 00625B F:[to_t <- 0] T:[to_ir <- reg_vga_acc,p_z80_ed] 00133E E13980 E13980 (dph|dpl) <- acc_a,irq_to_f 001340 010022 010022 to_t <- pcl 001342 01324D 01324D reg_l <- acc_t 001344 010259 010259 to_t <- reg_tl // Before going to interrupt code, sub_0(acc_t,1) will do PC = PC - 2 // So after the interrupt, this LDIR will be re-executed 001346 1C5221 1C5221 pcl<-pch, to_pch <- sub_0(acc_t, 1) 001348 010022 010022 to_t <- pcl 00134A 01324C 01324C reg_h <- acc_t // The dec_dtc will only do a decrement if the previous subtract crossed zero. 00134C DB5258 DB5258 pcl<-pch, to_pch <- dec_dtc(reg_th) 00134E 006246 006246 interrupt, nop 001350 E14AC0 E14AC0 to_a <- reg_v,irq_to_f -- 0/41 + 2 cycles ---- page 0 ED 20 LDIR-SLOW ---- 000400 010249 010249 to_t <- reg_c 000402 0E2248 0E2248 to_dpl <- or(acc_t, reg_b) 000404 1B2122 1B2122 to_dpl <- dec(dpl) 000406 612ACB 612ACB to_dpl <- reg_e,tc_to_f // F=0: count is zero. Restore registers and go to next instruction 000408 010022 01124A F:[to_t <- pcl] T:[to_dph <- reg_d] 00040A 01324D 014088 F:[reg_l <- acc_t] T:[to_a <- (pc++)] 00040C 015259 013180 F:[pcl<-pch, to_pch <- reg_tl] T:[(dph|dpl) <- acc_a] 00040E 010022 2A024B F:[to_t <- pcl] T:[to_t <- inc(reg_e)] 000410 01324C 01324B F:[reg_h <- acc_t] T:[reg_e <- acc_t] // The inc_dtc will only do an increment if the previous increment produced a carry. 000412 015258 CA024A F:[pcl<-pch, to_pch <- reg_th] T:[to_t <- inc_dtc(reg_d)] 000414 046008 01324A F:[next, nop] T:[reg_d <- acc_t] 000416 E14AC0 1B0249 F:[to_a <- reg_v,irq_to_f] T:[to_t <- dec(reg_c)] 000418 013249 013249 reg_c <- acc_t 00041A DB0248 DB0248 to_t <- dec_dtc(reg_b) 00041C E13A48 E13A48 reg_b <- acc_t,irq_to_f // If interrupt not active, jump back to fast loop 00041E 010220 00625B F:[to_t <- 0] T:[to_ir <- reg_vga_acc,p_z80_ed] 000420 010022 010022 to_t <- pcl 000422 01324D 01324D reg_l <- acc_t 000424 010259 010259 to_t <- reg_tl // Before going to interrupt code, sub_0(acc_t,1) will do PC = PC - 2 // So after the interrupt, this LDIR will be re-executed 000426 1C5221 1C5221 pcl<-pch, to_pch <- sub_0(acc_t, 1) 000428 010022 010022 to_t <- pcl 00042A 01324C 01324C reg_h <- acc_t 00042C DB5258 DB5258 pcl<-pch, to_pch <- dec_dtc(reg_th) 00042E 006246 006246 interrupt, nop 000430 E14AC0 E14AC0 to_a <- reg_v,irq_to_f -- 12/25 + 2 cycles
Maximum number of cycles per instruction
The fast copy loop will take 8 * 3 + 8 (overhead) = 24 cycles. It is actually longer, because it also tests the interrupt line, and when that is active, it restores the registers, and jumps to the interrupt code. (and before jumping to the interrupt code, it sets the PC two positions back, so the LDIR will be re-entered after the interrupt has been serviced).
But I said somewhere before, that each instruction has max 16 cycles !
Well, actually, the lower 4 bits of the instruction register are in a counter chip. So when the 16 cycles are executed, and no new instruction was fetched, execution continues in the microcode of the next opcode ! So, a maximum of 256 different cycles can be executed, and after that the same 256 cycles come again, until it jumps out of that sequence somewhere.
Of course, when this system is used, the next opcode should not be defined as a normal instruction.
For the LDIR instruction (opcode 0xB0 in the Z80_ED page), a few initializations will be done in the opcode 0xB0 microcode, but will then jump to the fast loop at address 0x98 in the same page. That is an opcode that is undefined by the Z80, and also the opcodes that follow it (0x99, 0x9A) are undefined. That is where our LDIR fast code lives. It can also do a jump to the slow loop, at 0x20. The slow loop also uses the next opcode, 0x21. Both 0x20 and 0x21 are undefined Z80 opcodes.
LDDR
I could do the same for the LDDR (load-decrement-repeat) instruction, but I did not do that, because it is used less often (only when source and destination range overlap in a certain way). Also, it would mean that PC had to decrement instead of increment. Decrementing the PC is not a hardware function, but it could be done by microcode, at two extra cycles per transfer. So if LDDR got the same treatment, the average time would be 6.4 cycles per transferred byte.
So the LDDR is a standard loop, a byte transfer costs 21 cycles.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.