Demo
Status
TODO:
- Refinement (robustness, edge cases, UX improvements)
- Try eye tracking for mouse?
Pipeline
The basic pipeline is shown in the diagram below. A small quantized CNN (36x36 input, 4 layers, 10k parameters) processes the downscaled camera input directly, producing a binary classification (eye closed or open). Using this and previous eyelid states and timestamps, the Morse code is decoded into characters, which are sent over BLE to the host device.
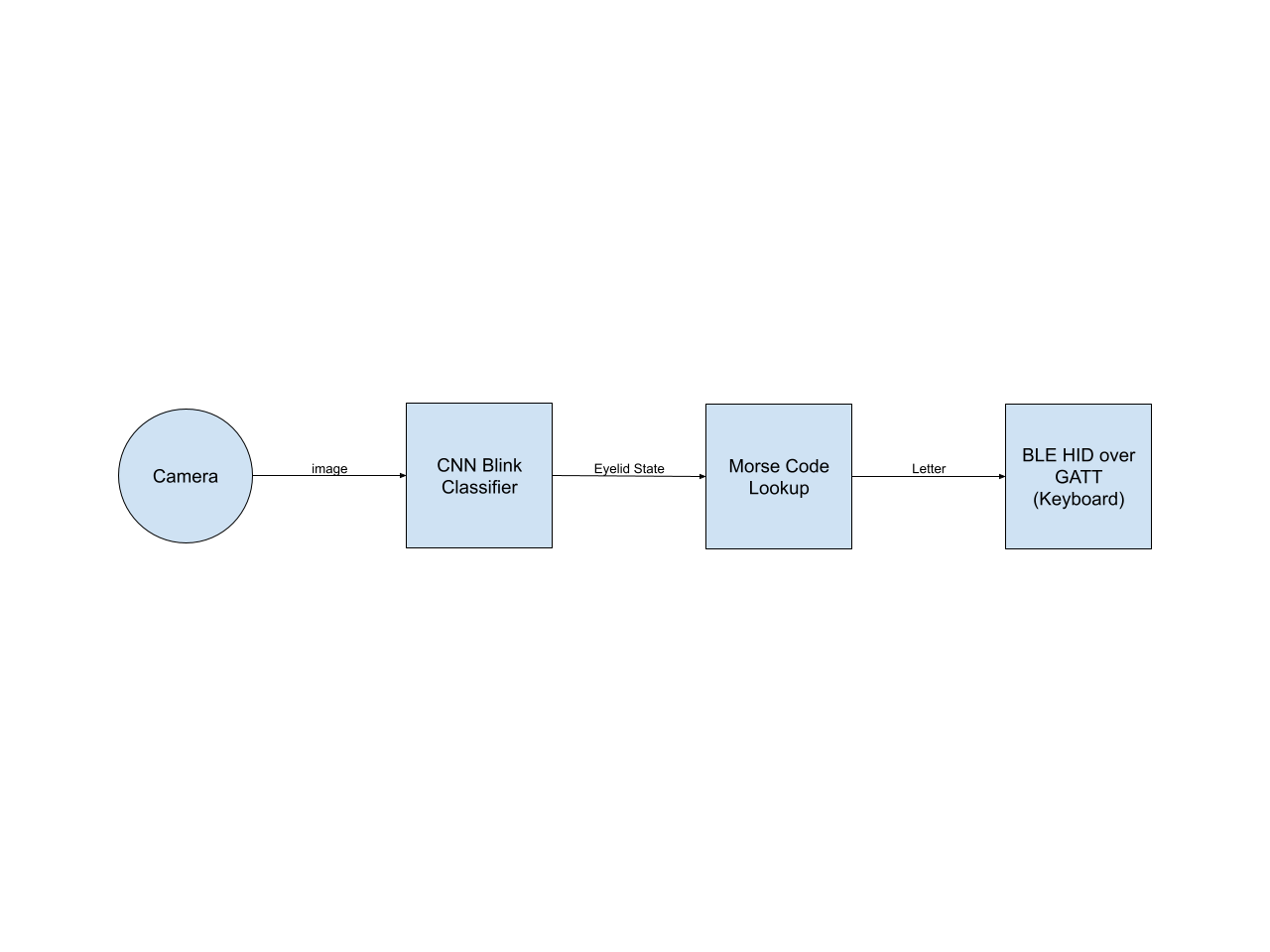
Previous Iterations
The first attempt used Dlib's facial landmark model based on “One Millisecond Face Alignment with an Ensemble of Regression Trees” after running face detection on the frame; the resulting eye coordinates would then be used to calculate the eye aspect ratio and judged to be open or closed depending on a threshold value. However, this was found to be quite inaccurate, and requires the camera to be further away from the face.
The next iteration used a Haar cascade detector which provided the bounding box for the image segment given to an XGBoost classifier. Although this worked rather well, especially since XGBoost isn't meant to be used for raw images, and is very fast (~4ms), it was rather fragile when the eye is not completely centered, hence the need to preprocess with the bounding box.
Firmware
The firmware is written in ESP-IDF to extract the most performance out of the device. OpenCV is used for resizing and text rendering, while the classifier uses TFLite for Microcontrollers, running a quantized int8 model, taking 20ms to run.
The Morse code lookup is currently done through a binary encoding array.
The BLE keyboard is implemented through the standard BLE HID over GATT protocol using the nimBLE stack.
For debugging, the ESP32 creates a video stream over WiFi with annotations, as shown in the video at the top.
OpenCV on ESP32
Compiling OpenCV for ESP32 is a bit of a pain. Following https://github.com/joachimBurket/esp32-opencv on the latest HEAD will get you 90% of the way there, while there is another issue due to type sizes (int32_t is long); this pull request takes cares of it. See the CMake file and the patch file in the repo (under components).
Dlib was used for preliminary exploration; it is quite simple to compile in comparison.
Previous Iterations
Dlib was compiled for the preliminary attempt, requiring just a couple of flags to build. A stripped down eye localization model took ~60ms to run on a 320x240 image.
The Haar cascade file was loaded from an XML which is stored in flash using a CMake function in ESP-IDF. It took up to 400ms to run, so it was run only occasionally.
XGBoost was deployed using generated C from an XGBoost classifier using m2cgen, and took 4ms.
ML
The MRL dataset is used for training. The images are resized to 36x36, and some augmentation (brightness, contrast, shifting, scaling, rotating) is done. The CNN is trained in Pytorch, then exported to ONNX, Tensorflow, and Tensorflow Lite, and finally quantized to 8-bit integers.
Physical Device
Currently, the device consists of a repurposed face shield frame, which are basically just lensless glasses, a 3D printed holder, and the ESP-EYE itself. The camera is positioned as such because it matches the images in the dataset; if there is another freely available blink dataset with a side view, then a less intrusive design could be built.

 Nait Malek Youssef
Nait Malek Youssef
 AIRPOCKET
AIRPOCKET
 Aidan Porteous
Aidan Porteous