 Bertrand Selva
Bertrand SelvaThis project presents a compact, affordable system capable of determining the direction and elevation of a sound source using a Raspberry Pi Pico microcontroller.
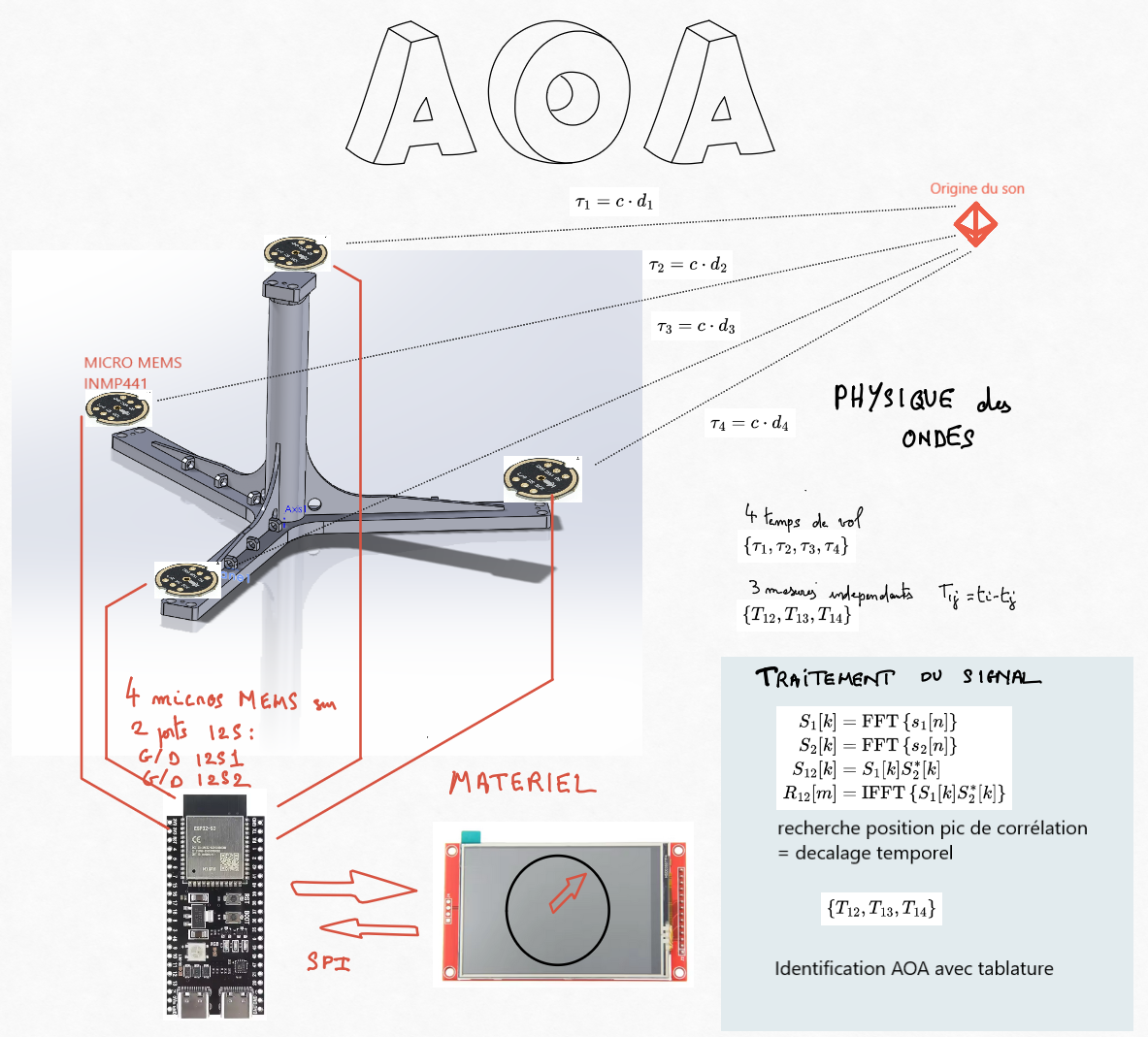
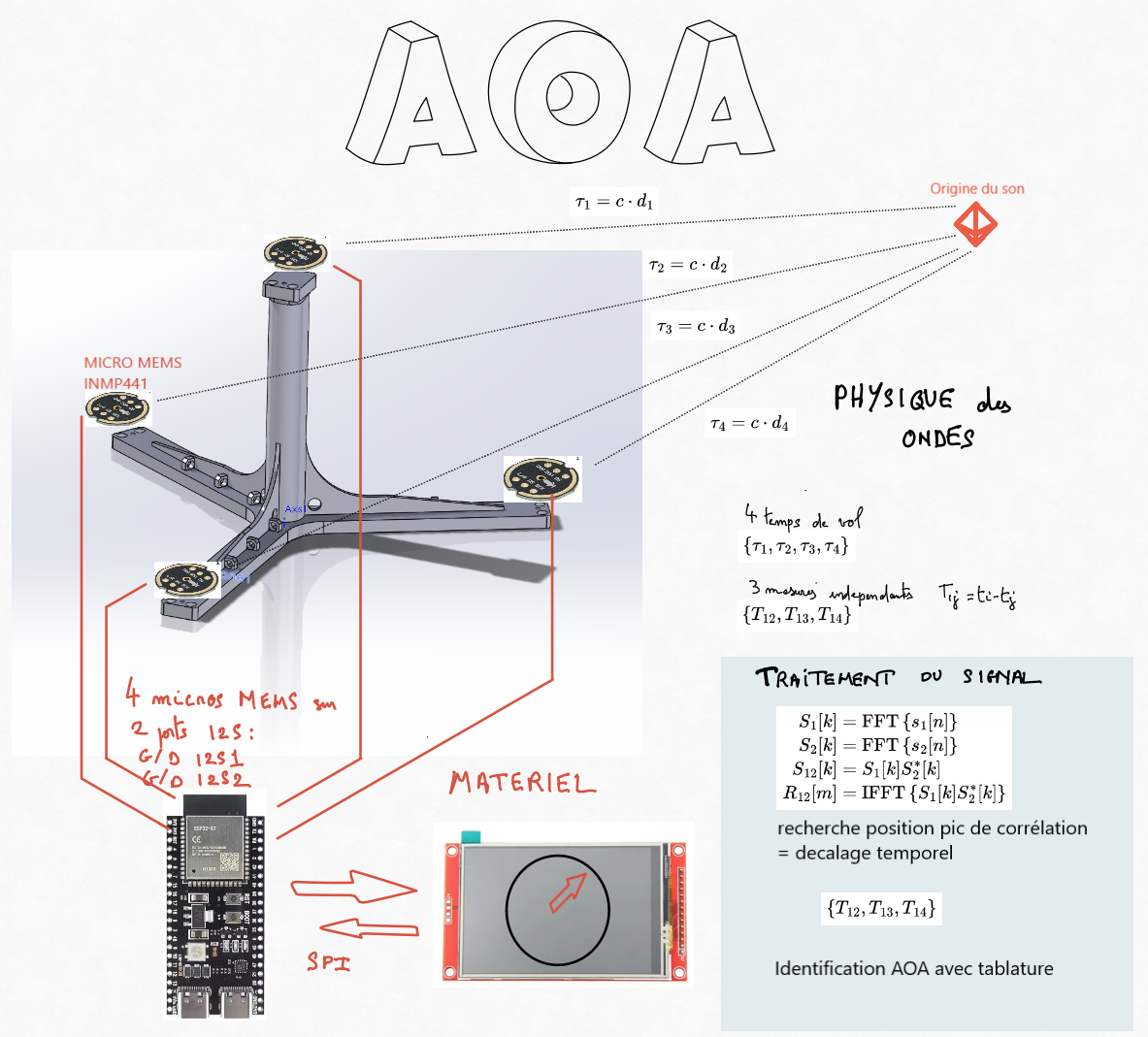
Operational Mechanics
Upon detecting a sufficiently loud sound, the system:
-
Captures audio signals from all four microphones.
-
Applies Fast Fourier Transforms (FFT) to convert time-domain signals into the frequency domain.
-
Computes cross-correlations between microphone pairs in the frequency domain using the formula:
R(τ) = INV_F{F{x(t)} · F{y(t)}*}
where F denotes the Fourier Transform, INV_F its inverse, and * indicates the complex conjugate.
-
Identifies time delays by locating the maxima in the cross-correlation functions.
-
Determines the sound source's direction by referencing a precomputed lookup table based on these delays.
-
Displays the result on the touchscreen, indicating the direction with a graphical pointer.
This method offers computational efficiency with a complexity of O(n log n), suitable for real-time processing on resource-constrained hardware.
Demonstration
A demonstration video showcases the system's responsiveness, with processing times of just a few hundred milliseconds. The red LED indicates the processing phase, and the touchscreen provides immediate visual feedback on the detected sound direction.
Limitations
-
Static Sound Sources: The system assumes stationary sound sources; moving sources can introduce inaccuracies due to unknown velocities.
-
Single Source Detection: Designed for single-source scenarios; multiple simultaneous sources may complicate localization.
Potential Enhancements
-
ESP32 Integration: Utilizing an ESP32 microcontroller with I2S ports and DSP capabilities can enhance performance and allow the use of MEMS microphones.
-
LoRa Communication: Implementing LoRa modules enables multiple units to communicate, facilitating triangulation over larger areas.
-
Drone Deployment: Mounting the system on drones can provide rapid, wide-area sound source localization.
-
Deep Learning for Sound Classification: Incorporating neural networks can allow the system to classify different sound types, such as distinguishing between gunshots, machinery noise, or human voices.
Applications
This low-cost, efficient system has potential applications in:
-
Robotics: Enhancing environmental awareness through sound direction detection.
-
Security: Detecting and localizing unusual sounds in surveillance scenarios.
-
Search and Rescue: Locating individuals in distress through sound cues
Example of On-Device Deep Learning Classification
A keyword spotting application showcasing this approach is presented in the following video:
This demonstration is based on a neural network with a few thousand parameters, capable of performing one inference every 250 ms on an ESP32 microcontroller. It is detailed in the Deep Learning section of the website: selvasystems.net
Such a model can easily be adapted to detect specific sound signatures (screams, impacts, engines) and combined with localization to enrich the analysis.

 Raymond Lutz
Raymond Lutz
 Renats K
Renats K

 Détourner
Détourner