 Neil K. Sheridan
Neil K. Sheridan-
Retraining TensorFlow Inception v3 using TensorFlow-Slim (Part 1)
04/08/2017 at 19:19 • 0 commentsUPDATE: THE GITHUB CODE HAS MOVED! YOU CAN FIND THE FLOWERS SCRIPT HERE NOW https://github.com/tensorflow/models/blob/master/research/slim/scripts/finetune_inception_v3_on_flowers.sh
1, I got started with TensorFlow today using TensorFlow-Slim. This is a "lightweight high-level API of TensorFlow (
tensorflow.contrib.slim) for defining, training and evaluating complex models in TensorFlow". There's code in the repository here for retraining many of the Convolutional Neural Network (CNN) image classification models. I'll be retraining Inception v3. I'm logging my full protocol here, so you can play/follow-along if you want!The maintainers of TensorFlow-Slim are:
- Nathan Silberman, github: nathansilberman
- Sergio Guadarrama, github: sguada
The code in the repository is licensed under https://www.apache.org/licenses/LICENSE-2.0.html (unless otherwise stated).
Protocol for retraining Inception v3 using the flowers dataset with TensorFlow-Slim:
- $ virtualenv --system-site-packages tensorflow
- $ source ~/tensorflow/bin/activate # bash, sh, ksh, or zsh
- $ pip install --upgrade tensorflow # for Python 2.7 [See https://www.tensorflow.org/install/install_linux for more details]
- $ source ~/tensorflow/bin/activate # bash, sh, ksh, or zsh
- Validate with a python hello tensorflow
import tensorflow as tf hello = tf.constant('Hello, TensorFlow!') sess = tf.Session() print(sess.run(hello))
6. Create a directory, and install the TF-Slim image models library with:
$ git clone https://github.com/tensorflow/models/
7. $ cd models/slim and create a directory to download the flowers dataset to. This dataset has 5 categories of flowers with 2500 flowers images. So mkdir DATASET
8. So you need to download the dataset convert it to TensorFlow's native TFRecord format. Happily they already wrote everything, which we got from github. So here we run it:
$ python download_and_convert_data.py \ --dataset_name=flowers \ --dataset_dir="DATASET"9. The TFRecord files should be all in your DATASET directory now! They actually wrote an .sh to do it all, but I did it myself since I'm using an EC2 machine and I prefer to do it myself anyway.
10. Make a pre-trained checkpoint directory mkdir PRETRAINEDCHECKPOINTDIR
11. Get the checkpoint for Inception v3 and put it in the PRETRAINEDCHECKPOINTDIR
$ wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz $ tar -xvf inception_v3_2016_08_28.tar.gz $ mv inception_v3.ckpt PRETRAINEDCHECKPOINTDIR12. Now we mkdir TRAINDIR, and we retrain the final layers of the CNN for 1000 steps using the new flowers dataset!
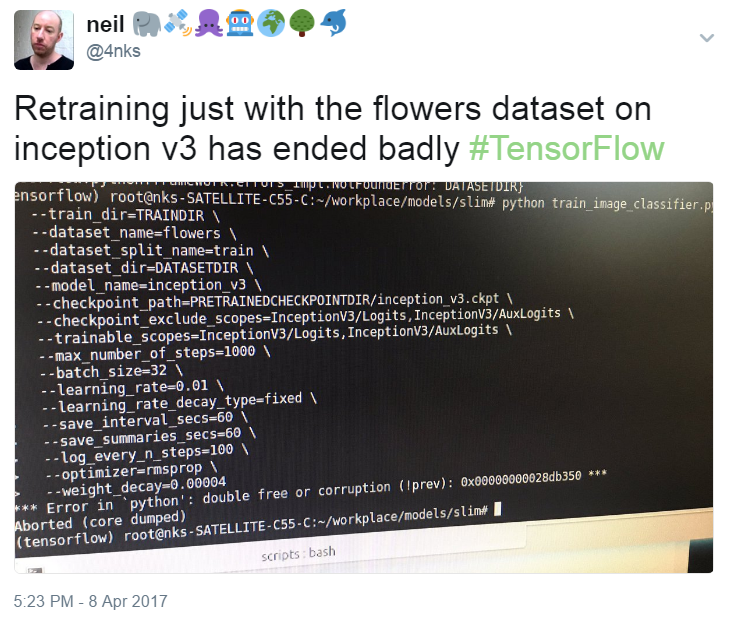
python train_image_classifier.py \ --train_dir=TRAINDIR \ --dataset_name=flowers \ --dataset_split_name=train \ --dataset_dir=DATASET \ --model_name=inception_v3 \ --checkpoint_path=PRETRAINEDCHECKPOINTDIR/inception_v3.ckpt \ --checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \ --trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \ --max_number_of_steps=1000 \ --batch_size=32 \ --learning_rate=0.01 \ --learning_rate_decay_type=fixed \ --save_interval_secs=60 \ --save_summaries_secs=60 \ --log_every_n_steps=100 \ --optimizer=rmsprop \ --weight_decay=0.00004I got the following error when I tried on my i5 laptop with 8GB!![]()
That's a memory error in this context. Anyway, it worked fine on the Amazon EC2 machine. It was an m4.4xlarge with 64GB.
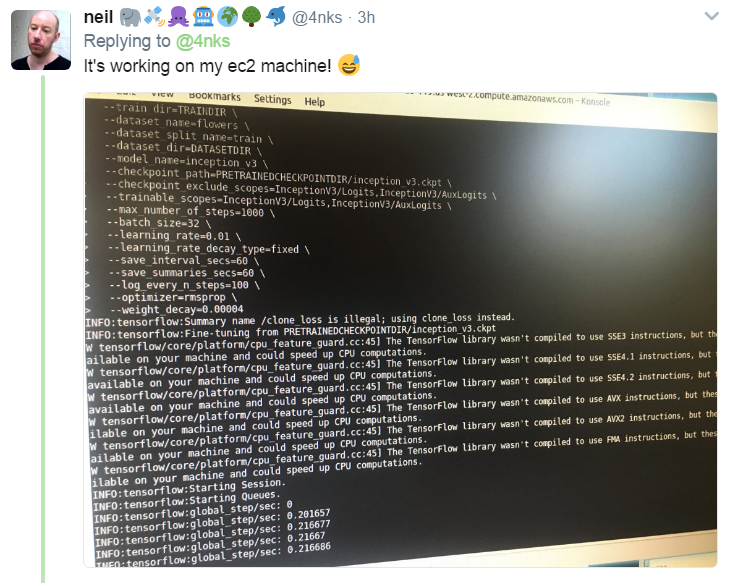
![]()
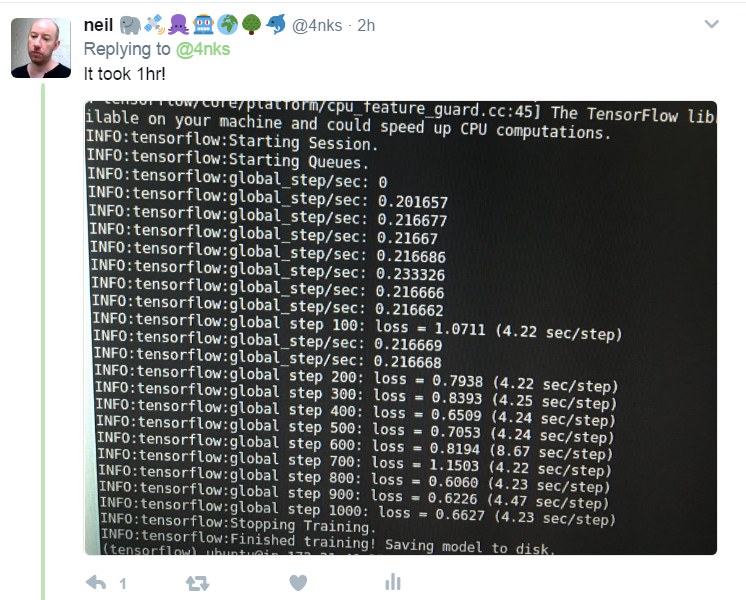
It was quite slow. It took 1hr to complete the 1000 steps using CPU only. Also you can see in errors: since TensorFlow was installed using pip (I didn't compile it), it isn't using Intel SSE4 SIMD instruction set etc.
![]()
13. So after it finished the 1000 step retraining, we run the evaluation, to see how good it is at classifying those new flowers!
python eval_image_classifier.py \ --checkpoint_path=TRAINDIR \ --eval_dir=TRAINDIR \ --dataset_name=flowers \ --dataset_split_name=validation \ --dataset_dir=DATASET \ --model_name=inception_v3Here's what I got!So 0.77 accuracy. I'm not sure if that is good or bad!
14. Next is to retrain for 500 more steps. And then evaluate again.. But I didn't get that far..
python train_image_classifier.py \ --train_dir=TRAINDIR/all \ --dataset_name=flowers \ --dataset_split_name=train \ --dataset_dir=DATASET \ --model_name=inception_v3 \ --checkpoint_path=TRAINDIR \ --max_number_of_steps=500 \ --batch_size=32 \ --learning_rate=0.0001 \ --learning_rate_decay_type=fixed \ --save_interval_secs=60 \ --save_summaries_secs=60 \ --log_every_n_steps=10 \ --optimizer=rmsprop \ --weight_decay=0.00004Here is train_image_classifier.py https://github.com/tensorflow/models/blob/master/slim/train_image_classifier.py
Here is eval_image_classifier.py https://github.com/tensorflow/models/blob/master/slim/eval_image_classifier.py
The whole thing is in .sh here as I mentioned! https://github.com/tensorflow/models/blob/master/slim/scripts/finetune_inception_v3_on_flowers.sh
-
Plan for large-scale training run with object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
04/07/2017 at 19:30 • 0 commentsIn this large-scale training run I'll be using 5177 negative images, and 750 positive elephant-images. I'll attempt hard-negative mining on 500 images. Hard-negative mining is outlined in the following paper 'Object Detection with Discriminatively Trained Part Based Models' (Felzenszwalb et al.).
I'll be using the following EC2 instance: r4.16xlarge, with vCPU=64, ECU=195, and Memory GB=488. It's about $5/hr for rental. So hopefully I won't get broken pipe on the SSH session near the end!
Storage is 300GiB with provisioned IOPS SSD, 15000 IOPS. So that's extra cost I expect!
Negative images to use:
- chimps = 110
- bears = 102
- blimps = 86
- bonsai = 122
- bulldozers = 110
- cactus = 114
- camel = 110
- canoe = 104
- covered wagon = 97
- cormorant = 106
- dog = 103
- duck = 87
- elk = 101
- fern = 110
- firetruck = 118
- giraffe = 84
- goat = 112
- goose = 110
- gorilla = 212
- horse = 270
- ibis = 120
- kangaroo = 82
- leopards = 190
- llama = 119
- ostrich = 109
- owl = 120
- palm tree = 105
- people = 209
- porcupine = 101
- raccoon = 140
- skunk = 81
- snake = 112
- swan = 115
- touring bike = 110
- car side view = 116
- zebra = 96
- greyhound = 95
- toads = 108
- rhinos (own dataset) = 95
- [4591 total running]
- India cows (own dataset) = 41
- Sloth Bears (own dataset) = 45
- buffalo = 250
- tigers (2) = 250
-
Positive training images: bounding boxes or not?
04/06/2017 at 20:51 • 0 commentsNow, what I have been doing is putting bounding boxes around the elephants in my positive training images. Then, collecting the xy coords for these in files, which I passed to python, which would cut-out the regions of interest that contained elephants, before passing them to the HOG feature extractor. The problem is the bounding boxes contained other bits of non-elephant things in some cases. Well, they'd always contain grass, sky, rocks, branches, etc.
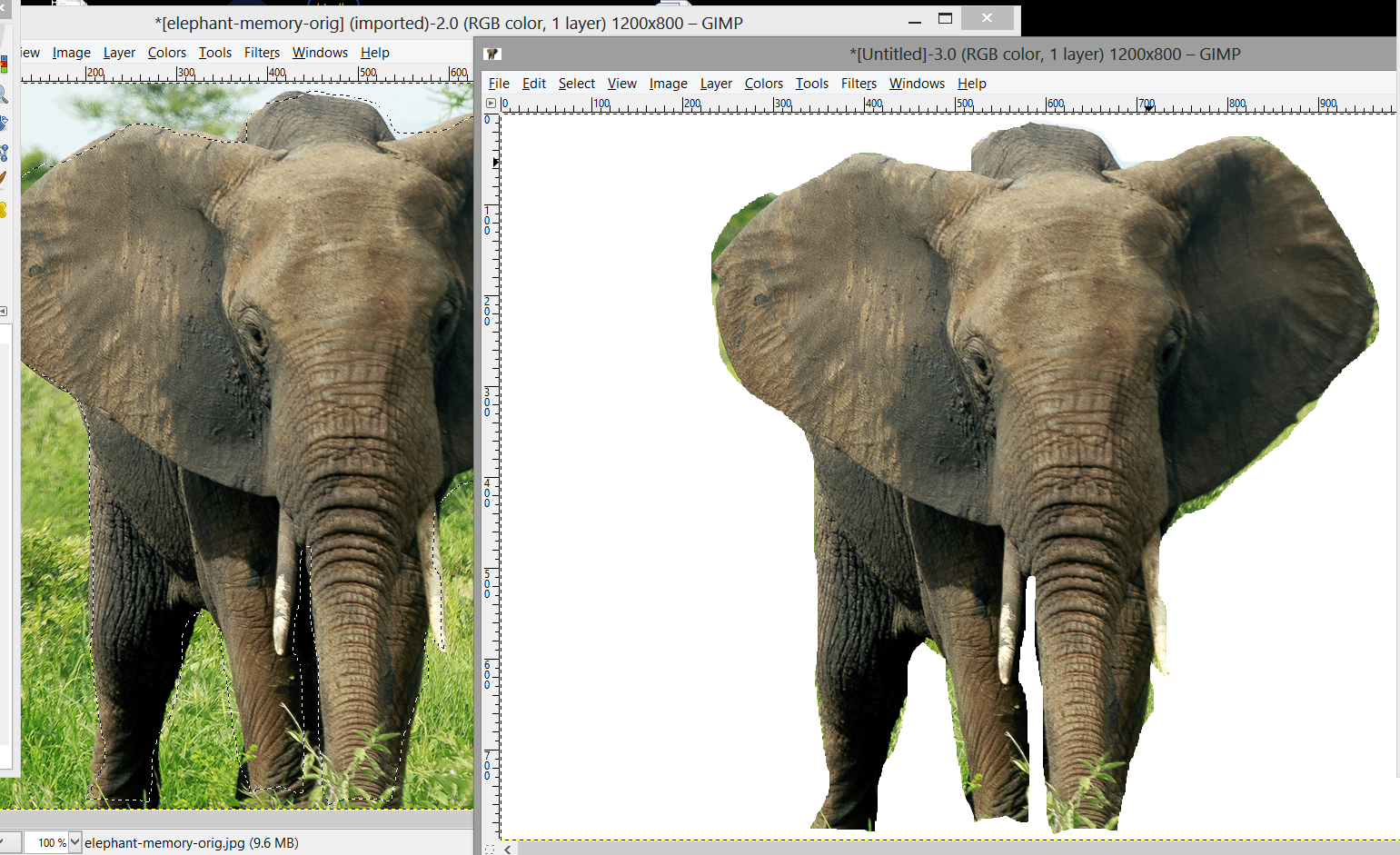
So, I thought, why not cut-out the elephants accurately myself. And just pass these straight to the HOG feature extractor? E.g. cut-out like this:
![]()
THAT WAS A DISASTER AND I WASTED 2.5HRS CUTTING OUT ELEPHANTS!!!
-
#3 result for object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
04/01/2017 at 19:32 • 0 commentsThis time I used 1000 negative training images from the caltech256 dataset. I only used parts of dataset containing animals (chimps, llamas, gorillas, kangaroos, horses, elks,..) and some landscapes (not urban) this time. These 1000 again being selected pseudo-randomly from the images I had on storage drive from the dataset. I again used only 64 positive images from the earlier caltech dataset. I used hard-negative mining on 50 images this time. That took around 40 minutes on the EC2 (virtual machine) m4.4xlarge instance I was using.
The workflow is:
- extract features from the positive and negative images (2 minutes)
- train object detector (45 minutes)
- hard-negative mining (40 minutes)
- re-train object detector with the hard-negatives (45 minutes)
N.B. If you are using EC2 like me, you can end up with broken pipe in SSH session if the client sleeps during long training sessions :-(
So how would it get on with cows and rhinos this time!? It even detected farmers once last time!
Much more promising results!
NO RHINOS DETECTED! *well in this image anyway!![]()
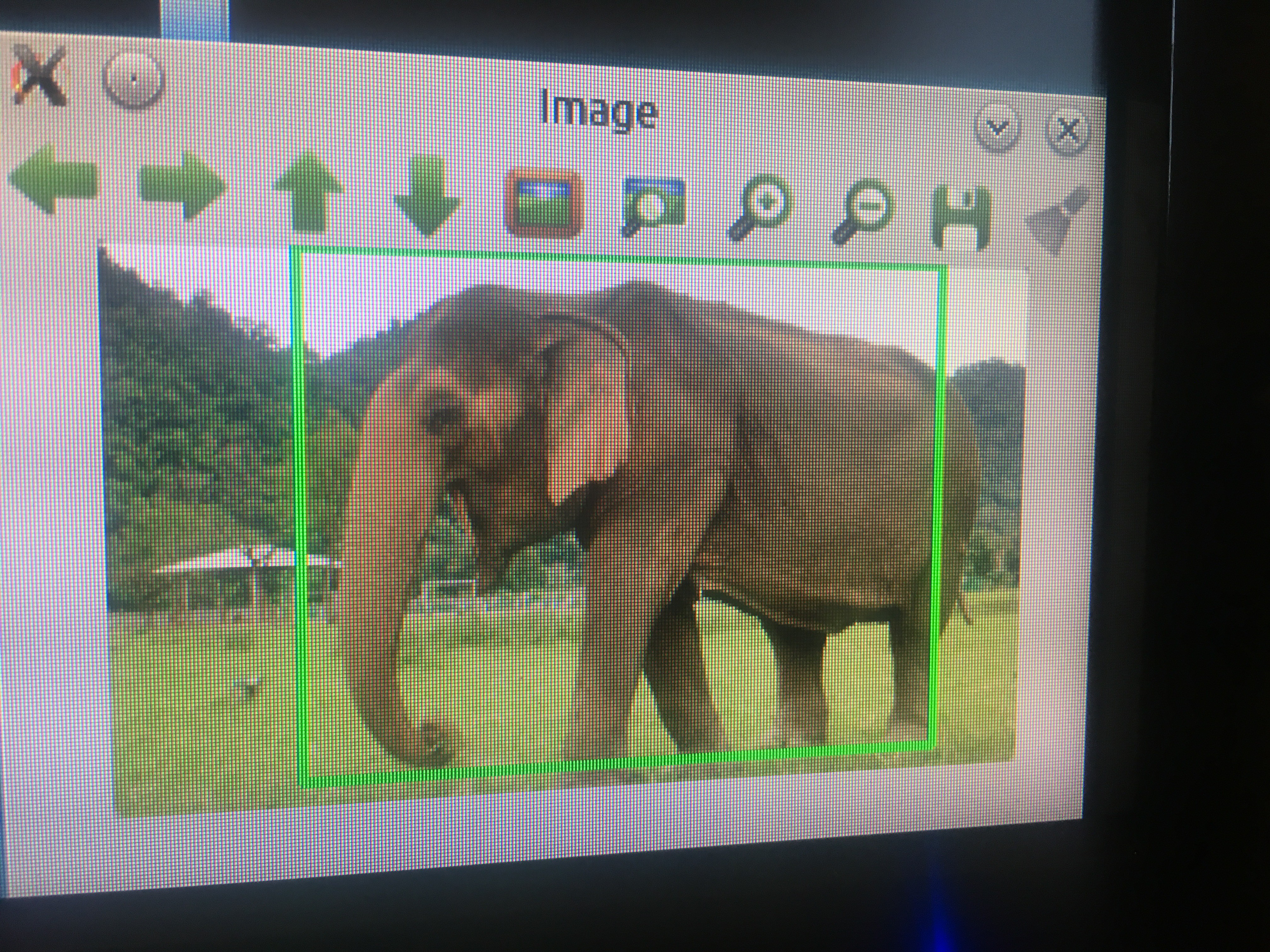
Elephants still detected!![]()
![]()
Farmers in fields not detected!
No cows detected in the several images I tested!![]()
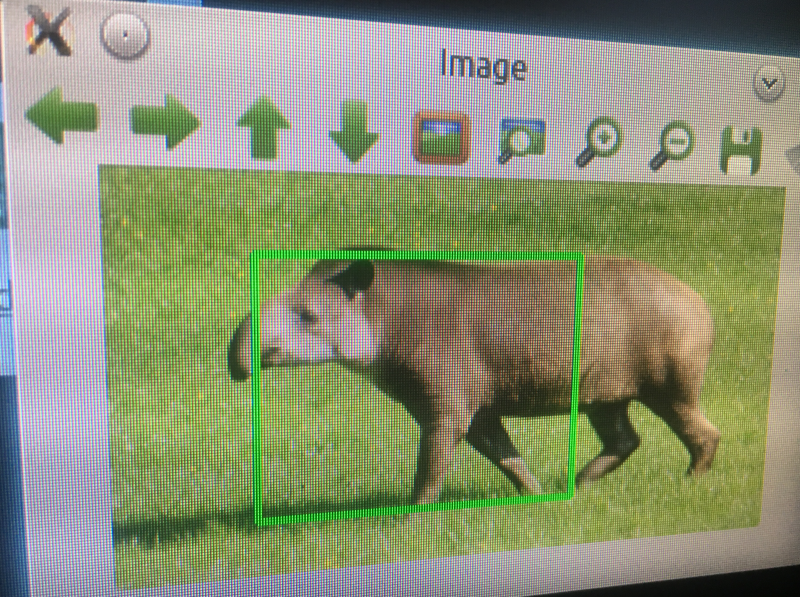
Tapir was unfortunately detected! It does look kind of similar to a baby elephant! Hard one!![]()
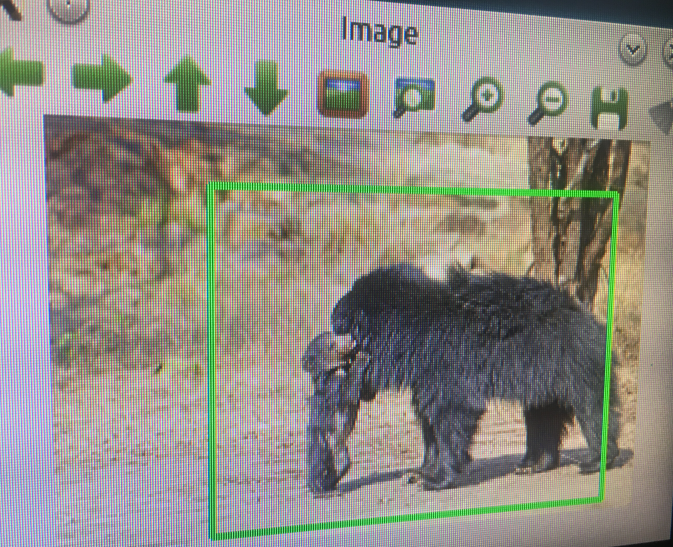
Sloth bear was detected! Not as elephant-like as the tapir!![]()
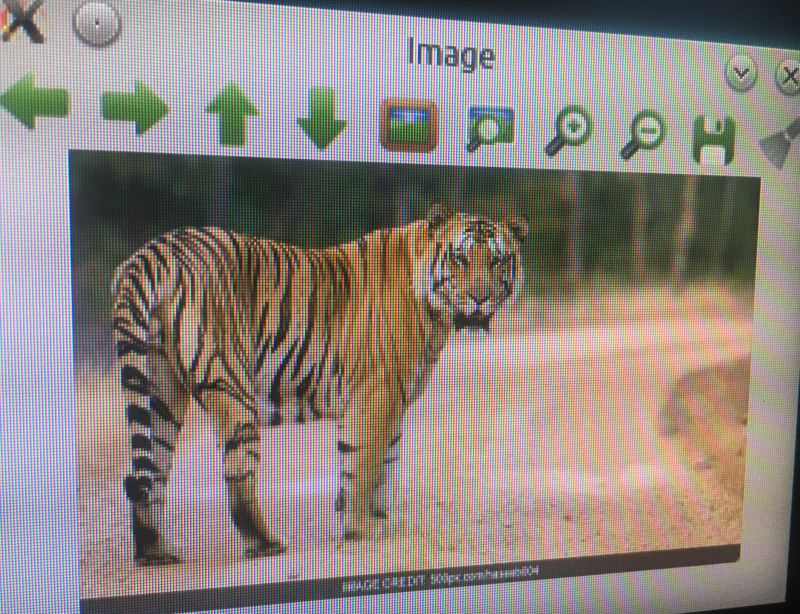
Tiger not detected. Yay!![]()
I didn't undertake any stringent testing protocol to gather a percentage of false-positives and false-negatives at this early stage.
The different approach this time was to include primarily animal-based negative training images, increase the negative images used from 700 to 1000, and perform hard-negative mining on 50 vs. 10 images.
-
Instructions for using EC2 instance to train object detector [in progress]
03/31/2017 at 19:58 • 3 commentsTo speed things up, I'm making using of the Amazon Elastic Compute Cloud (EC2) virtual machines to train my object detector using HOG and SVMs. Here is the protocol for setting up the virtual machine; in this case I'm using an M4 instance, which has either 2.3 GHz Intel Xeon® E5-2686 v4 (Broadwell) processors or 2.4 GHz Intel Xeon® E5-2676 v3 (Haswell) processors. And in the case of m4.4xlarge it has 16 vCPUs and 64 GiB of memory. This one costs $0.998 per hour to rent.
1. Choose AMI (machine image: I'm using Ubuntu), choose instance, setup security, setup storage
2. Launch instance
3. Download the keypair for this instance (keypair.pem)
4. Open SSH client on your machine
5. Set permissions for your keypair: chmod 400 /path/keypair.pem so it is not really loose else it will be rejected
6. Use SSH client to connect to the instance:
ssh -i /path/keypair.pem ubuntu@ec2-xxx-xx-xxx-1.compute-1.amazonaws.com7. You can move files between your machine and the instance using scpscp -i keypair.pem myfiletotransfer.tar.gz ubuntu@ec2-xxx-xx-xxx-1.compute-1.amazonaws.com:** don't forget to terminate your instance in the EC2 dashboard when you have finished. I forgot once it was left running for 720hrs! Luckily it was free tier, else I would have been in big trouble financially!
8. Update apt-get (for Ubuntu)
9. sudo apt-get install build-essential cmake pkg-config
10. sudo apt-get install libgtk2.0-dev
11. sudo apt-get install libatlas-base-dev gfortran
12. sudo apt-get install libboost-all-dev
13. For PIP, wget https://bootstrap.pypa.io/get-pip.py and sudo python<version> get-pip.py
** you can set up virtualenv and the wrapper if you want
14. sudo apt-get install python<version here>-dev
Install all the libraries for python now:
15. sudo pip install numpy
16. sudo pip install scipy matplotlib
17. sudo pip install scikit-learn
18. sudo pip install -U scikit-image
19. sudo pip install mahotas imutils Pillow commentjson (for the .json config files if wanted)
For OpenCV:
20.
wget -O opencv-2.4.10.zip http://sourceforge.net/projects/opencvlibrary/files/opencv-unix/2.4.10/opencv-2.4.10.zip/download unzip opencv-2.4.10.zip cd opencv-2.4.1021.
mkdir build cd build cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D BUILD_NEW_PYTHON_SUPPORT=ON -D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON -D BUILD_EXAMPLES=ON ..22. Compile it with make -j<number of cores>
23.
sudo make install sudo ldconfig24. sudo pip install random
25. sudo pip install progressbar
26. I think that's everything! It takes about 1hr :-(
Another instance I am using is the EC2 new deep-learning AMI (image) which has TensorFlow prebuilt and other useful stuff like Python3 and CUDA pre-installed https://aws.amazon.com/marketplace/pp/B01M0AXXQB#product-description
If you ran this on the new p2.16xlarge instance, you'd have 8x NVIDIA Tesla K80 Accelerators, each running a pair of NVIDIA GK210 GPUs https://aws.amazon.com/blogs/aws/new-p2-instance-type-for-amazon-ec2-up-to-16-gpus/ which would be great for training inception vx architecture in TensorFlow even from scratch! e.g. https://github.com/tensorflow/models/blob/master/inception/inception/inception_train.py
It's about $14.40 per hour to rent that instance however! So it would still be quite costly to train inception from scratch!
-
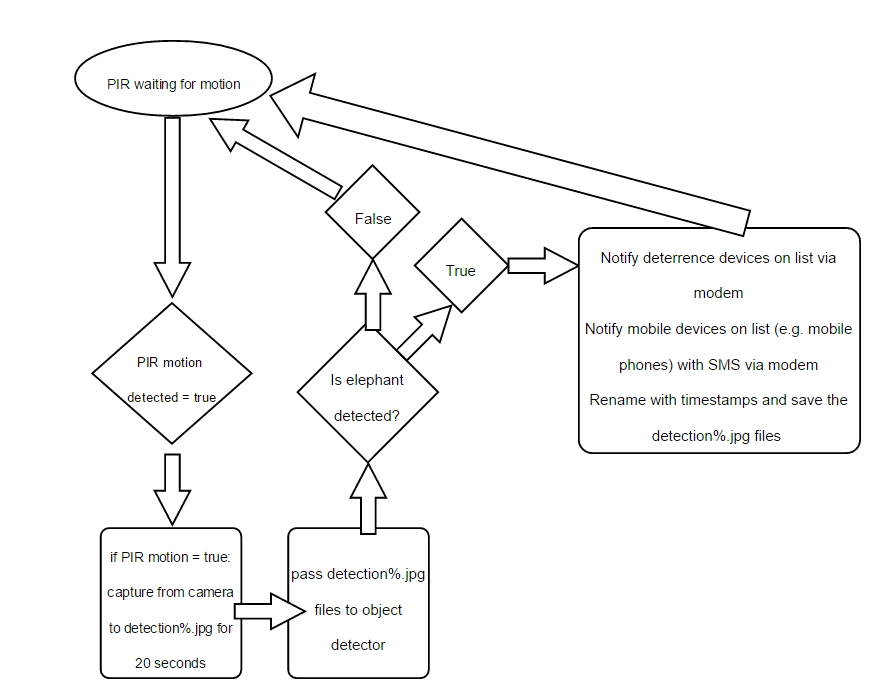
Rough outline of software flow
03/26/2017 at 21:11 • 0 commentsOutline of software flow:
![]()
We will capture from camera for 20s after PIR motion was true (at one image per second). Then stop capture, and pass the detection images to the object detector. It's not going to be very fast for the object detector to decide! It could easily take 30s to decide to each image, that means 20 images * 30s which equals 600s! Yeah, that's 10 mins - so this is something I'm a bit worried about. Actually, an i5 6xx w 2 cores took around 10s to decide..
-
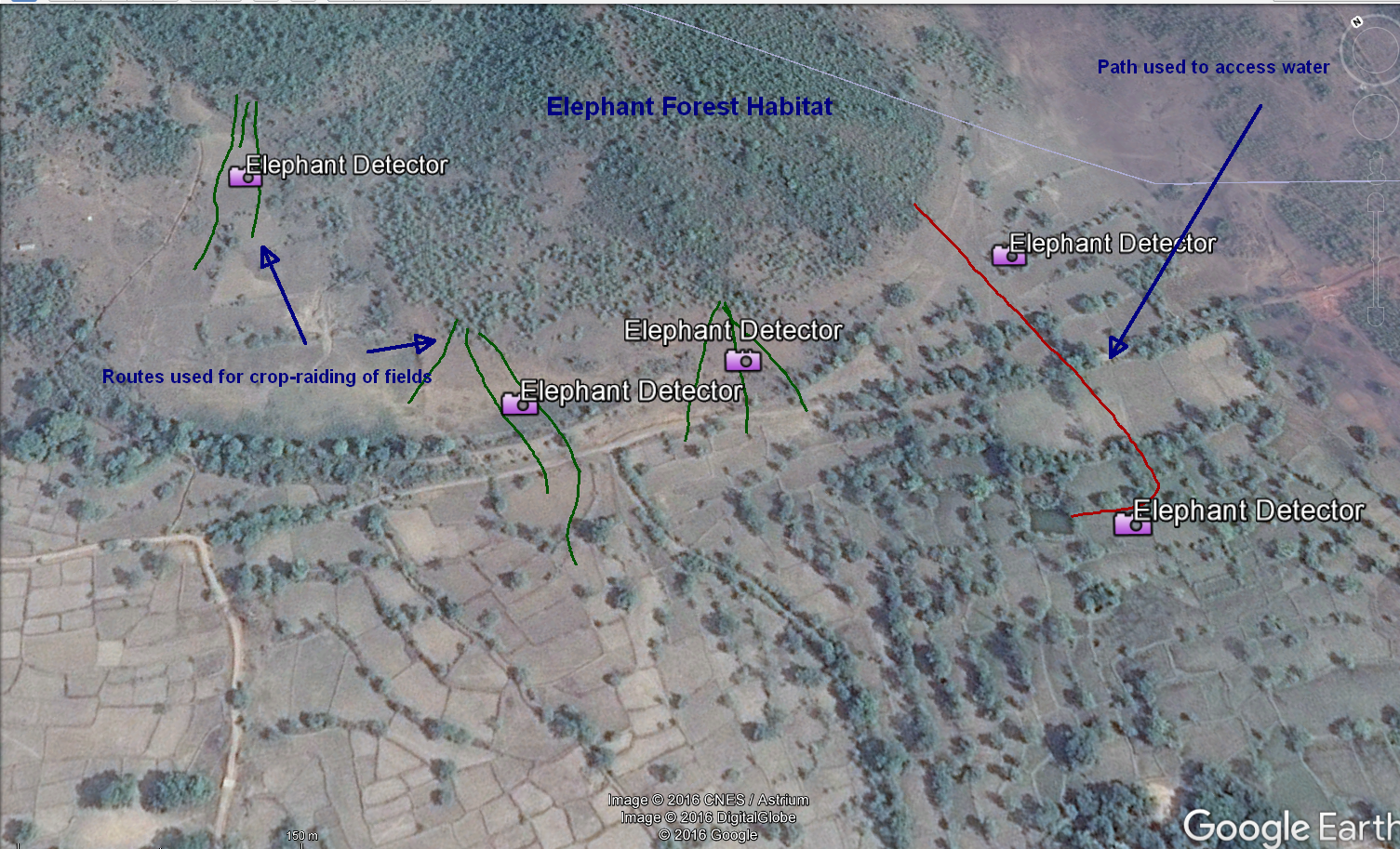
Placement of elephant-detection devices
03/25/2017 at 20:41 • 0 commentsHere we have an example placement of elephant-detection devices. This would be case-by-case, based on the routes (as shown in green) that local people suspect the elephants are using to launch their crop-eating raids! The devices can be moved as the elephants change their tactics. The devices would also be placed along the established elephant paths (e.g. to watering holes, as shown in red).
The purpose of detecting elephants along their established paths is to warn local people of their presence, so humans can avoid the area when elephants are moving!
![]()
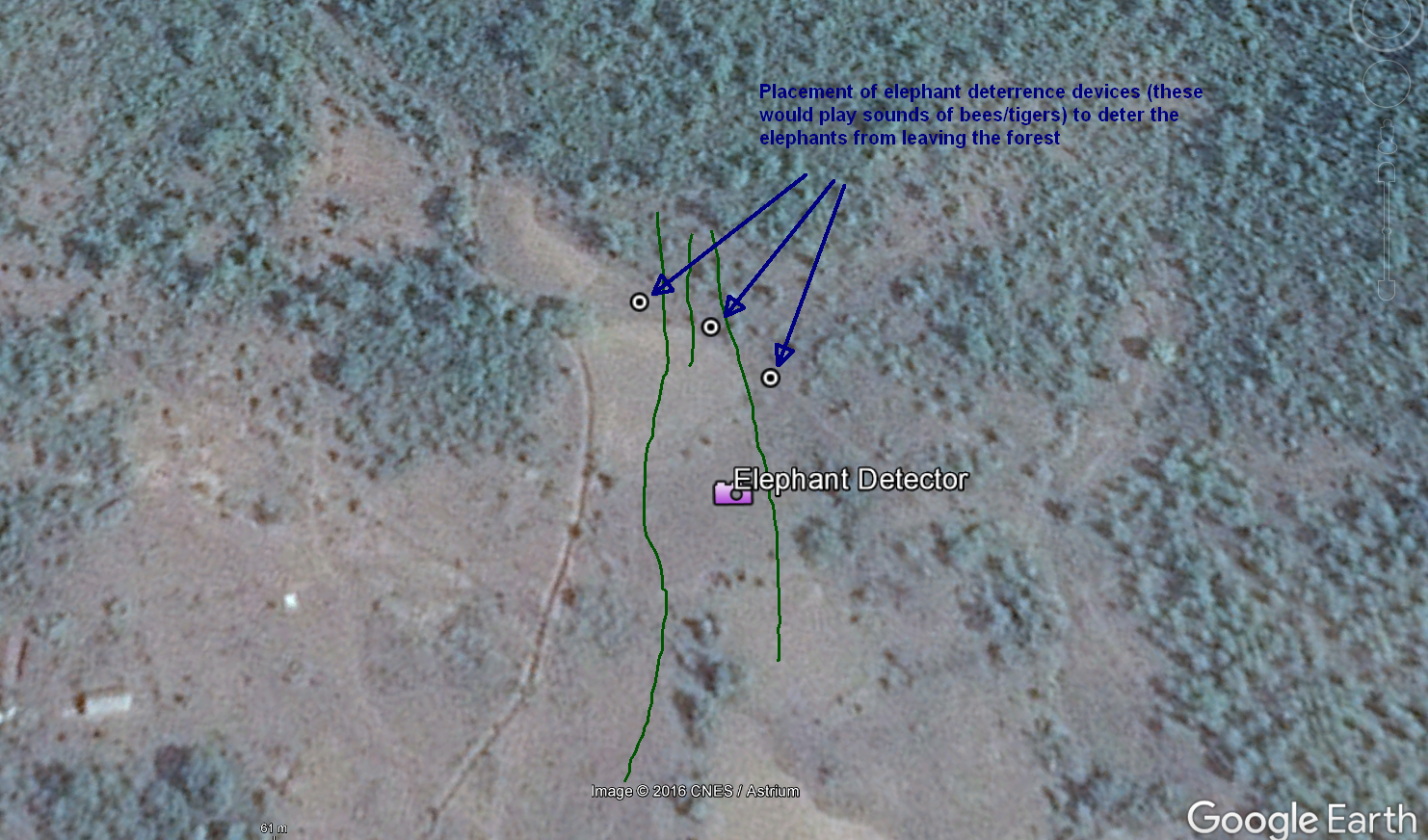
Here we have an example of placement of the elephant deterrence devices: these play the sounds of bees or tigers in order to scare the elephants before they cross the interface between forest and farmland. These deterrence devices are triggered by a positive sighting of an elephant by a detection device.
![]()
Prior to installation of the elephant detection devices, and deterrence devices, we could conduct a surveillance survey (e.g. 10 days), using aerostats with Ultra HD video, in order to acquire accurate data regarding elephant movement.
-
Second results with object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
03/24/2017 at 21:42 • 4 commentsThis time I used 700 negative images from the CalTech256 dataset, which included images of animals (chimps, llamas, gorillas, kangaroos, horses, elks, etc.), in addition to the mostly landscapes and urban scenes I'd used from the CalTech101 dataset last time. I actually had around 5300 images in this dataset, so these 700 were selected pseudo-randomly from the set. In addition, I did hard-negative mining. But it kept crashing the machine I was using in OracleVM, so I only did it for 5 images!
Next I trained the object detector using the 700 negative images, the positive elephant images (from the CalTech 101 dataset), and the hard-negative images. Would the false-positive rate improve? Would we still detect cows and rhinos?!
Unfortunately yes, it detected the rhino again!
![]()
And even worse, it detected an elk! The elks were part of the negative training set. Although we don't know if they were used, since we selected 700 negative-training images randomly from a dataset of ~5300.
![]()
At least it didn't detect a tractor!
![]()
And it was still detecting elephants, no false-negatives!
![]()
It really wasn't so bad considering that I only used 700 negative training images, and hard-negative mining on just 5 images!!! The entire training from feature-extraction, thru hard-negative mining, to training the object detector, took around 1hr. It is going to take much longer than that to train an efficacious object detector using HOG and SVM!
-
First results with object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
03/23/2017 at 20:28 • 0 commentsSo I trained this one using 500 negative images from the Caltech 101 dataset . That is, specifically from the sceneclass13 section. And with 64 positive elephant images from the same dataset.
![]()
Now the sceneclass13 section contains images mostly not containing animals! Not the best choice as we will see!
![]()
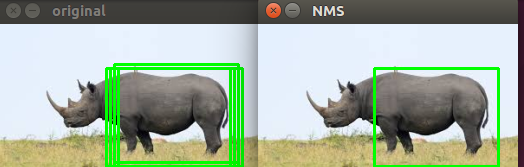
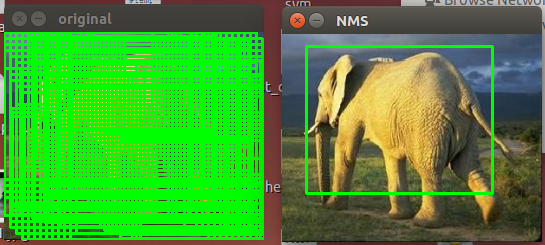
In this first test image you can see lots of overlapping bounding boxes on the left! This was prior to applying non-maxima suppression. The same test image on the right, after applying non-maxima suppression, has just one bounding box on the elephant:
It was pretty good at detecting elephants in random photos I downloaded!![]()
![]()
Unfortunately it also detected rhinos!
Hey, well rhinos are similar looking to elephants [a bit]! But then it also detected cows too! :-(![]()
On the bright side, it didn't think cars were elephants!![]()
So in this first attempt, I made the mistake of using negative images that didn't contain objects similar to elephants i.e. animals! N.B. There was no hard negative mining done, although I doubt it would make much difference considering the negative images mostly contained no animals!![]()
The next attempt I made was using the Caltech 256 dataset!
I'll add the python code and dependencies here later..
-
Thread on WILDLABS about the project
03/20/2017 at 23:20 • 0 commentsI got some interesting ideas here, especially as regards security!
Elephant AI
a system to prevent human-elephant conflict by detecting elephants using machine vision, and warning humans and/or repelling elephants











{kind=link}