0%
0%
Hoopi Pedal
2-channel pedal with SD recording. Capture guitar + mic with effects and auto-sync to video—no DAW or laptop required.
 Prince
PrinceBecome a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests
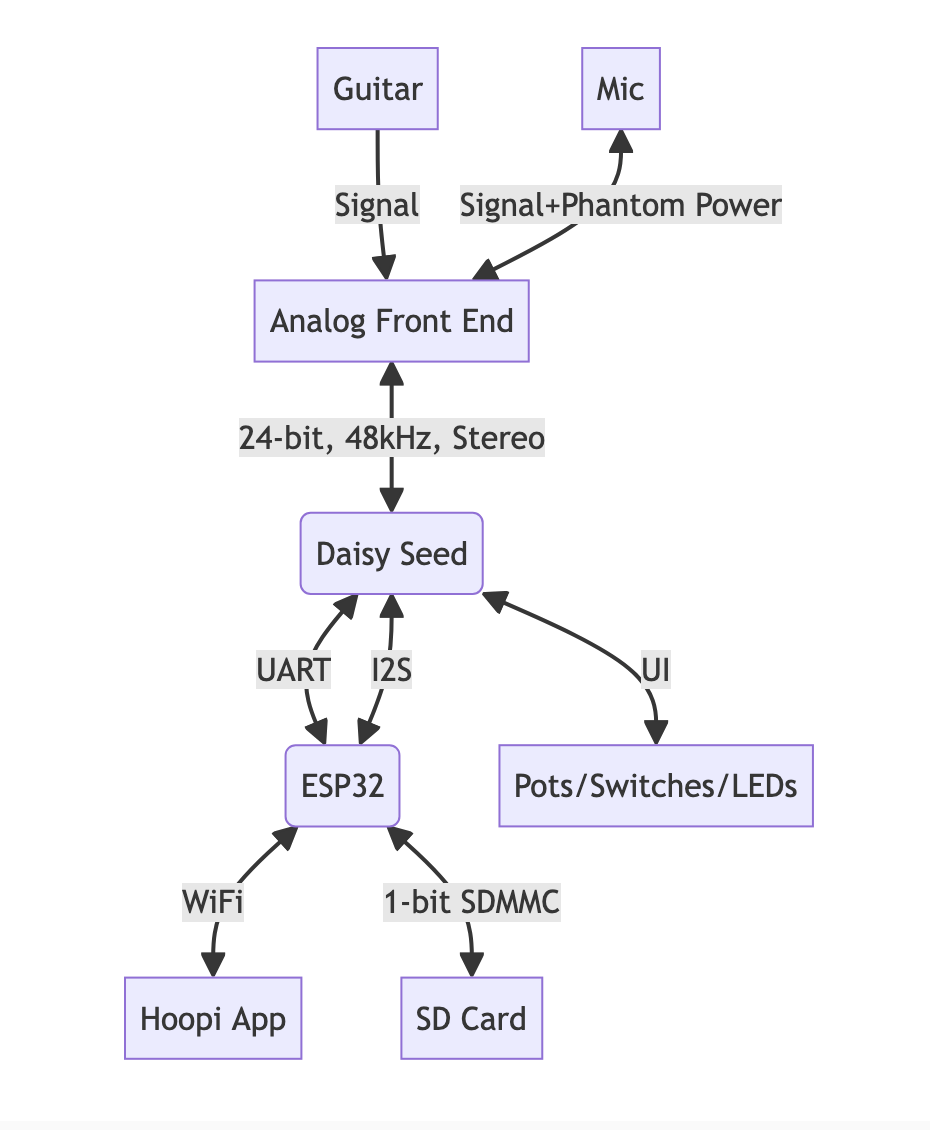 We have the ability to update the audio effects by changing the Daisy's firmware, using over-the-air (OTA) updates.
We have the ability to update the audio effects by changing the Daisy's firmware, using over-the-air (OTA) updates.