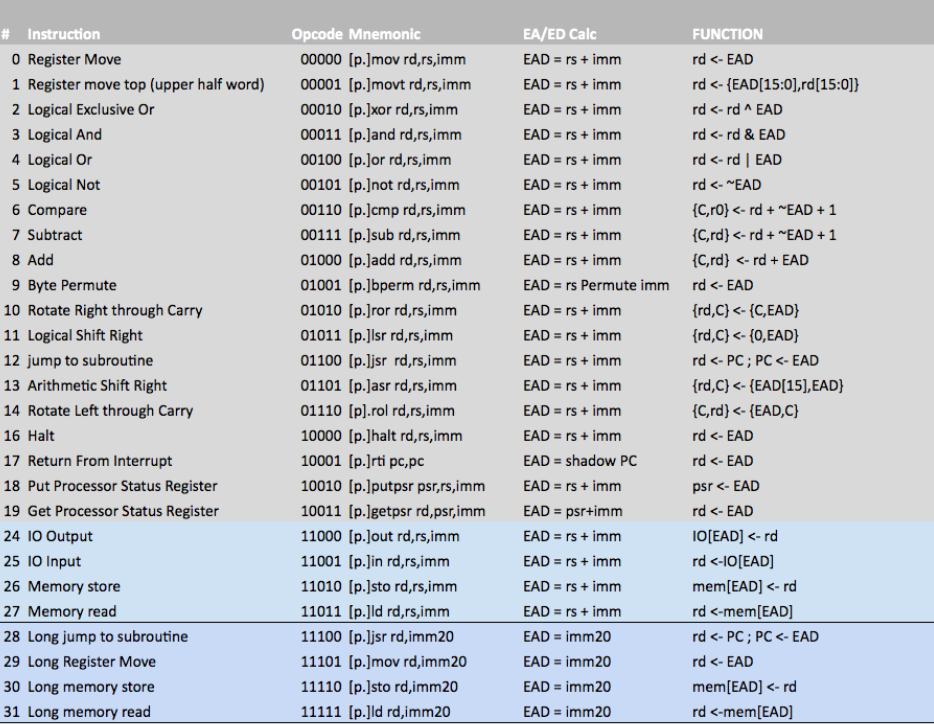
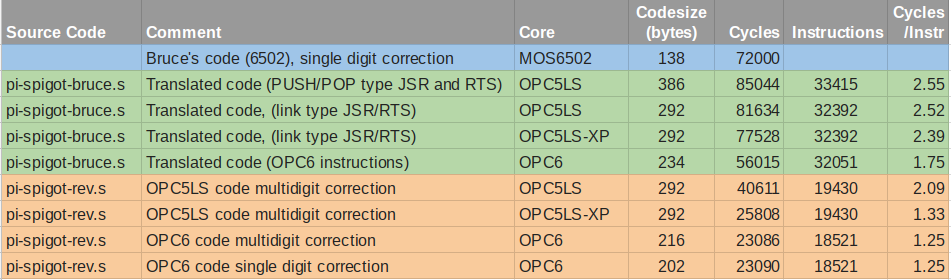
 Ed S
Ed SWhat kind of CPU can you describe in one page of code? Will it be usable? (You bet! In fact we've found it to be a pleasure to program.)
Having previously built a short series of one-page 8 bit CPUs for CPLD, we wanted more space, and decided to target FPGA. Not only did we still want to keep each source file to within a 66 line page - and not too obfuscated - but also we wanted to meet the challenge of fitting within 128 slices of a Spartan 6.
That constraint comes from Arlet's challenge - what kind of micro can you make, about as big as a 6502? (Arlet's 6502 core is about 120 slices, so he set a limit of 128 slices as a nice round number.) We want to meet his challenge, but might need more than a page to make a usable machine with two sources of interrupts, a RDY input to deal with slow memory, and to interface to an 8 bit bus. Especially as we'd decided to make a 16 bit, word-addressed machine. This is a step on the way.



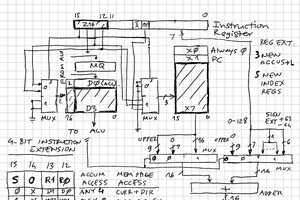
 zpekic
zpekic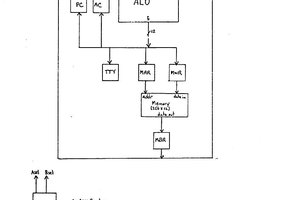

 Bohan Xu
Bohan Xu