ErwinM
ErwinM-
DME does paging
04/29/2019 at 14:34 • 2 commentsThe theory
Any modern CPU implements paging (the now defunct alternative being 'segmentation') and DME does so as well. In modern CPUs paging is used to give every process its own, clean, address space: a 32-bit CPU can address 4 GB of memory and with paging enabled, each process can address and access all of it (in practice the OS will limit each process size). For DME, paging provides another functionality: DME has 512kb of physical memory. However, being a 16bit architecture, DME can only address 64kb. Paging allows DME to use all of its 512kb of physical memory, while only being able to address 64kb of it simultanously. This way DME can keep multiple address spaces in memory and swap to the right address space just before it starts or resumes a process.
Having explained the theory: paging is complex! Not so much the high level concept, or even the implementation, but just thinking about it is complex: what is suppose to happen?, what is actually happening?, does it work? For this reason, adding paging to DME was 80% translating the high level concept into a detailed concept - all with pen and paper. Once I had that figured out, the other 20%, the implementation in Verilog, took just a few lines of code.
DME's paging concept
To make paging a reality we need to implement the following:
1. when turned on, logical addresses are translated to physical addresses
2. this translation is dynamic: the (OS) programmer can manipulate how addresses are translated
3. the implementation should recognize the concept of an address space: a bunch of translations that belong together
4. paging functionality can be turned on and off (otherwise you go mad trying to program it)Conceptually, my implementation divides 512kb of physcial memory into 256 pages of 2kb each. Furthermore, it also divides 512kb into 8 address spaces of 64kb each (= 32 pages). This last point is a major simplification which I will discuss under point 3.

1. Translate logical addresses to physical addresses
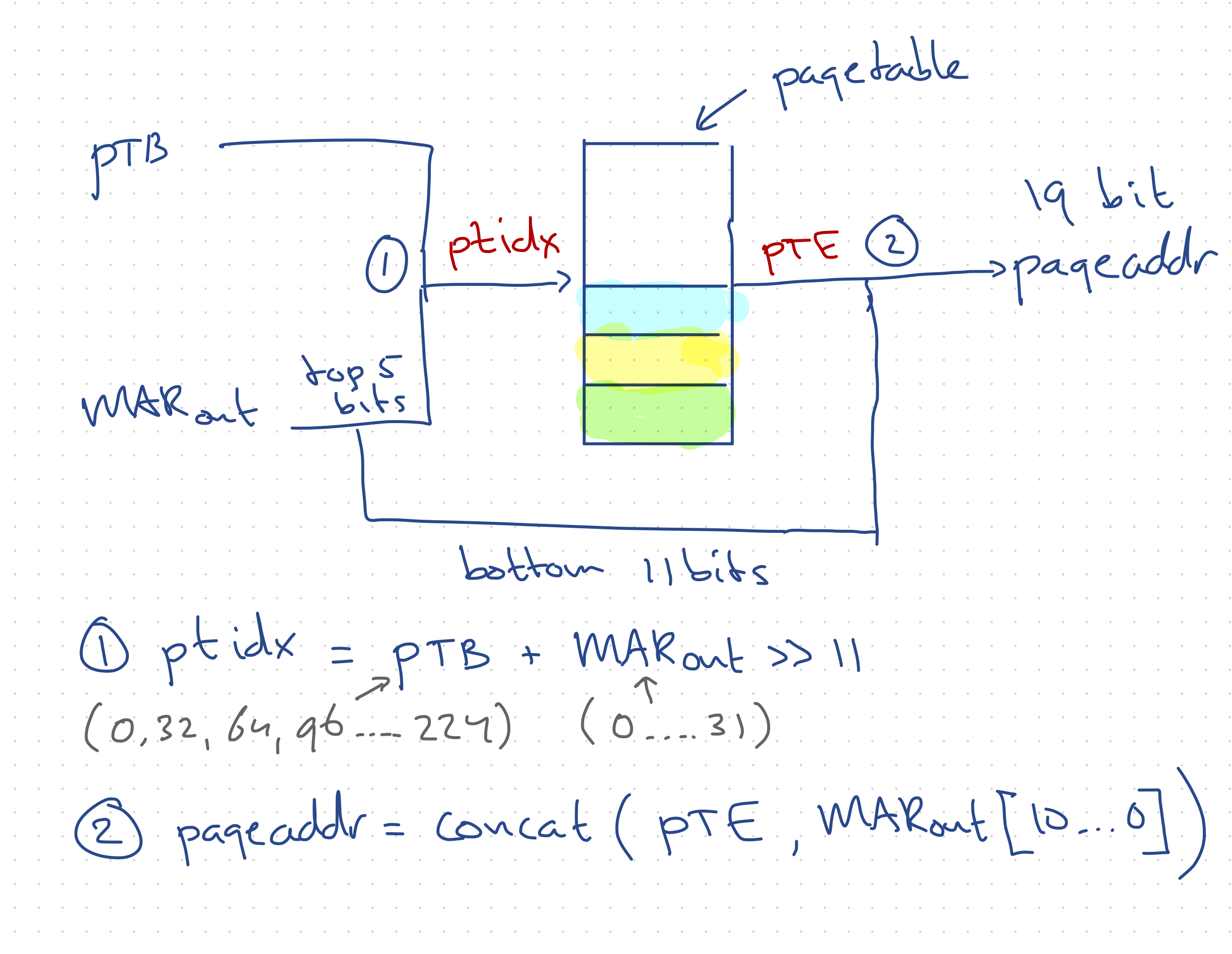
The paging logic should take a 16-bit logical address and translate this in a 19-bit physical address (512kb = 2^19). It consists of:Page Table: actually not a table, but just a list consisting of 256 16-bit addresses, that hold a reference to physical page locations, so called Page Table Entries (PTE). To translate a logical address an index is calculated and this is used as an index into the Page Table (e.g. if ptidx equals 47 the 47th entry of the Page Table is used).
Page Table Base (PTB): used to determine which of the 8 available address spaces is visible to the CPU. The PTB functions as an offset to the base of an address space in the Page Table. For example, the second address space would be indicated by a PTB value of 32, meaning the first page of the second address space is page 32 in the Page Table.
Page Table Index (ptidx): used to determine which PTE should be used from the Page Table. In pseudo code it is calculated as: address space offset + page number. The address space offset is simply the value of PTB. The page number can be gotten from the logical address (held in MAR): the bottom 11 bits give the location within a page (2^11 = 2048), the highest 5 bits when shifted right 11 places give a number between 0 and 31 - the page number.
The physical address (pageaddr) is then concatenated from PTE (highest 8 bytes) and the MAR (lowest 11 bytes) resulting in a 19-bit address.
2. User editable Page Table
Page Table Entries (PTEs) can be loaded into the Page Table by the command WPTE (Write PTE). It takes 2 arguments: the ptidx of the entry (0..255) and the physical page it should be mapped to shifted left 8 bit. In hindsight I could have shifted during the concatination of pageaddr, this would make the PTE entries easier to interpret. Perhaps I'll change it.3. Recognize address spaces
The PTB register can be loaded with the WPTB (Write PTB) command. The implementation of the translation above guarantees that any mapping falls within the current address space: the top 5 bits from MAR can create no greater offset than 31. Offset 31 refers to the 32nd page, 32 x 2048 = 64kb. This behaviour results from my choice to divide the 512kb into 8 address spaces. This means that the value of PTB will always be a multiple of 32 between 0 and 224. The cost of this choice is that there can only ever be 8 processes running simultanously (7 user, 1 OS). Even if each process only requires 1kb of memory, 8 is the maximum number of processes as each process gets a full address space assigned in the PTB. Implementing dynamic address space sizes is a lot more complex due to the need to check if a logic address does not go out of bounds and the fact that address spaces sometimes need to increase in size. The first could probably be implemented in hardware with a second register (Page Table Top). The second point is harder. In any case, I went with the simplest implementation possible: 8 addresses spaces max.4. Turn on/of
Turning paging on and off is as easy as checking bit 3 in the control register (CR[2]): if its set the pageaddr is used as the address going to ram (RAMaddr) if not, MARout is directly used. THus, when paging is off only the first 64kb of physical memory can be addressed.The actual implementation in Verilog of the above is very simple. As I said, the hard part is deciding upon the conventions that make up your paging implementation. The translation part is realized in 3 lines of code. The loading of the page table and setting of PTB add another 8, very simple, lines.
This is all there is to the hardware implementation of Paging. The complexity does not end here though, dealing with paging is equally complex (to me at least) in software and deserves its own post.
If people are interested I'll write that up next.
-
This is DME CPU's ISA
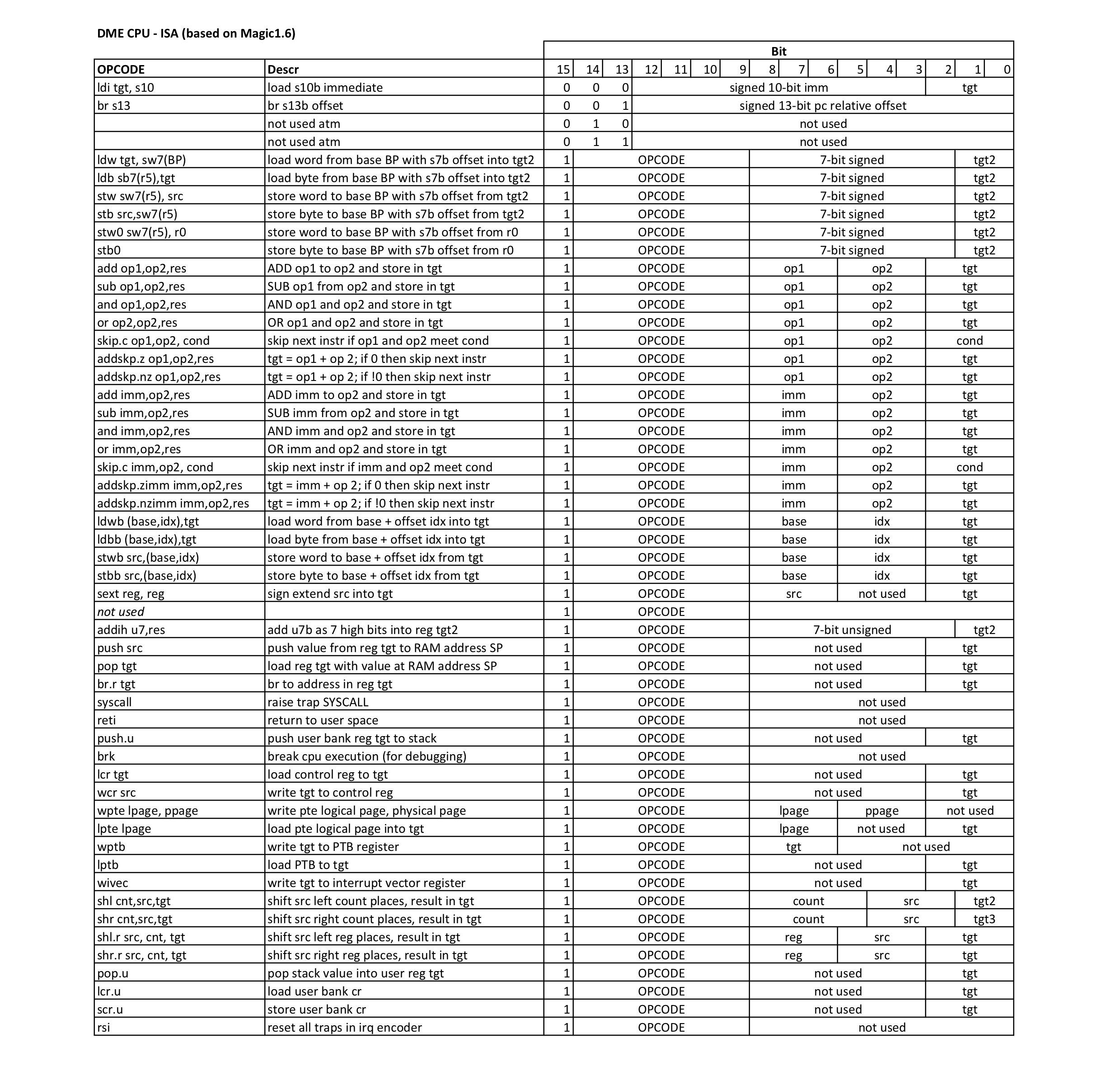
10/03/2017 at 19:38 • 0 commentsThis is DME's ISA:
It's heavily inspired (copied?) from Bill Buzbee who designed an ISA for his planned Magic1.6 project. When I started my project I had no idea what to look for in an ISA, so I took his concept as a starting point. I took the load/store and the arithmetic instructions pretty much as I understood them. The 'architecture specific'-instructions (dealing with page tables and interrupts) I added myself. I also deviated from the pure RISC pattern by adding PUSH and POP instructions. As I was doing a design with a stack, these were just too good not to have and not too hard to implement.
When I started my decoder in Verilog the plan was to not use microcode. At the time, I only had about half the instructions finalized and was implementing them in the decoder with 'case' and 'if-then' clauses in Verilog. Two reasons made me switch to using a microcode approach:
1. It was too 'programmy' for my liking
I started this project because I was intrigued by how simple logic blocks turn into a full blown CPU. For this reason I have tried to keep my Verilog as simple as possible. Going for a "I should be able to implement it in hardware"-feeling. The complex decoding logic I was typing into Verilog felt too much like programming and not like I was designing anything to do with hardware. If I'd have to do this in hardware I would have to move to a microcode approach.
2. Microcode is a lot easier to change
In the early days of my CPU my ISA changed a lot. As I wrote the assembler and later the compiler I constantly ran into instructions that couldn't target a certain register or instructions I thought would be handy, but which the compiler in practice would never use. Being able to change the microcode just be editing a text file has been such a good solution to deal with all these changes.
So I ended up with a microcoded decoder. The decoder uses the OPCODE number as an index into a table of 48bit microcode. The bits in the microcode drive the control lines in the CPU. The microword looks like this:
It uses 46 out of 48 bits. I could get that down by quite some bits if required as a lot of duplication has crept in over the time. But there is no real need to do so: the FPGA has plenty of room and it's not really interesting to me at this time.
Looking at the ISA today I could see how, with some sorting and clever grouping it could probably be realised in a less complex set of Verilog statements without needing any microcode. Still, I think the microcode-approach has worked out well. It was something I could definitely see myself implementing in hardware, it is a breeze to change and, this being an FPGA, I have a suspicion that at the LUT level both approaches come down to pretty much the same thing.
-
DME is flawed
09/24/2017 at 13:53 • 0 commentsThe trap logic
When I started DME, I decided I'd do a RISC kind of architecture (actually Bill Buzbee decided it for me, as I took his Magic1.6 ISA as a starting point). So for the trap mechanism, I opted for a RISC like approach as well. DME has two sets of registers: USER and IRQ. User programs run in the user registers until a trap happens, the cpu then immediately switches register banks and continuous operating using the IRQ registers. The upside of this, is that during most traps the OS does not need to spend time saving user registers as they are preserved and can just be switched back to once the OS returns to user space.
The flaw
DME does not service IRQs when it is in its IRQ mode. Initially, I thought that would be no problem: it would finish servicing the current IRQ and then after it returned to user space it would immediately trap again and service the missed IRQ (it does get saved). This thinking is still mostly valid except for: syscalls. As I started fleshing out the OS it occurred to me that often a sycall, for example 'read', would trigger DME into IRQ mode only to kick-off some operation, f.e. read from the SD Card, and then go to sleep (in IRQ-mode!) waiting for the operation to finish. This 'finish' is signaled by an IRQ! Now, if every process is in IRQ mode waiting for an IRQ, the system will deadlock as the IRQ will never get serviced.
Possible workarounds
1. Don't sleep waiting for IRQ, wait(poll) for finish
I could simply make a process wait for whatever operation needs to happen (keyboard input, reading a disk block) instead of putting it to sleep. In practice, since DME will never have multiple users working on it at the same time, the user experience of both approaches would probably be much the same. However, it means I don't get to play with IRQs as much in my OS. Just as important, this does not work for the timer IRQ.2. I could tell my scheduler that 'if there aren't any processes to run' (all are sleeping), it should run each irq handler. This works, and is actually what my OS does now (simple to implement). However, again this does not work for the timer_irq: i cannot run that each time there is nothing to run (it would accomplish nothing, as there is nothing to run!). It means timer_irq is only triggered when a process returns to user space.
3. I could have a special user space process that always operates in user space and never does a syscall and thus is always runnable to catch irqs. Although this works, its an expensive solution. The process would eat CPU slices just to catch irqs. No good.
A better design
The real solution is of course to add another bank of registers: user -> system -> irq. User would always trap to system. When operating in system we could then still catch (real, hardware) irqs which would push us into irq mode. Only when in irq mode are all irqs disabled.
DME is defined in verilog and the addition of a third register bank would not be too complex I think (ha!). However, I've decided against tackling that task atm as I want to keep the momentum going. I may decide to do it later, but lets first see how big of a problem this turns out to be. Meanwhile, i'm going with workaround (2).
-
Dhrystone scores are in!
09/24/2017 at 13:38 • 1 commentYesterday and today I have been trying to get the Dhrystone benchmark program running on DME. It has turned out to be a typical homebrew cpu/os experience that makes this project so interesting to me.
After I downloaded the c code i tried to compile it. I got an error about missing malloc (which I have not implemented), but after replacing these with two static defines the code compiled, assembled and linked without errors. I tried to run it directly (without the OS): no go, the program gets stuck. Since I am running it without the OS i cannot write to the screen so I decide that debugging this way is a no go.
Next, I try to run it through my (work in progress) OS. It loads the code, runs it and....gets stuck (even at this point in the project, my first reaction is still 'yeah, well can't expect random c code to work like that). After some googling I tracked down a newer version of Dhrystone (version 2.1, was working with 1.1 before). This version is much nicer for two reasons: it has more verbose output telling the user what SHOULD be happening. And secondly, it's source is annotated to explain even more.
I add some debugging printf statements and run the code again. It is only then I noticed that *nothing* is actually getting printed to the terminal (this is not always immediatley obvious as my OS is still very noisy with lots of debugging info being printed). I poke at the problem a bit but soon give up and call it a day.
When I got back today I decided there should be no reason printf should not be working, it has been working for the last few weeks. I put in a halt() just after the first printf, run it and...nothing. The Dhrystone code looks like an ancient dialect of c to me and has fairly long and complex strings in the printf statements. I decide to comment out most of them. Run the code and now the single printf statement is being printed to the screen. Aha! so now I only need to find the offending string and then figure out how to fix it! As I am commenting in 5 or so statements at a time and testing the code, another realisation dawns on me: each added statement makes the code longer, is all the code getting loaded in by the os? A quick look with the simulator reveals that the answer is no it's not. The last part of the program (where the strings are), does not get loaded.
My OS uses a unix-like inode scheme for a FS (based of xv6) and it uses direct blocks and indirect blocks to load files. Indirect blocks are used for larger files. Turns out the Dhrystone program is the first program that utilised my indirect block code and it didn't work. After some probing at the code, I realised a 'greater than' should be replaced with a 'greater than or equal'. Solved! the Dhrystone program is now being loaded in its entirety and each printf statement is working as it should!
Except that the program still gets stuck. Lucky for me, it gets stuck in a VERY basic routine (Proc_5), which only assigns a character to a pre-declared memory location. And this is not working. I isolate the code and sure enough it does not work: it seems as my asm/linker is not correctly assigning the addresses for the pre-defined char location. So I dive back into the assembler. Now, this thing has been working for the last couple of months, so that code is only a little familiar to me. I put in some breakpoints (yay for debugging scripting languages) and find out that no memory is being reserved at all for statements with a size of 1 byte! The assembler essentially skips them. Few lines of code later and the assembler now handles odd byte sizes (any odd number of bytes would have tanked) correctly in its bss section.
I recompile Dhrystone and presto, it no longer gets stuck. Operation succes. Dhrystone 1.1 runs fine as well with the assembler fix. So in trying to get a piece of c code to run, I had to fix a bug in my OS, fix a bug in my assembler/linker and had to implement a missing instruction (unsigned greater than or equal) in my compiler, that I somehow had not gotten around to and which my entire OS has avoided using so far. The fixes are always fairly straightforward, it's the tracking down that is the interesting part.
An lastly of course, the score: DME clocks a Dhrystone score of 465. Just for comparison that puts DME about on par with a PDP-11:
- Apple IIe, 65c02 @ 1.02 Mhz => 37 dhrystones
- Z80 @ 2.5 Mhz => 91 dhrystones
- 8086 @ 8 Mhz (Aztec C compiler) => 203 dhrystones
- IBM PC/XT 8088 @ 4.77 Mhz (Mark Williams C compiler) => 275 dhrystones
- PDP-11/34A V7 Unix cc => 449 dhrystones
- DME @ 8 Mhz => 465 dhrystones
- Macintosh 512, 68000 @ 7.7 Mhz => 625
- Vax 11/780 => 1560 dhrystones
The performance isn't too great when you take the clock speed into account, but simplicity over performance has been the motto.
16-bit 'modern' homebrew CPU
DME is 16-bit custom CPU complete with a full software stack and a multi tasking operating system.