Gilchrist
Gilchrist-
A picture is worth 2 re-writes
05/13/2015 at 04:25 • 0 commentsFrom early April 2014
It's about time for a diversion into visuals. Output via the serial connection isn't where I wanted to end up so I needed to look at an LCD display.
I already had a 1.8" 160x128 TFT LCD SPI driven screen knocking around and had even written a custom library to drive it.

Why?
The Adafruit GFX and UTFT libraries both worked with the display but there were problems.
The UTFT library was extremely slow, as it seemed to ignore hardware assisted SPI, and bit banged away in software. It also didn't over-ride the print procedure and had it's own methods of text output. Shudder.
The GFX library was comprehensive and used the standard print procedure but also chewed through the KBs.
I took the Adafruit GFX library as a start and ripped out everything not related to the display I had. I also improved the speed of some of the routines, like circle drawing. Optimising the calculated sectors gained a 4 times speed improvement.
This library is available on Github [1]. https://github.com/zigwart/Adafruit_QDTech
Character drawing was still extremely slow and the reason for this is that each character is draw pixel by single pixel. For each pixel drawn, the following data needs to be sent through SPI:
1 byte write command column set 4 bytes start and end column position for pixel 1 byte write command row set 4 bytes start and end row position for pixel 2 bytes write data to ram command 2 bytes hi and lo pixel colour byte Add those up and each pixel write requires 14 bytes to be written down the SPI bus (and a whole load of Arduino pin updates). This means a compact 6 x 8 pixel font is going to require 6 x 8 x 14 = 672 bytes written. Phew!
Now do that about 26 x 16 [2] times for a full screen of text and that over 279 KB to be written.
The only advantage the GFX library has in drawing characters pixel by pixel is that text can be rendered on top of existing pixels or background colours and these will show through the 'blank' undrawn areas.
As I didn't really care about that [3] and was really just interested in block text output, I re-wrote the character output to define the drawing window once, and draw the 6 x 8 character pixels in a stream.
There was still the initial 12 byte setup but in total just 12 + 6 x 8 x 2 = 108 bytes per character drawn. Or just over 44 KB per page. That was over 6 times faster. Sweet.
I encoded the 6 x 8 pixel font in the usual LCD library way, as vertically oriented bytes and the 6th bit/column always a 0x00 so that was omitted. Because: space saving.
// Standard ASCII 5x7 font for chars 32+ static const char font[] PROGMEM = { 0x00, 0x00, 0x00, 0x00, 0x00, // Space 0x00, 0x00, 0x5F, 0x00, 0x00, // ! 0x00, 0x07, 0x00, 0x07, 0x00, // " etc.The LCD display was 3.3v, and I'd hooked it up with 6.8K in-line resistors to drop the Arduino's 5v down. Hacky, yes, but it seemed to work fine and didn't effect SPI speed at all.
Trying this all out, I then came to the obvious conclusion that displaying a webpage in 26 x 16 characters at a time isn't going to be pleasant at all. Even my old Commodore 64 had a better resolution. [4]
So I had to do choose another LCD display (a whopping 320 x 240 pixels this time) and write another optimised-for-text library again. [5] You're welcome.
This library didn't do anything except draw rectangles or characters. I figured I could do without diagonal lines and things to save space. And 53 x 30 characters per page would have to do.Next up: back to parsing HTML.
[1] The LCD is this one from Banggood http://www.banggood.com/1_8-Inch-Serial-SPI-TFT-LCD-Display-Module-With-Power-IC-SD-Socket-p-909802.html?p=Y72005166717201304!W
[2] 160 / 6 = 26, 128 / 8 = 16 of course.
[3] In fact, overwriting all pixels underneath a character is an advantage for text-based output. You don't have spend time erasing the previous character contents first.
[4] Only just. It had 320 x 200 pixel resolution. Or 40 x 25 characters (at 8 x 8 pixels each).
[5] That LCD is also from Banggood http://www.banggood.com/2_2-Inch-Serial-TFT-SPI-LCD-Screen-Module-HD-240-x-320-5110-Compatible-p-912854.html?p=Y72005166717201304!W
-
HTML, It’s Bigger on the Inside
12/30/2014 at 22:44 • 0 commentsFrom late March 2014
Before I solved the problem of unreliable downloading [1], I did a lot of messing around with linear and ring buffers to try and speed things up. I had some nice code for a ring buffer and was happily using that for the incoming HTML but, like the One Ring, it had the same problem. It was too heavy (in terms of KBs used).
So I had to toss that code into the volcano.
Then I had a radical thought, as mentioned in my previous post: Don't use a buffer at all. I thought I might just parse the HTML as it streamed into the Arduino.
It was at this point that I actually thought to do a web search to see if anyone else had created some HTML parsing code for an embedded CPU.
Of course no-one had. It's a silly thing to do. [2]
I needed something, not only for compact storage but it's much easier and faster to check the match of a single numerical value versus some arbitrary length string.
So, roll up sleeves and get thinking. Some kind of hash like md5 seemed in order. I had some criteria, which meant I couldn't use 'big' hashes. No, that would just be too easy.
It needed to be:
- Fast to run on an Arduino (no complex maths)
- Able to return a numerical hash
- Able to fit in one byte, ideally, but definitely no more than two bytes
On the plus side, it only needs to return unique hash codes for the set of HTML tags I would be implementing.
After a bit of thinking, referring to HTML tags and experimental hacking I settled on the following simple function, which iterates over each char (c) of a string.
tagHash = (tagHash << 1) + ((int) toLowerCase (c)) - 32;
ASCII values less that 32 are not used, so most of the time the character values will be between 0 - 94 and HTML is not case sensitive anyway. [3]
The right-hand side of the function handles uniqueness between similar valued characters and the left-hand side handles spread for longer tags (by doubling the current tag value). This results in integer magnitude values rather than bytes, but I could live with that. A function to squeeze HTML into a single byte would be too complex.
Yes, with hind-sight, it would have been better to convert all characters to upper case, rather than lower case. This would have resulted in an input range of 0-64. [4]
Note that the enclosing angle brackets < > of a tag are not included in the hash (but I often include them in code comments for clarity). Not only are they not unique, but ignoring them allows me to do some interesting stuff later on.
Once I had the hashed HTML tags, I could use them for logic or match and replace them with a special ASCII code for writing to the SD card.
It's about time for some actual code. My definitions and conversion tables are below.
// Use non-printable ASCII characters for tag codes #define TAG_CR 14 #define TAG_HEADING1 15 #define TAG_HEADING2 16 #define TAG_BOLD1 17 #define TAG_BOLD2 18 #define TAG_LINK1 19 #define TAG_LINK2 20 #define TAG_LINK3 21 #define TAG_HR 22 #define TAG_LIST 23 #define TAG_PRE 24 #define TAG_PRE2 25 #define TAG_HTTP 26 // Hash -> tag & flag mappings #define NUMTAGS 76 static const uint16_t tag_codes[] PROGMEM = { 161, TAG_HEADING1, // <h1> 162, TAG_HEADING1, // <h2> 163, TAG_HEADING1, // <h3> 164, TAG_HEADING1, // <h4> 80, TAG_CR, // <p> 226, TAG_HR, // <hr> 246, TAG_CR, // <ul> 234, TAG_CR, // <ol> 225, TAG_LIST, // <li> 553, TAG_PRE, // <pre> 221, TAG_HEADING2, // </h1> 222, TAG_HEADING2, // </h2> 223, TAG_HEADING2, // </h3> 224, TAG_HEADING2, // </h4> 443, TAG_CR, // <br/> 214, TAG_CR, // <br> 110, TAG_CR, // </p> 294, TAG_CR, // </ol> 306, TAG_CR, // </ul> 285, TAG_CR, // </li> 673, TAG_PRE2, // </pre> 66, TAG_BOLD1, // <b> 96, TAG_BOLD2, // </b> 5199, TAG_BOLD1, // <strong> 6159, TAG_BOLD2, // </strong> 65, TAG_LINK1, // <a> 2253, TAG_LINK2, // URL 95, TAG_LINK3, // </a> 1428, 38, // Ampersand -> & 2682, 96, // 8216; Curly single quote -> ` 2683, 39, // 8217; Curly single quote -> ' 6460, 128, // nbsp; 2680, 34, // 8220; Curly double quotes -> " 2681, 34, // 8221; Curly double quotes -> " 2677, 45, // 8211; Hyphens en -> - 2678, 45, // 8212; Hyphens em -> - 368, 62, // Greater than -> > 388, 60 // Less than -> < };While I was at it, there was something else I'd need to hash in a similar way. Every ampersand escaped HTML character would also need to be converted to a chosen ASCII equivalent.
An advantage of using this table for matching is that I can also use it to map any type of heading tag <h1>, <h2>, etc into just on heading tag. The table above also gives clues to the tags I was going to support for output.
Now, as the characters stream in I can flag a '<' character and start converting all following characters into the hashed value. If I hit a break character I set another flag and stop hashing. After reading a '>' character I can output the hash value, reset the flags and output plain text again.
Yeah, that should work.
[1] Or made it slightly LESS unreliable.
[2] Refer to my first post.
[3] See my last post. Those codes are for HTML tags aliases.
[4] There's no way I'm going back to change all my HTML hash references and changing the function now. It works as it.
-
Leaves on the line
10/15/2014 at 07:59 • 0 commentsFrom early March 2014
So where are we at with the PIP Arduino web browser? Let me explain. No, there is too much. Let me sum up.
It can download raw HTML from a fixed website to a cached file on a SD card. Most of the time. [1]
Yeah, that's about it. I've got a bad feeling about this. But after all my obsessing last time about the lack of space for program code, I forgot to mention that the Ethernet and SD card libraries only left about 864 bytes of RAM to play with. This really is like retro coding after all.
To make matters worse, HTML is an extremely verbose mark-up language. That's fine it you want to do a load of string passing and regex matching. I don't. If fact, I didn't even want to crack open the Arduino string library to save space. [2]
So here is my cunning plan; replace all the verbose text tags with a single byte equivalent for the tags I'll be implementing and dump the rest. [3] After I've done the hard work of parsing HTML once, handling one byte codes should make rendering much easier.
The ASCII character set is little used most of the time for values above 128, so I considered using characters there. But some of them are used for special characters. [4]
ASCII below 32 (space) are generally non-printing characters and a lot are there for "Historical reasons" now, so I'll commandeer some of them. It's open season on everything after ASCII 13 (carriage return) up to 31. All your ASCII are belong to us.
Before I could really get into HTML decoding, I had to address the problem with download reliability. It seem that the Ethernet shield is fine for downloading little 1KB pages for IoT projects [5] but larger pages … Houston, we have a problem.
It seems the shield supplies data to the Arduino in 2KB chunks (even the Wiz5100 has much more memory for buffering). My download program can often consumed the Serial buffer down to nothing and have to wait some time for it to refill.
Too long. More time than the Serial.read() procedure will wait for before timing out. The Serial.readBytesUntil() procedures aren't much better. And the example Ethernet code doesn't wait around. If ethernetClient.avaialble() returns 0, it's immediately checking for ethernetClient.connectd() - which often bails early. [6]
I adapted some found code for a custom readBytesUntil. I can give this a really big timeout period. [7] I've also got an increasing delay period when the buffer's empty, to really make sure the connection is dropped before giving up.
I'm using these routine to zip through the pre-HTML headers and other bits, so the pre-emptive terminator of '<' is handy.
Code time:
//================================================ // Consumes data from Serial until the given // string is found, or time runs out //================================================ byte findUntil (uint8_t *string, boolean terminate) { char currentChar = 0; long timeOut = millis() + 5000; char c = 0; while (millis() < timeOut) { if (ethernetClient.available()) { timeOut = millis() + 5000; c = ethernetClient.read(); if (terminate && (c == '<')) return 1; // Pre-empted match if (c == string[currentChar]) { if (string[++currentChar] == 0) { return 2; // Found } } else currentChar = 0; } } return 0; // Timeout } //================================================ // Delays until Serial data is available //================================================ boolean inputWait() { byte wait = 0; long timeOut = millis() + 5000; // Allow 5 seconds of no data while ((millis() < timeOut) && (!ethernetClient.available())) { delay(++wait * 100); } if ((!ethernetClient.available()) && (!ethernetClient.connected())) return 0; else return 1; }[0] The title of this post refers to a common reason given for UK trains being delayed or late. "Your train has been delayed due to leaves of the line."
[1] There are issues I'll get into later.
[2] And I've heard it's a bit buggy sometimes.
[3] Sounds easy when you say it fast. Like "Put a tail on it and call it a weasel." Have you ever tried doing that?
[4] That's where Johnny foreigner keeps all his funny letters. And there's no real standard for the characters up there anyway.
[5] Internet of Things.
[6] No-one has any patience nowadays, it seems. I blame computer games. Welcome to Global Thermonuclear War. Shall we play a game?
[7] Five whole seconds! Which is a lot in internet time.
-
Memory isn't what it used to be
10/06/2014 at 07:23 • 0 commentsFrom late February 2014
The first test off the block was to adapt the default Arduino WebClient example. I've got a standard Ethernet shield, so there's no Slave Select pin to muck about with – it's on pin 10.
As used in the example code, google is a poor example of a website to try. The main google search website may look clean and simple but, oh my, there is a ton of junk being loaded behind the scenes. [1]
The example WebClient program compiles to 14,288 bytes. This is not promising and doesn't leave me much memory to play with. [2]
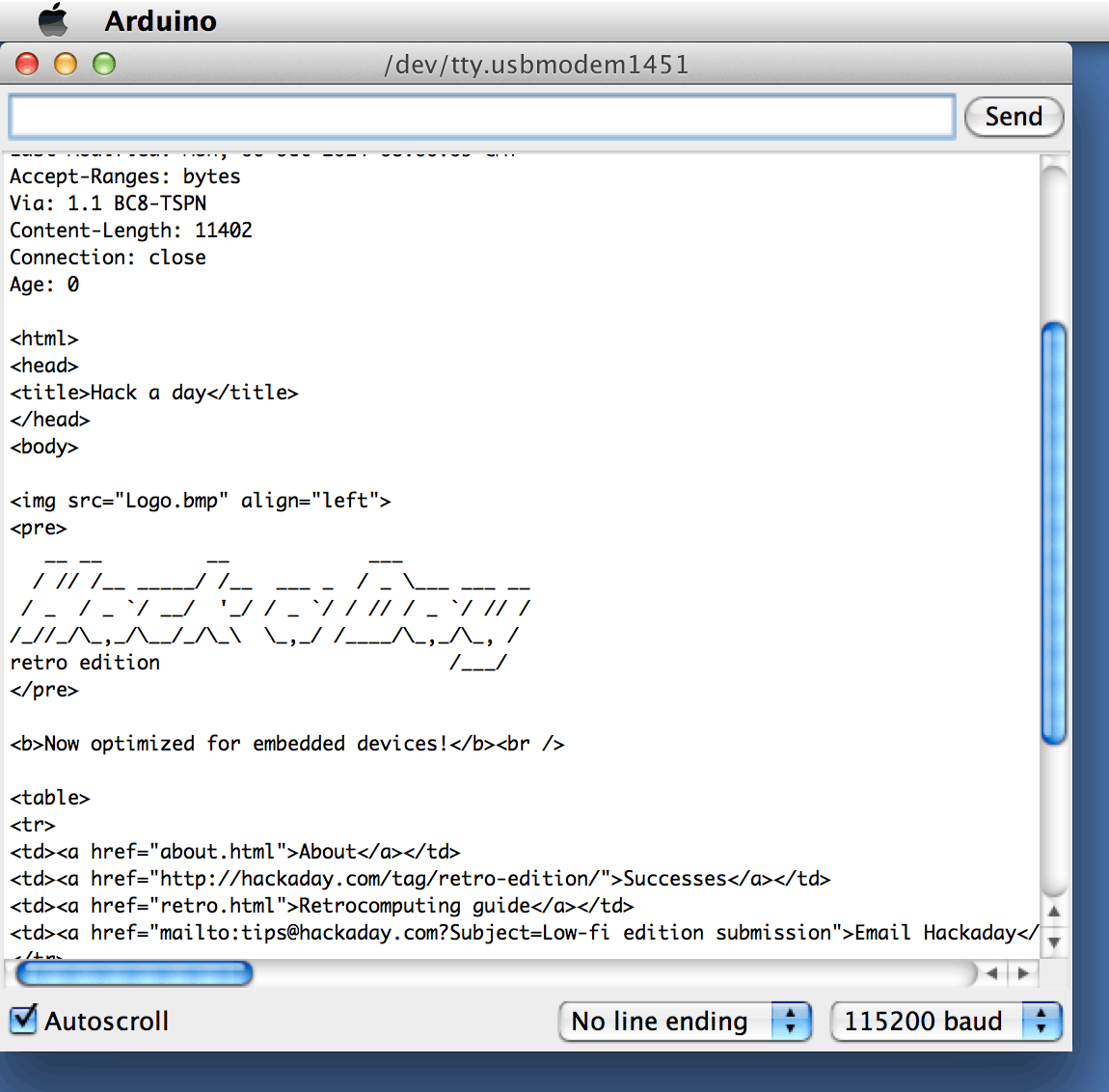
Then I opened up the SD card ReadWrite example and grafted it onto the WebClient code. The downloaded HTML is now dumped to an SD card file. [3] This lot compiles to 25,254 bytes.
OK, I'm worried now. About 70% of the memory is used [4] and all I've got is a dumb http downloader.
I discovered that if I removed the DHCP IP allocation and used a fixed IP address, it complied to 'just' 21,340 bytes. So I can claw back just under 4 KB if I have to. Still, I'd like to keep the dynamic IP allocation if possible. Plug and play is nice.
I also upped the serial connection speed to 115,200. Doing anything on the web at 9600 is not fun. The W5100 chip has got 16 KB of buffer space but you don't want to keep it waiting too long.
It appears that the Ethernet and SD card parts of the shield don't play well together [5]. I had no trouble with the Ethernet shield initially, but if there was a card in the slot and I wasn't even using it, Ethernet would go screwy on me. And it was really, really slow getting an IP allocated. The same screwy behaviour occurred whilst using the SD card slot and not Ethernet. [6]
The example code explicitly sets the Ethernet Slave Select pin to output early in the setup code but I discovered that I also had to set that pin high manually before trying to initialise the SD card library. Or open files.
In my Internet travels, I discovered William Greiman's fat16 library for Arduino. [7] It's not an 'official' library but when I use it in my HTML download and save test above, the compile size was 19,152 bytes. 6 KB smaller. William, you are my hero, and DHCP IP number allocation, you shall go to the ball.
[1] How else are they going to go all Big Brother on you?
[2] Actually, I have plenty of memory to play with: 1.3Kg of organic holographic memory of indeterminate capacity. Only problem is, it's well out of warranty and I think there are some loose connections somewhere.
[3] Congratulations! A web browser. Well, a crap one.
[4] It looks like the same rule as hard drive fee space and space left in the cupboard under the stairs applies: No matter how big they are, they're always 80% full. This rule does not apply to humans; Probably the opposite.
[5] Just like real siblings, then.
[6] Things were also unreliable when both SD card and Ethernet were being used together, logically.
[7] It only supports FAT16 formatted cards, so capacity is limited to 2 GB in size. I can live with that.
-
Hackaday Retro is to blame
10/05/2014 at 00:40 • 0 commentsFrom Early February 2014
An Arduino-based web browser.
This is a silly idea. [1]
I just wanted to get that out of the way early. This is the kind of idea that's probably going to end up reported on Hackaday FAIL.
I've been an avid follower of Hackaday since about 2010 and messing about with Arduino since the same time. I learnt to code on 8 bit home computers, so I'm hardly a newbie and have already been doing some daft things with Arduinos. And still using the Arduino IDE. [2]
I kept reading about people getting web browsers running on their old computers in the retro section of Hackaday and the idea occurred. Why not get a web browser running on a standard Arduino Uno? [3]
Well, let's do some comparisons:
The venerable Commodore 64 has a 6510 1MHz 8 bit processor with 64KB RAM and a 170KB disk drive available. [4]
The Arduino Uno has an ATmega 328 20MHz 8 bit processor with 2KB RAM, 1KB EEPROM and 32KB Flash RAM (ROM, essentially). The chip is run at 16MHz.
Although the ATmega 328 is much faster, it has practically no memory. Browsing is probably going to be memory intensive and web pages are going to have to be stored somewhere. I didn't fancy on-the-fly decoding every time. Luckily, SD cards are available to dump info to. [5]
So what have I got to work with now? An Arduino Uno, Wiz 5100 Ethernet shield and the included micro SD card slot. This is starting to look possible.
Oh, and just 32 KB of code space. This is starting to look unlikely. [6]
[1] No, it is, really.
[2] I really need to start using the Atmel or some other full IDE.
[3] Because it's a silly idea. And the ATmega 328 is not retro.
[4] I was going to use the Apple ][ for the example but, despite what Apple might say, the Commodore 64 is the biggest selling 8 bit computer ever. The Apple ][ is the third I believe. I've used both.
[5] The smallest of which I could find now was 2GB. Sheesh!
[6] And I haven't even mentioned the known problems associated with parsing sloppy-old HTML code cleanly. Let along in 2KB of RAM and under 32 KB of code.
PIP Arduino Web Browser
Surf the web using an Arduino and an ethernet shield. Because you can.