 Yann Guidon / YGDES
Yann Guidon / YGDESNow that I got a working Flash EPROM programmer, I can progress on the multiply unit of the YASEP.
The canonical architecture is explained there http://archives.yasep.org/yasep2014/#!tuto/multiply and the discrete version will use a variation of this theme.
Input data (SND and SI4) are read from the respective buses (and latched, huh!). The SND operand is shifted/MUXed, one byte is selected depending on the opcode (MUL8L or MUL8H). SI4 is simply truncated to its 8 LSB.
The 8×8 bits multiply can then proceed. The Actel/FPGA method uses partial parallel 4×4 lookup tables that get combined with several adders. For the Discrete version, we can afford the luxury of implementing a full lookup table, 16 bits in => 16 bits out, using a couple of 64KB Flash memory devices.
In practice, I have different chips but they fit the bill as well:
- For the DIP prototype, I have a pair of 128KB flash that is ideal. The AM29F010-55 is almost as fast as the ALU and there is room for another constant lookup table. It works at 5V.
- For the SMD version, the AM29LV160DB-90 directly provide 16 bits but is a bit slower. It's a 3.3V part though, the surrounding devices must be adapted.
These devices have more capacity than 64KB. The extra room is used to perform signed operations, while the original YASEP definition only implements unsigned operations.
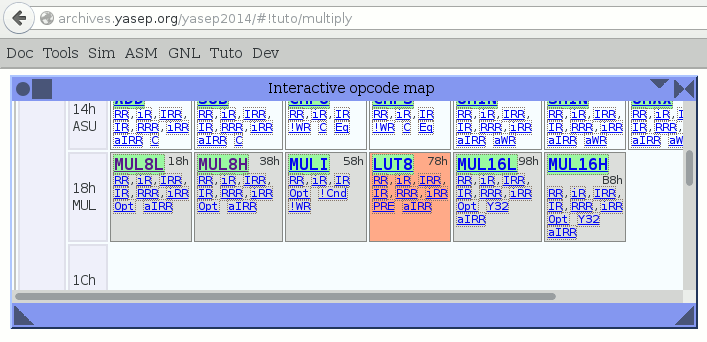
The MULI instruction is useless in this case because the lookup tables are not implemented with SRAM blocks. The LUT8 opcode can also be deleted and the MULI/LUT8 pair is replaced by IMU8L/IMU8H in this implementation. The 16 bits opcodes are not touched, to preserve upwards compatibility.
Beware when using IMU8H because I haven't figured out how to combine it with other multiplied... It probably makes not sense to implement it but "it comes for free".
In the DIP ALU, the LUT will be made of two parallel AM29F010-55. Each will hold one byte of the result and they receive the exact same addresses on bits 0 to 15. Bit 16 directly comes from the opcode: when set to 1, this is a signed multiply, which selects the higher half of the memory.
The contents of the unsigned multiply tables is very easy to calculate. Here is a quick script in bash:
# print the LSB of the table
for i in $(seq 0 255)
do echo i=$i
for j in $(seq 0 255)
do echo $(( (i*j) & 255 ))
done
done
# MSB:
for i in $(seq 0 255)
do echo i=$i
for j in $(seq 0 255)
do echo $(( (i*j) >> 8 ))
done
doneI told you it was easy. For the signed version, it's just a matter of changing the arguments to seq (and masking the sign MSB):# signed LSB
for i in $(seq -128 127)
do echo i=$i;
for j in $(seq -128 127)
do echo $(( (i*j) & 255 ))
done
done
# MSB
for i in $(seq -128 127)
do echo i=$i;
for j in $(seq -128 127)
do echo $(( ((i*j) >> 8) & 255 ))
done
doneWait, we can't write this directly to the Flash chips. The data are written in decimal ASCII and we want binary. Bash can read data in bases from 2 to 64 but can't export them... Welcome in UNIX hell :-P
The easiest way I have found uses the standard utility printf. Unfortunately, unlike its C counterpart, printf "%c" 1 will simply write the first character, which is '1' in ASCII and not in binary. However printf supports a "direct" notation for the characters: "\x42" for the ASCII character '<'. There is no equivalent for a decimal number (no \d) but printf also supports conversion of a decimal number to another base. We all know where it's leading us to: use printf on printf's output, first to create the hex number, then to output it. For example:
printf "\x$(printf '%x' $(( 6*7 )) )"When we put this all together, we have the following script:
#!/bin/bash
# Write the LSB file:
( # Unsigned:
for i in $(seq 0 255); do
for j in $(seq 0 255); do
printf "\x$(printf '%x' $(( (i*j) & 255 )) )"
done
done
# Signed:
for i in $(seq -128 127); do
for j in $(seq -128 127); do
printf "\x$(printf '%x' $(( (i*j) & 255 )) )"
done
done
) >> MulTableLSB.bin &
# Write the MSB file:
( # Unsigned:
for i in $(seq 0 255); do
for j in $(seq 0 255); do
printf "\x$(printf '%x' $(( (i*j) >> 8 )) )"
done
done
# Signed:
for i in $(seq -128 127); do
for j in $(seq -128 127); do
printf "\x$(printf '%x' $(( ((i*j) >> 8) & 255 )) )"
done
done
) >> MulTableMSB.bin &Can you believe it took more time to figure out how to output binary data, than to compute the table ? Oh and the script is particularly slow of course, that's why I forked the two parts. It should run 2x faster if you have 2 cores. It can further be split for 4 cores, the partial files must then be concatenated.
The final script is there:
#!/bin/bash
UNSIGNED=$(seq 0 255)
SIGNED=$(seq -128 127)
# Write the LSB files:
( # Unsigned:
for i in $UNSIGNED; do
for j in $UNSIGNED; do
printf "\x$(printf '%x' $(( (i*j) & 255 )) )"
done
done
) > MulTableLSB_Unsigned.bin &
( # Signed:
for i in $SIGNED; do
for j in $SIGNED; do
printf "\x$(printf '%x' $(( (i*j) & 255 )) )"
done
done
) > MulTableLSB_Signed.bin &
# Write the MSB files:
( # Unsigned:
for i in $UNSIGNED; do
for j in $UNSIGNED; do
printf "\x$(printf '%x' $(( (i*j) >> 8 )) )"
done
done
) > MulTableMSB_Unsigned.bin &
( # Signed:
for i in $SIGNED; do
for j in $SIGNED; do
printf "\x$(printf '%x' $(( ((i*j) >> 8) & 255 )) )"
done
done
) > MulTableMSB_Signed.bin &
echo merge:
echo 'cp MulTableLSB_Unsigned.bin MulTableLSB.bin'
echo 'cp MulTableMSB_Unsigned.bin MulTableMSB.bin'
echo 'dd if=MulTableLSB_Signed.bin >> MulTableLSB.bin &'
echo 'dd if=MulTableMSB_Signed.bin >> MulTableMSB.bin &'I pre-computed the list of numbers to save a bit of CPU. I know it would have been better in C (or Python or whatever) but I couldn't bother. Bash has "free" parallelism in this case and my i5 rarely works at 90% of CPU capacity.(I hear that echo would work almost as well as prinf... too late to try.)
The result is there:
992 8 nov. 21:59 GenerateMulLUTs.sh
65536 8 nov. 22:00 MulTableLSB_Unsigned.bin
65536 8 nov. 22:00 MulTableLSB_Signed.bin
65536 8 nov. 22:00 MulTableMSB_Unsigned.bin
65536 8 nov. 22:00 MulTableMSB_Signed.bin
131072 8 nov. 22:00 MulTableMSB.bin
131072 8 nov. 22:00 MulTableLSB.binMulTableLSB.bin and MulTableMSB.bin are ready to be flashed :-)

How many computers had their multiply unit ready before the rest of the ALU ? :-D
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
Hah, I'm telling yah, the entirety of a CPU could probably be implemented in little more than LUTs ;)
Nice Bashing... never heard of "seq", and doing bin-conversion is one of those things that took me way too long to figure out, once, as well :) printf!
Are you sure? yes | no