Danny
Danny-
HDD Failure
08/05/2015 at 17:45 • 0 commentsPerhaps an abject message on why this sort of thing was important,
The hard drive in my laptop died, taking all my data (and code) with it.
I can't help but feel that had I got into the spirit of this properly and open sourced messy code from the start I'd at least have something...
On the other hand, it's also erased a whole load of other projects that I had been working on... so with a clear new laptop, and literally no half finished projects it seems like a good time to be starting this again...
-
update
03/11/2015 at 16:33 • 0 commentsThis project isn't dead (though updates are few and far between).
It's taken a bit of a back seat to life at the moment.
Thus far completed is:
Posix compliant directory listing, this enables both "server" and "client" to look into the directory structure and "see" what files are currently on the device that need to be replicated.
(however I developed this on windows and the file size and file name length is not posix compliant and will not compile with the headers in Debian/rasbian)
Address lookup - enabling clients to register themselves with gateway servers as available file hosts.
Geoip lookup of servers is in progress using freegeoip.net to have clients directed to "close" possible mirrors. -however for CDN this may be dropped, as the main server (e.g. www.test.com) needs to lookup the client address.
and then match that to a location country, then point the client to mirrors in that country. (I've got concerns over whether this is the best way to do this, or whether a better way could be sought using GeoDNS -the thing that stops me wanting to use geodns is the need for people setting up networks to essentially install and configure bind. -for most people who really just want a nice way to keep files backed up at work and replicated to home setting up bind and geoDNS and all the associated services would just be a huge pain.
Dynamic DNS registration is in progress. - e.g. automatically updating a no-ip.com account. or clients checking their own IP address and automatically telling other servers that they exist at a different location.
Nothing is ready for release at this time however:
the code needs to be cleaned up, properly commented, and there is as yet no security at all.
All actions must be traceable for each network node (whether that node is a server or a client).
As there will be machines saying, for this website you may get content from Alice at a.a.a.a or Bob at b.b.b.b, there must be a way for Alice to say, "Alice got a new IP which is c.c.c.c, -replace a.a.a.a with c.c.c.c for future use" but not for David to impersonate Alice and say "Alice is now on d.d.d.d, replace c.c.c.c with d.d.d.d for future use."
So essentially, code is coming along... slow and steady.
-
Open Source Licenses?
08/26/2014 at 12:16 • 0 commentsIt might seem a bit funny to say, especially since I'm still only about a tenth of the way towards the barely started point in both the projects that I have going on. but I'm uncertain of what open source license to use.
I've been a bit unsure for a while -at least since the mooltipass project changed it's license, I'm pretty sure that there is no sense in re-inventing the wheel so whatever license I use will have to be compatible with that particular license.
Originally I'd planned to invent my own licenses that simply would say, completely un-restricted and open -do what you like with it. but that would never be compatible with any existing license.
And since I've essentially "called out" commercial failings, in both of the projects that I'm doing, at either an expense and complexity, or saying that nothing commercial exists that does this at this level, it would seem like a crazy idea to effectively say to those businesses, I see a gap in the market, and here's a product you can use to fill it, and I want nothing for the work that I've put into it. -and yet at the same time a licenses that is too restrictive would kill any interest in a project that is supposed to be open source. And compared to large manufacturing corporations in foreign countries that have no care for intellectual property laws, one guy trying to apply a license might be like Canute trying to stop the incoming tide.
I'm also aware that copyright can be asserted to words, and not designs, essentially you can't really copyright or license hardware without staking your legal claim via an expensive patent route. I guess one blessing in all of this is that the hardware designs of what I'm doing are fairly well understood by most, use commodity components, and it's the software that supplies the special sauce... -and software is a copyrightable "entity".
So, suggestions on a postcard please (or at least in a comments.)
I'm looking for a license scheme that would enable any "user" of the hardware/software to freely obtain make and use the hardware and software. but at the same time would compel a "business" to need to seek permission for manufacture and distribution.
Basically, if you want to "use" or make the thing yourself, then I'd assert no restrictions what-so-ever, non-commercial people should be free, free as in without cost and without restriction.
But, if a business wants to manufacture and sell in bulk, and make money from my work. Then I'd like a tiny slice of that pie. -
Video update
08/20/2014 at 19:36 • 0 commentsSo whilst I was completing the entry requirement for the competition (a sub 2 minute video) saying that I was basically building a user controlled voluntary CDN. I though tI should do a video update, basically because it seemed easier than typing out the update.
Though now that I see how terribly bad the google translate is I've decided to link the video and explain what's going on also.
In the left side of the video is a Raspberry pi model B, this has a USB cable attached whilst goes off to a small board that I've had made that converts USB to SATA, basically so that cheap hard drives can be attached giving mass storage. (schematics to be released)
That server is acting as the master or gateway server, it attaches to a switch that has some layer 3 functionalities, with ports split into VLANs this then has a laptop sat on top running some virtual routing and virtual firewall software, and some DNS services for the nodes to find each other.
Essentially there is a mini "internet" where each pi sits behind a firewall/router as if it was in a home environment. and there is a network in the middle that connects the two environments to each other. and provides name resolution services to both environments.
The second Pi establishes a connection as a guest server, either for a first time, or rejoining the network after being off for some time, the first thing it does is performs some handshaking with the existing gateway server (where gateway server just means a publicly accessible node, - usually with a DNS registered name so anyone can easily remember it)
When connected the pi essentially questions the server "what files do you have" and the server responds.
The hand shaking part and authentication by password (in plain text) is essentially complete, and I've started working on listing out and sending directories.
additionally I've started working on a hashing algorithm, the reason for this is that even a directory listing of a large file repository can be big,
whilst hashing is a CPU intensive task (and arguably not particularly suited to the low power pi) it will mean that a directory listing can be sent in a few hundred bytes to compare against a listing already received,
Files can first be sent as checksums, to see if these exist, and then if they do not the file can then be sent, rather than sending a whole file with no reason, or relying in file names for identity. -
Software started
06/28/2014 at 10:07 • 0 commentsSo I've started working on the software to be used to hang all this stuff together.
Afterall the hardware design is nice to use for this project, and indeed with practically ANY linux distribution can be a regular standalone webserver or FTP or database, mail, dns or any other server.
But the point of this project is to provide a decent device, with a real purpose.
The small unobtrusive box with very little on show aspect of this project is a nice way where people can get this box into their homes, nestled under their broadband routers etc, but for people to want the box it needs to have a purpose, that purpose is provided by the software.
The task of trying to build a free and open "cloud" solution for sharing files -think of it as a CDN, is not trivial. trying to make it as robust and secure as possible is also pretty daunting!
The fact that I'm not even 100% through with the planning part is a sure sign that I'm not ready to start writing code yet, however, I need some break from process flow charts.
I have been sketching out some process diagrams, (most of which can be simplified to the simple mantra of "connect, Authenticate, Share") so that's what I'm starting to write as code at the moment.
I had toyed with the idea of making things "simple" from the start.
so connectting to a gateway that can't be changed, on a port that can't be changed, but after a short while things need to be user configurable, so it only makes sense to start off with the whole program being configurable!
The perhaps single biggest limitation that I'm coming up against right now is that I am not a software developer by trade, this means that the way in which I write and present code may be different from what others expect.
Since this is an open source project. I've decided to try to write everythign in as modular fashion as possible. and everything being as generic as possible
In practice what this means is that I'm farming everything out as functions. The good thing about having got process flow charts down on paper is that I know that "connect" is a function, and that "Authenticate" is a process made of many functions. so it's reasonably easy to know what functions I need, -and what those functions need to accept and return...
In this way, if a person wants to add or remove funcionality, or change the way in which a connecttion happens they need only change that specific part, -and without thousands of lines of source code to worry about the software should be more inviting to change.
Code blocks won't be coppied and pasted. functions will be re-used in a place where copy and paste is tempting. -what I mean is that the code to connect to the Gateway server/entry point to the network, should be no different to the code used to connect to other peers.
The way that a hash of a file is made should use the same code at the code used to hash a file part or password. in practice this means that a vulnerability found in the hashing code would affect all parts of the program, but it also means that when a problem is fixed it is fixed everywhere, there isn't lingering bits of code hidden in a place where they were copied to. -
Planning and feature creep. (otherwise known as stretch goals?)
06/13/2014 at 21:22 • 0 commentsThe whole project is still in the planning stages at the moment,
and it's difficult not to add features to try to make the device seem more useful.
for example:
why not add an ethernet switch?
why not add multiple eithernet and make the device a capable router?
why not add RAID to make the device more robust and less likely to fail?
For some of these features it's difficult not to want to do this, it seems that it's be a great idea to have this device as the edge box on the network ,have firewall and routing features built in
but then why not add wireless as well?
Soon I'm looking at rolling an secure OS, FCC compliance etc...
Worse, trying to fit that onto a Raspberry Pi board, (with it's network attached by USB) will give poor connecttion speeds.
in fact in a lot of homes trying to use the raspberry pi as a router would create a bottle neck and limit the connecttion speed.
So at the moment I want to stick to the "core mission" build a software platform for large scale distribution of files and content.
I've been investigating the Raspberry Pi computer module a little more closely.
it's only available as a dev kit this month, though it seems that buying the module outside of the dev kit won't be available until "the autumn"
The projected price for the compute module was around $30 (~£17) individually, so the fact that I might get a single one now, with a board that I don't want to use for almost ten times more is not appealing.
The UK price will likely be £30, as despite being designed and made in the UK, the Raspberry pi foundation, (just like Apple) can't do currency conversion. -must be a fruit thing.
-If you live in the UK, and want to make a reasonable sized order, then you can order from Newark US, pay for international shipping, pay import taxes to the UK, and still pay less than ordering direct from Farnell, (who are the same company as Newark).
The fact that the projected price for the module is only $5 less than the model B (with all it's attached hardware, and an SD card with a pre-installed OS) is a bit weird.
They have a model A board, essentially the same as the model B, but with hardware removed, and those savings passed on to the end user.
Now they have the pi Compute module, which you can think of as an even further cut down board, with no external connectors, no pin headers, pretty much no of anything, and less copper board, but strangely costs more than the model A!
But, the Raspberry pi compute module is not meant for home users. it's meant for professional products where jamming in a model B looks bad...
In some ways I hope that they sort this out and make it cheaper, for the home user (who this board is not targeted at but could use it just as I intend to.)![]()
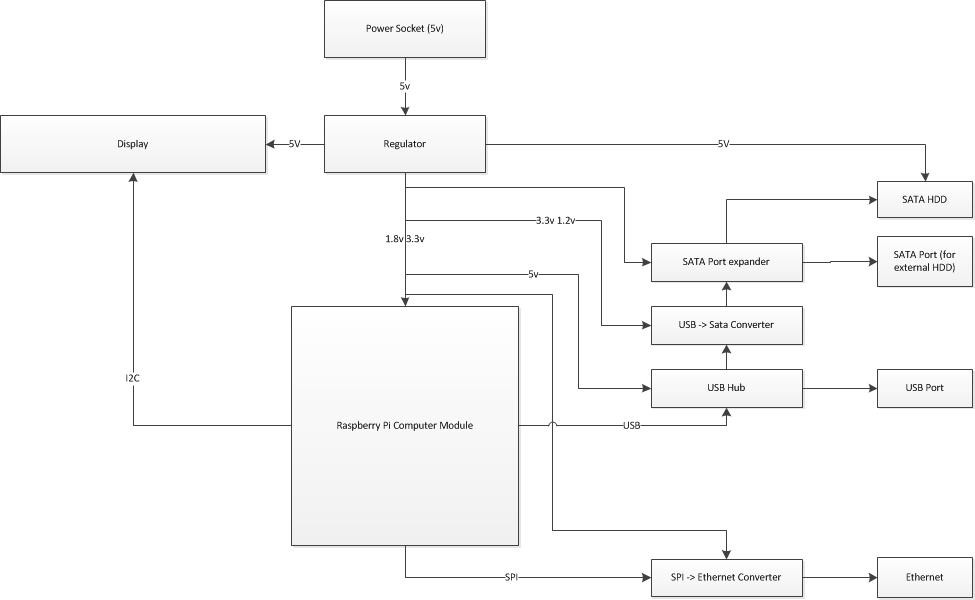
I've roughly sketched out a block diagram of the hardware and how I'd expect it all to hang together.
at the centre of the diagram is the Raspberry Pi Compute module.
Above is a power block, the power supply I'd intend to use would be something along the lines of a 5v 2A supply, (ten watts in total) to feed the power reg circuitry,
From this I'll need a 3.3 and a 1.8v feed for the compute module, (using 3.3v on the vBatt connectors also).
I know almost immediately that I'll be breaking out the USB to create a USB to SATA converter to attach a hard drive.
I'll be using either USB, and a converter, or SPI and a converter to provide Ethernet connectivity.
it seems that IF I use the USB bus rather than the SPI to create an Ethernet port then I'll need a USB hub, and if I implement a USB hub then it would be a useful addition to add USB connectivity, this would enable the connection of external disks, either to expand capacity or add content.
additionally, there are USB to Serial ATA converter chips that provide multiple SATA interfaces, it would seem that allowing the option of creating a RAID array is not out of the question, additionally, if multiple SATA ports are available adding an external eSATA port may be possible.
The final optional component would be some kind of display, at this time I envisage some kind of LCD screen that would allow users to see vital statistics of the unit, (free space, connections, cache completeness (how much is still left to replicate to that device in a pool, upload/download as well as IP address etc.)
At this time the External USB, eSATA, Multiple SATA/RAID and display are "not a core" part of this project, the core functionality will need to be sorted before these features are added. -
Explanation of why this service is needed
05/09/2014 at 09:27 • 0 commentsI've created a short video for youtube to explain why I feel that there is a need for this technology.
(this is clearly outside of the entry to competition requirements as it's more than 2 minutes.) - I will of course be posting a video detailing more technical aspects as the build goes on. -and will post a video inline with the competition entry requirements.)
-
Web caching
05/08/2014 at 23:53 • 0 comments![]()
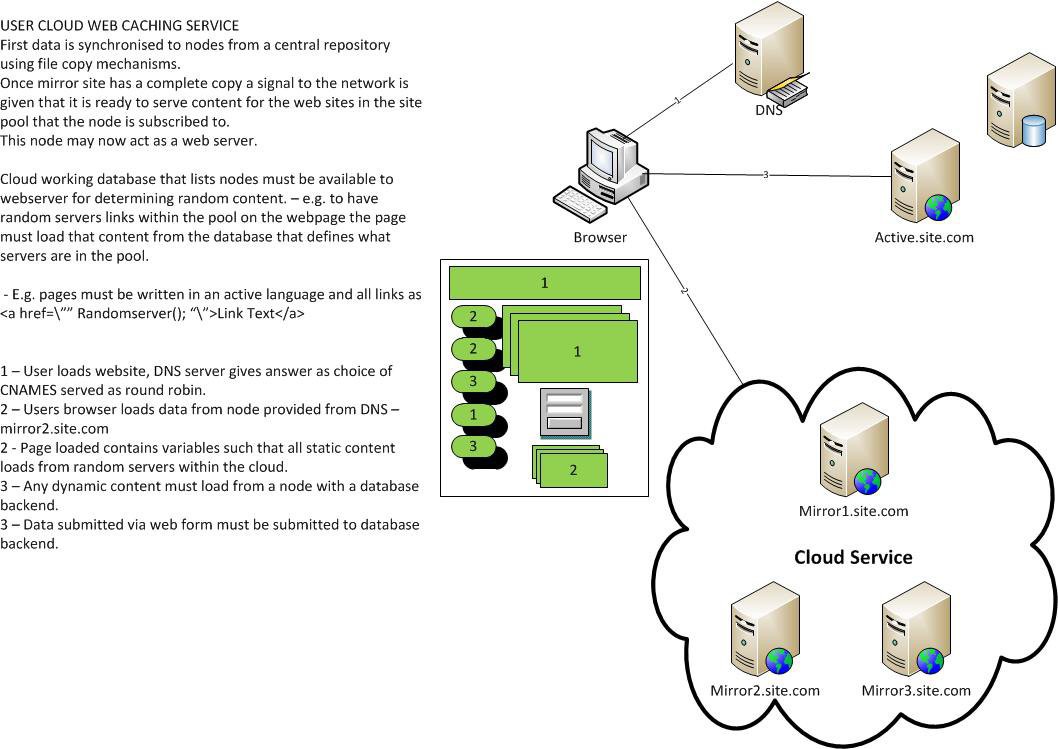
The core service of the home cloud is to be a web hosting platform.
the attached picture (Webcaching.jpg) explains how a client (web browser) will learn of all the nodes in a network and how the page will be served from multiple "slow" nodes, combining to allow a page to load faster...
the basic premise is that if a web page has 1,000 10Kb elements this may take a while to load where the upload speed is very slow.
however combining many slow uploads, where an asymetric connecttion can download faster means that with more hosts and mirrors a page may load faster