 Yann Guidon / YGDES
Yann Guidon / YGDES
Logs:
1. Collision mitigation strategy
2. Hashing algorithm
3. .
4. .
5. .
A "Data Store" for embedded and read-intensive applications.
Already have an account? Log in.
To make the experience fit your profile, pick a username and tell us what interests you.
Logs:
1. Collision mitigation strategy
2. Hashing algorithm
3. .
4. .
5. .
These last years I have worked on #PEAC Pisano with End-Around Carry algorithm which is very versatile and fast. It provides a number of algorithms with decent mixing and fast computation. It is not crypto-resistant but very adapted to embedded or high performance.
PEAC16x2 is a good starting point with 32 or 33 bits of signature, is suitable for small volumes, tens of thousands of files with low probability of collision. It is roughly equivalent to CRC32.
I have identified m=741454 (square root) and m=999999 for a slightly larger signature, scanning is slightly slower but mixing is significantly improved.
For longer signatures, w26 is equivalent to CRC52.
CLEFS is a sort of database, split into 2 parts : the storage and the index. The index is a large hash table that contains fixed-size information and critical fields, the rest (the variable sized data) is stored in the storage (I should maybe call this the vault).
Hash tables have well known characteristics. The hash algorithms are well studied but what bothers me is the collisions.
I don't want to use linked lists when a collision occurs. The index is actually a sparse, monotonicly increasing list of hashes so the index is derived from the hash either by truncation (of the LSB), or by a rule-of-three if the index size is not a power of 2 (for example with a compacted, condensed, read-only file system). Since the keys are sorted and also stored in full, one can find the actual location of the key with a linear scan of the list, backwards or forwards, if the location is not reached immediately.
The index should be able to grow or shrink at will, as it contains more or fewer keys. A power-of-two size is excellent for dynamic resizing.
The first method to deal with collisions is to "push" enough entries around. With a fill of 50%, it's pretty easy, there is enough free room after and before the target location. The dichotomy search algorithm will still find the entry after a small linear scan.
Today I have come up with a different method, and I still ignore if it is used in the wild. Instead of using linked lists or pushing other entries, the key itself could be ... rotated. This should reshuffle the bits nicely if the hash is of good quality. This is potentially slower than the previous method because consecutive accesses are almost free with today's technology. However, there is no need to "push" elements. The only additional requirement is to store a "rotation count" alongside with the key, as well as a reference counter (so the lookup code can know if the hash has a collision and how many items collided). I have to figure out a resizing (shrink/expansion of the index) strategy...

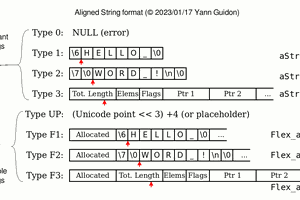

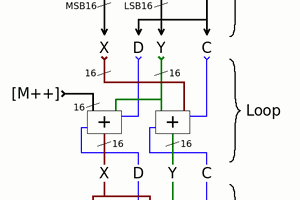
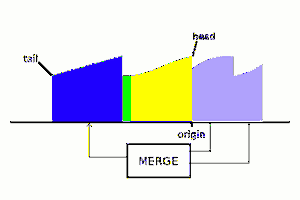
https://hackaday.com/2019/01/24/cool-tools-a-little-filesystem-that-keeps-your-bits-on-lock/