Gene Foxwell
Gene Foxwell-
Some Observations
05/18/2016 at 02:50 • 0 commentsI have evolved several sets of parameters for the swarm. In each case the parameters where scaled between 0-1, concatenated into an array which formed a swarms "genome", and fed to an evolutionary algorithm. The fitness of each swarm was measured as 10000 - Total Iterations required to reach all the goals in the simulation.
Although the best solutions found where typically on par or better than my hand tuned version, they tended to solve the problem in a completely different way. Whereas in the hand tuned version shown in the youTube videos I provided in the logs so far the swarm members appear to co-operate with each other, evolved swarms have a much more random nature.
After much tinkering an debugging I think I have realized the reason for this - the current problem doesn't really benefit a lot from having many robots swarming into the secondary rooms at once. A few members of the swarm that appear to "specialize" in exploration are sufficient to find all the goals in the environment.
This posses two challenges, one foreseen, one not so much. The first is that of the goal, it may simply be the case that this particular task is best suited for the specialize approach and that provided a problem that requires co-operation to solve I can evolve some parameters that will result in the robots co-operation accordingly. The second is the question as to whether with a little tweaking, forcing the swarm to flock a bit better might produce better results.
I have also noticed that in regard to the parameters being used, two of the parameters - the distance that the drones will allow between one another, and the distance before emergency stop - tend to work best when they are varied from robot to robot. That is swarms in which these parameters are the same for every robot do not seem to perform as well as those where this value varies. I am not sure why this is happening yet and will need to study this a bit more to decide if this is a result of the robots design, or a bug in my simulation approach.
Finally there are a couple of research papers I am looking at right now to mine for ideas to improve how the static swarm members co-operate. How much of these ideas I will use is not yet clear as I am still reading these over, however they are listed here for completeness:
[1] https://www.eecs.harvard.edu/ssr/papers/robio10-nhoff.pdf
[2] http://people.idsia.ch/~foerster/2013/02/SwarmanoidPaperTR.pdf
So now I have few avenues of approach that I need to work on to move this project along. I still need to work on the adaptive features I've mentioned in the past. I think this is best done with the hand tuned version of the algorithm where the machines actually do seem to have "flocking" behavior. I need to introduce goals make co-operation a pre-requisite for completeness, examine the effects of the distance / emergency stop parameters to see why they have the effects I have observed, and finally incorporate any useful ideas I can find in the literature to see if the overall system's behavior can be improved as a result.
I will report on each of the aforementioned fronts as progress is made. Github will be updated with my latest simulation code in the morning to ensure that everything is up to date.
-
Slow Progress, but Progress
05/14/2016 at 12:26 • 0 commentsAs mentioned in an earlier project log, the next step of this project is to introduce and study the effects of allowing individual drones in the swarm to adapt. This presents an extra difficulty as thus far the drones have been partially heterogenous - especially in the beacon following department.
Sadly however, finding an efficient homogenous solution wasn't working well by hand. To solve this problem I have implemented and debugged an evolutionary search algorithm to find the "best" evolved homogeneous swarm to use as a baseline. While this approach seems to be working, it is a slow process as the swarm as to simulated for around 10000 iterations to be sure whether its going to fail to achieve the goals.
Once I have made it past this step I'll post another video of the evolved homogenous swarm.
-
Effects of Flocking
05/11/2016 at 08:40 • 0 commentsWhile the current random walk approach to swarm robotics I am using does eventually solve the problems provided, its not very efficient, nor does it feel particularly "swarmy". To that end I've added another behavior to the system, the ability to flock.
Now presently these machines are not equipped with a gps, nor are they expected to have sufficient processing power for accurate telemetry tracking to be feasible. ( I have some ideas on this, but they will have to wait for a later stage of the project) As such none of the drones actually know their location on the map. They do track their direction however to some reasonable degree so I am using this directional information to allow the system to "flock".
There are a few issues with a "pure" flocking strategy that arise. If the drones are allowed to have their flocking behavior subsume wander 100% of the time, they end up stuck in the bottom right hand corner of the work area. They simply never move far enough out of that position to ever reach the remaining goals even after an absurd number of iterations.
![]()
To get around this issue, I've made the flocking behavior probabilistic. At any given time a drone signals its fellow drones its current believed heading with some randomly chosen probability. (this is set for each individual drone at creation time). A drone responds to these signals probabilistic as well. By having these responses stochastic rather than deterministic room is left for the wander module to do its work and push the swarm into regimes. A demonstration of this behavior can be seen in the youTube video below.
As can be observed in the video, the behavior isn't perfect yet. Many individuals find themselves easily separated from the rest of the swarm, an issue that becomes more exasperated as the swarm gets larger in comparison to the available space. However, even this imperfect approach is vastly superior to the random walk method that was originally used.
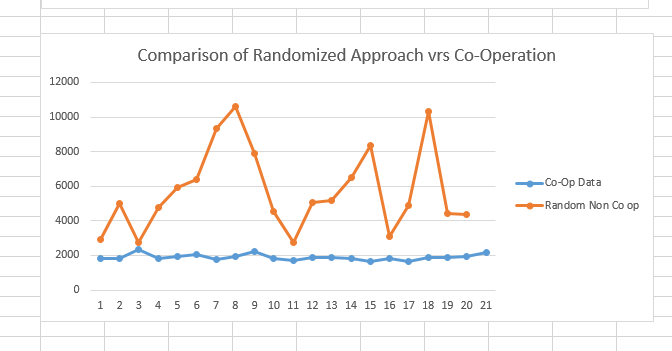
The chart below shows a comparison over 20 trials between the Random Walk approach, and the Co-Operative flocking behavior.
![]()
This is a substantial improvement over the randomized approach.
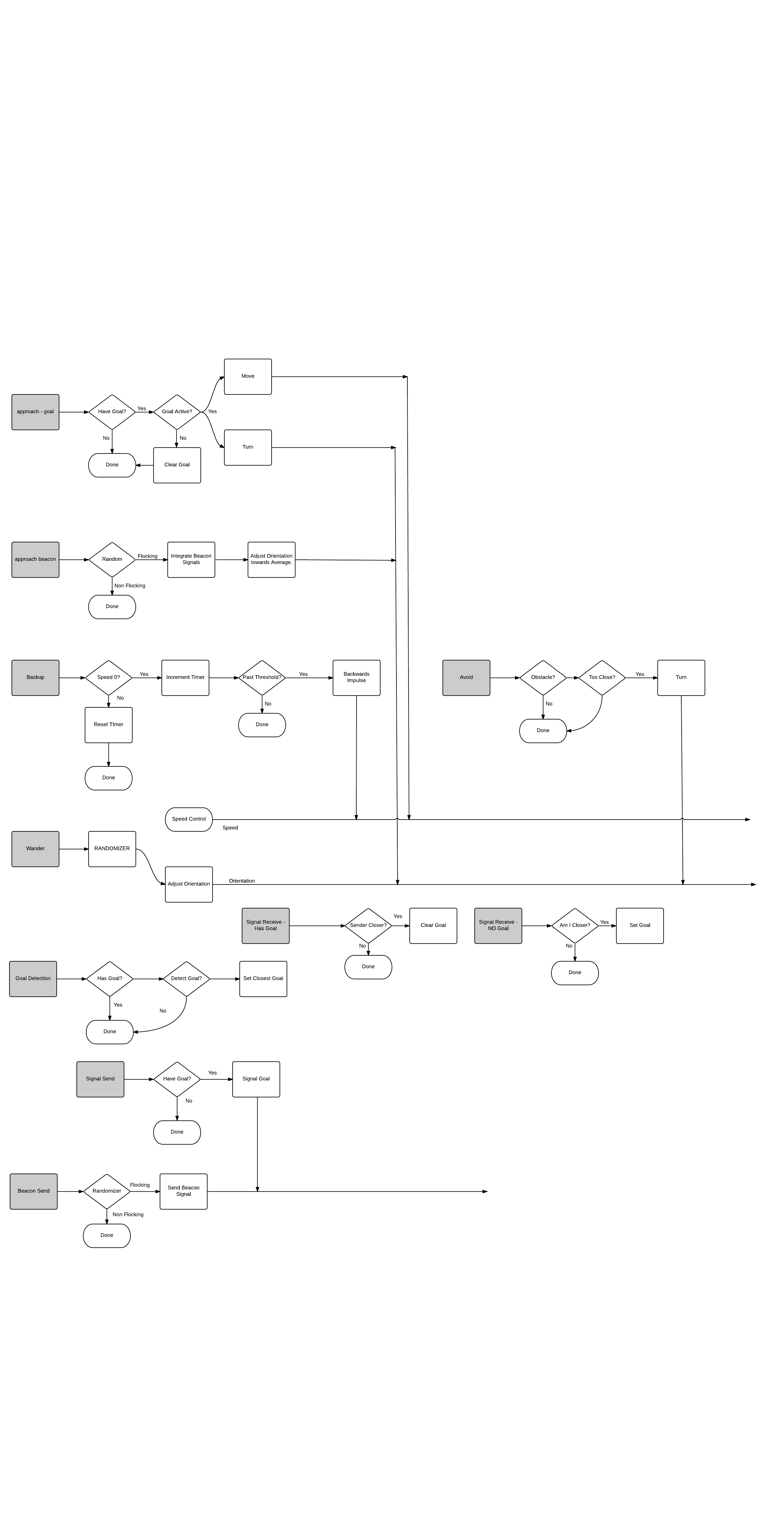
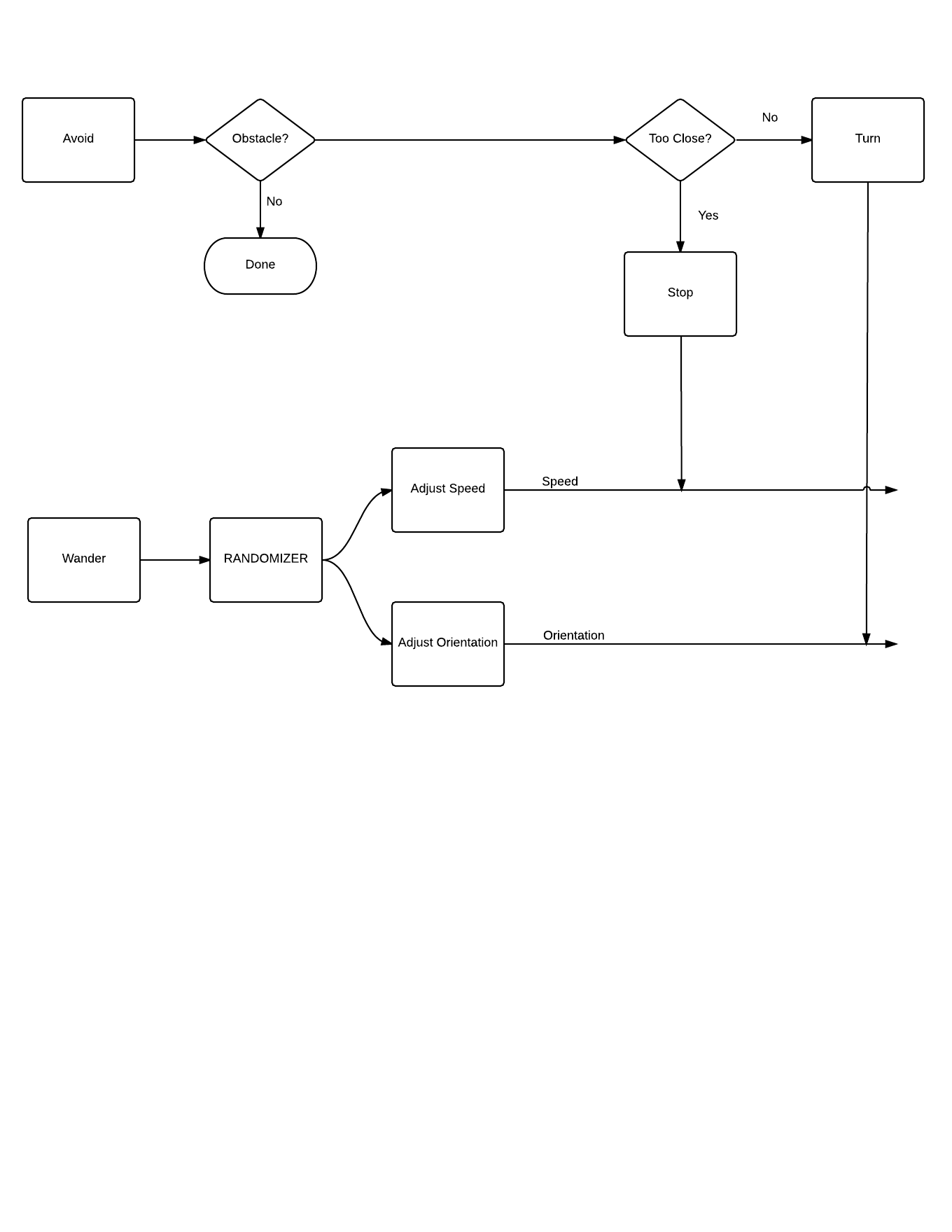
To get this to work, some behaviors were modified to accommodate flocking. These are listed below:
- Added approach beacon behavior that averages the direction of all incoming beacon signals (counting its own direction as double weight) and turns the device towards the average direction.
- Add signal beacon behavior that sends out the devices current direction. This behavior is subsumed by the goal signaling behavior.
- Updating the avoid behavior to always turn in the same direction. Doing otherwise creates too much randomness and destroys the flocking effect.
- Removed the emergency stop portion of the avoid behavior. This was only needed to get around a bug in the simulation software that has since been repaired.
A new diagram representing these behaviors is attached below.
![]()
-
Debugging
05/10/2016 at 12:57 • 0 commentsIn the process of debugging the simulation I worked out how the drones where exploiting the simulation to go through walls as observed in my previous log update. Turned out there was a bug in the code that handled the subsumption logic where the avoid logic was not overriding the other behaviors. I've fixed this bug and will submit the fix to git shortly. However, the result of this is that the previous data is rendered inadmissible. I will thus need to run the experiment again to get a baseline measurement for the system. This data will reported tonight, early tommorow as I find time to run the additional simulations.
-
Performance Stats
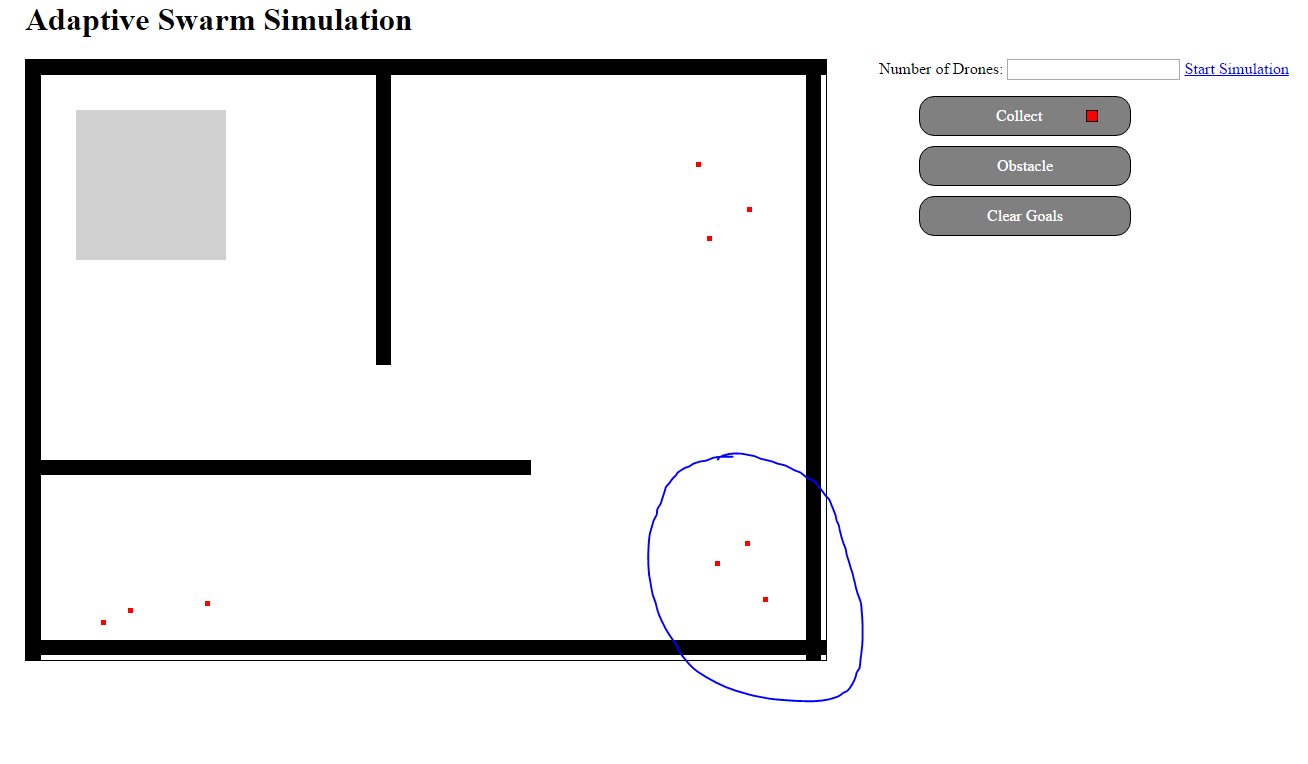
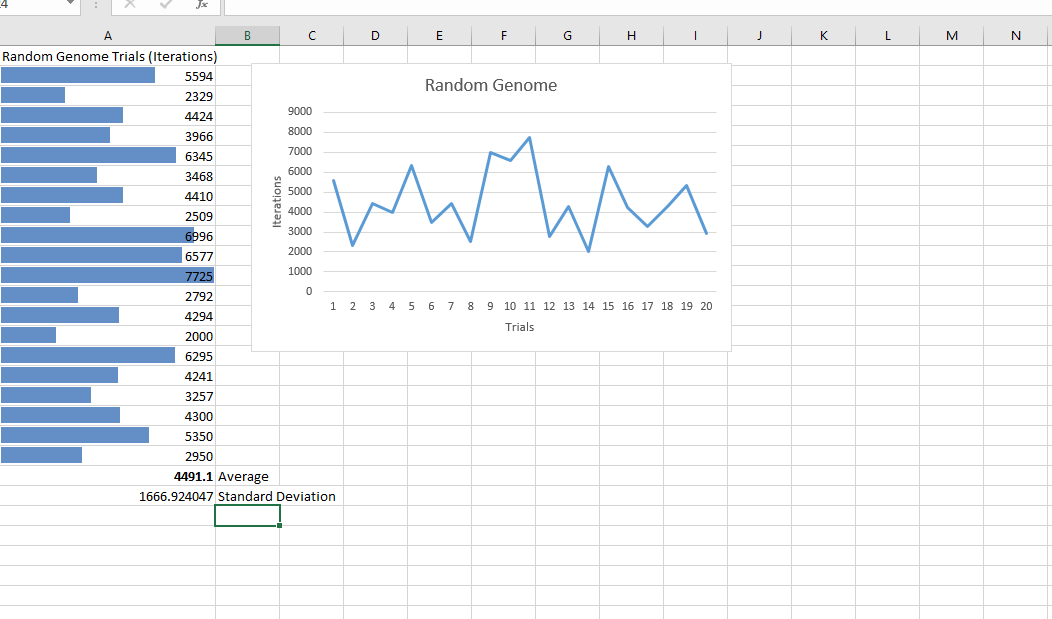
05/09/2016 at 21:34 • 0 commentsIn order to compare different methods for having the swarms adapt their behavior I need a baseline. To get this baseline I have setup a static environment with static goals in the simulation and run the simulation 20 times using 25 drones. The simulation counts the number of iterations until all the goals have been collected and reports that value back to the screen.
![]()
The individual parameters of each individual in the swarm are randomly chosen at the start of the simulation. The grey box represents the "deployment" zone of the drones. After running 20 trials of this experiment, I collected the following data which will be used to determine the performance of the adaptions I will be putting in place next:
![]()
As one might expect from using random settings for the robots, the results are fairly random. A few observations are in order however regarding some patterns I noticed while running this trials:
- Drones that have small enough settings for their collision thresholds will sometimes "exploit" the simulation and move though walls. This is caused by me actually representing the walls as a series of circles in the simulation and depending on the thresholds to keep the machines "away" from them.
- Most Drone settings are pretty unhelpful. With the wander probabilities too high, the machines simply jitter around not doing much.
- Drones that were able to "follow" the walls where the most successful at getting to goals. I haven't pulled the settings this drones used (as I haven't built a way to get that information out of the simulation yet), but I suspect this behavior comes about as a balance between collision threshold and the turning radius.
Anyway, there isn't a lot I want to say about this data set yet, I am including it for completeness, and to provide a yard stick via which I can measure the more interesting approaches performance (or lack there of as the case may be).
Depending on the outcome of the of the adaption experiments, I may need to add or tweak the existing behaviors in the drones. Once I have found the "sweet" spot of simple behaviors and adaption I will add the final subumption diagram to the project.
-
Parameter Tuning
05/08/2016 at 23:13 • 0 commentsIn the logs up to this point I've been pretty quiet about the different parameters that need to be tuned to get the system to run efficiently. Now that I am trying to use this method to tackle more difficult problems however, the parameters are starting to make a significant impact on whether a given swarm succeeds or fails.
Consider the following test scenario I've attached below. Here the swarm is being asked to work in an office environment. The swarm is released in the office and expected to examine different positions throughout the workplace. This challenge is significant as it the swarms neither have any pre-built map of the world, nor do they make one.
![]()
With no map, they depend on the wander behavior to make it though the doorway to any goals in the Lunch Room or Hallway. The ability to make it though that doorway depends strongly on the parameters that have been chosen. Currently these parameters are static and global - the swarm individuals cannot vary their own parameters, and all have the same identical settings.
Those parameters are:
- Sensor Range
- Safety Distance - distance that a drone will allow itself to get to an obstacle before turning away.
- Emergency Stop Distance
- Maximum Speed
- Radio Distance - how far away a drone can signal another drone.
- Speed / Orientation increments - how much to turn / adjust speed
- wander probability of turn
- wander probability of change in speed
Many of these parameters would be intrinsic to the drones themselves and will be assumed to never vary. Specifically Maximum Speed, Sensor Range, and Radio Distance are limitations set by the hardware. The remaining parameters are under the control of our algorithm to a certain extend.
It would not be user friendly to expect an end user to have to adjust these parameters to fit their problem, so simply allowing the user to specify these and hope for the best is not a route I am going to take with this project. Instead I am investigating three possible methods of varying the parameters.
- Randomize the parameters when the machine starts up. This should give a wide range of individuals in the swarm, although it runs the risk of having "holes" in the parameter space where say a certain set of parameters would allow individuals to pass through the door between the Lunch Room and Office are simply not actualized on a real machine. This could of course be mitigated by simply adding more drones, but that seems mildly unreasonable in many real life scenarios.
- Use the signaling system to trigger the drones to "adapt" their parameters. In this scenario drones that have found goals could broadcast successful parameters to other drones, which could adjust their current settings closer to the successful members of their swarm. In this way drones can learn the best parameters that work for them individually.
- As in option 2, use the signaling system to share successful parameters. Instead of an approach where the receiver moves their parameters closer to the successful ones, it simple copies the useful parameters over to itself. In addition, with some preset probability the copy will be imperfect, and result in either a mutation of the original, a cross over operation with the original, or both (I will explain further in a future update). This is analogous to the evolutionary algorithms, where fitness here is all or nothing. Either the parameters succeed is getting the goal, or they die.
It was my original plan to wait until the final step to work on varying the parameters, I am changing course now because of the difficulties seen in the office test where I am forced to manually tune the parameters to get results. Also, from my perspective, this is the most interesting part of the project so I won't pretend I wasn't biased to skip to it early to begin with.
Next will show the behavior of the system using method 1 to vary the parameters. I'll provide a few videos and collect some performance metrics to use as a baseline to compare to methods 2 and 3 which will be done in subsequent updates.
-
Stage 1 in Action
05/07/2016 at 17:59 • 0 commentsThe linked youTube video shows the simplest version of the described drone swarm in action. At this point the goals are nothing more than points that need to be reached by at least one member of the group.
I've tested this with a kind of multi-modal problem - the points to be reached are clustered on different corners of the map. In order to provide a realistic deployment scenario, the individual robots are let loose on the upper left hand quadrant.
My next step is introduce complex environments. I want to pose the same goal problems to a swarm release inside a home, office, or other obstacle filled area. In these cases the goals could be interpreted as checkpoints that need to be examined in a security sweep, or perhaps potential areas of the home where survivors of some disaster might be found.
The final step after that will the implementation of more complex goals, at present I am thinking of two main types of goals to add:
- Multi-step goals, robot collects an object and deposits in a pre-defined goal position. This could be used for swarms that are responsible for collecting waste, or retrieving missing material from dangerous locations.
- Timed goals - instead of the goal ending as soon as it is reached, it is only marked as complete after some undetermined number of iterations. This could be analogous to a firefighting robot, searching an area and fighting the flames until they are out.
- Co-operative goals, these goals are only completed when an undetermined number of individuals reach them.
Anyway, please enjoy this video in the meantime.
-
Using Signals to Co-ordinate Behavior
05/07/2016 at 11:44 • 0 commentsWith the basic wander / avoid / backup behaviors in place, its time to expand on the virtual drones behaviors in order to make it possible for them to co-operate with each other. As these machines must at least in theory be realizable as physical devices, these needs to be done within the confines of the subsumption framework. (It would not do to assume the existence of some over-reaching algorithm with global access to every drone that modified their behavior from the outside. Such an approach would not be practical for a physical swarm).
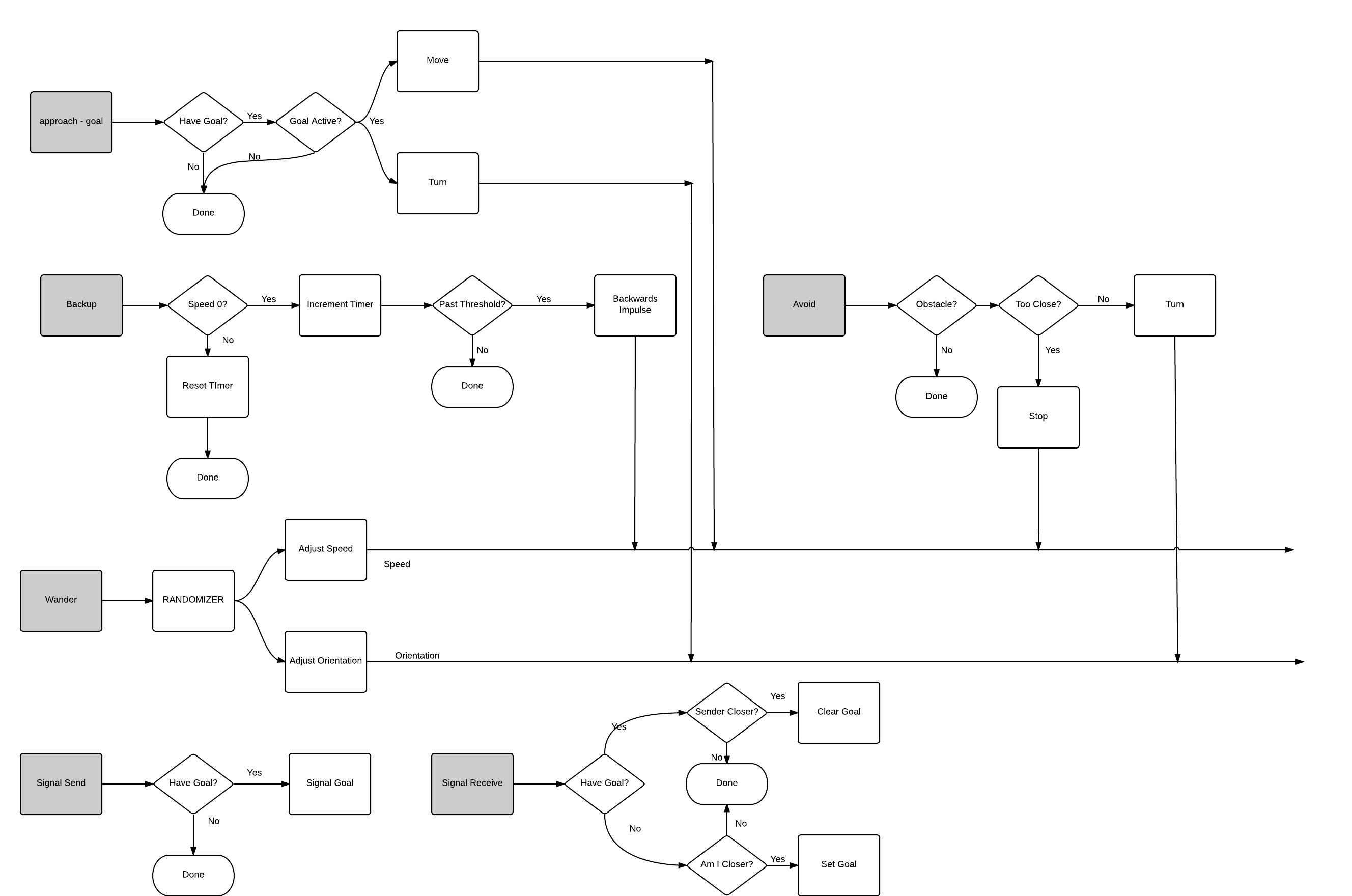
Co-ordination is achieved using three new behaviors which I have added to the updated subsumption architecture I've attached below.
approach - goal: This requires the ability to store a goal state. The goal state is assumed to be a shared memory between all modules. If the system current has a goal state, and that goal still shows up in the sensory input, this behavior moves the individual machine towards the goal.
signal send: This is a simple decision behavior, if there is a goal in the shared memory, send a signal to nearby swarm maters that the individual is pursuing it.
signal receive: This is the key to how these devices will co-operate. When signals are received, each individual compares the signals to their current goals. If they have a current goal, but a local swarm mate has signaled that it is closer to the goal, the individual forgets the goal. If it doesn't, and this individual is closer to a detected goal than any of the signaled goal chasers are, it takes up the goal.
This should create a form of competition between the individual swarm maters where the winner will the device best suited towards achieving the goal. Later on, when grapple, drop, tag, and map actions are added, behaviors can be added that will subsume the signal send, signal receive behaviors to enforce pre-requisites for certain tasks. For example a grapple behavior could subsume the signal send behavior in cases where the individual is chasing a COLLECT goal while already carrying another object.
My goal over the next few days is update the current simulation with the new behaviors and test them out. Once they have been integrated and tested I'll update the code in github so that anyone interested can pull the code and play around with these methods themselves.
![]()
-
Quick Update
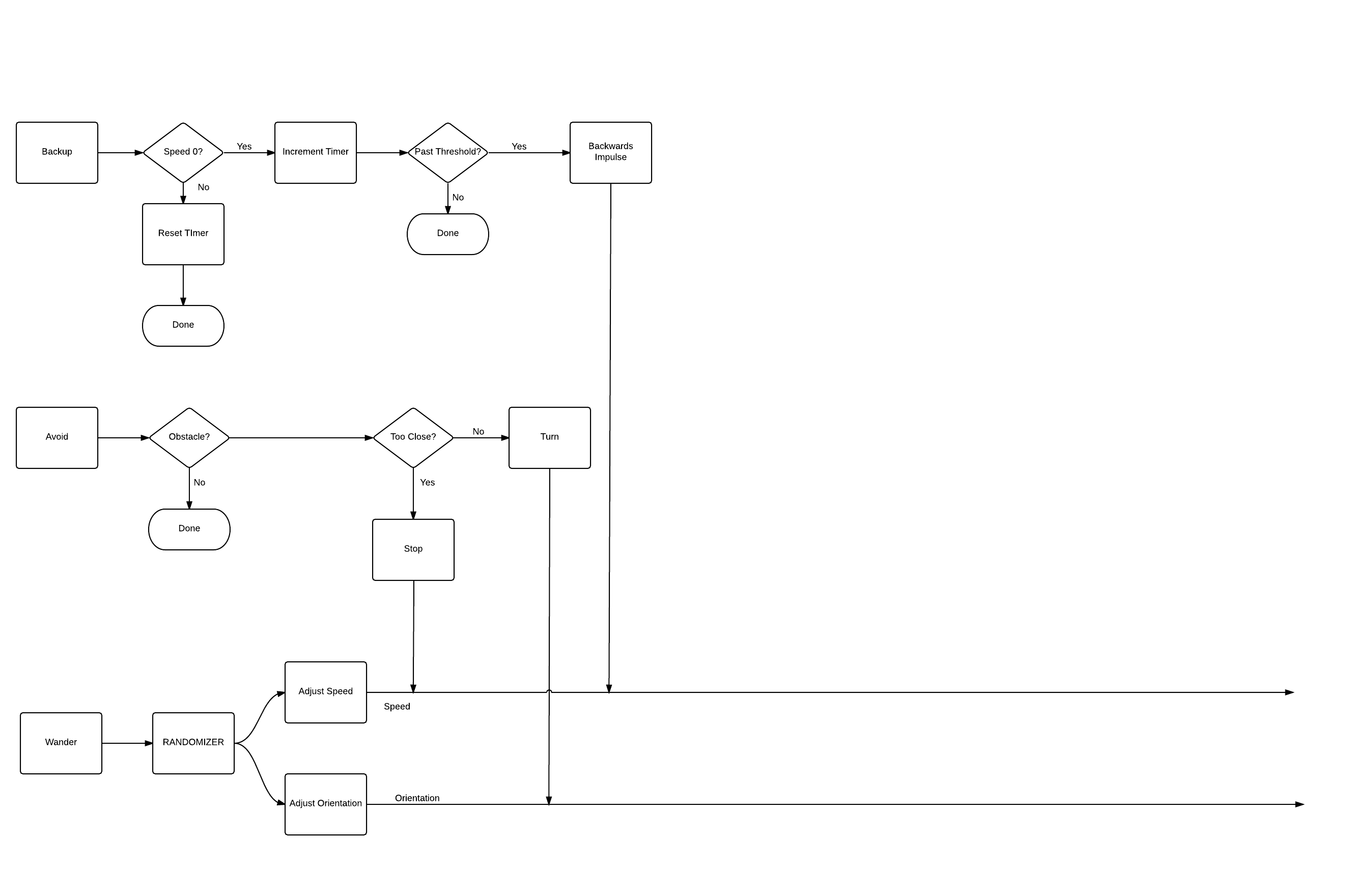
05/06/2016 at 17:01 • 0 commentsI have attached the projects repo to this page, so current code can be downloaded. I also made a small addition to the subsumption system I described in my last post which I will append below. Basically the virtual robots would get stuck a lot, so the the backup mechanism was added to alleviate that pain until goals have been added.
![]()
-
Subsumption Architecture
05/06/2016 at 11:33 • 0 commentsAs mentioned in the details, the virtual Drone's used in my project will be modeled using a behavioral robotics approach inspired by Dr. Rodney Brooks and Jonathan Connell. Specifically these machines will be assumed to be using a subsumption architecture.
Virtual Drones will be modeled one step at a time, increasing their capabilities in each case. For the current stage, where I just want the machines to show up in the simulated environment to test the UI, I will be modeling only the first two competencies - wander and avoid.
The idea here is illustrated by the diagram below, but I'll provide a brief explanation. The lowest "level" of competency for the virtual drone is the "wander" competency. Wander basically pushes the drone around in a random direction. In this way, if the drone has nothing to do, its wander system will activate and start moving the machine around until new inputs can be found.
Avoid is the second level of competency. It checks the sensor data to see if there is an obstacle in front of the drone. No obstacle, means avoid does nothing. If the obstacle is too close for a safe turn, then it will send the stop signal, overriding any output from the "adjust speed" command of the wander level. If it can safely turn, it will do so, override any "adjust orientation" output from the wander level.
As I integrate the different types of goals into the simulation, new functionality will be built onto the drones using this same approach. Each module will operate separately, overriding lower level outputs as required. One possible example of this might be the gripper. To grip something the drone wants to be stationary, so if it senses something to "grip", the gripper module may subsume the speed outputs of the avoid / wander modules and stop the robot until the grip process is complete.
I will update this flow chart as I add new competencies to the simulation. Next update should include an example of the basic simulation in action with the drones using a simulated version of the behaviors described here. I'll also provide a github link for those who wish to play around for themselves.
![]()
Drone Swarm Control Algorithms
I want to look at control methods for swarms that can be adapted to problems in the real world.