pjkim00
pjkim00-
Prolific authors/submitters and other tidbits
06/09/2016 at 23:46 • 0 commentsI'll continue to put up interesting things as I think of them. Here are a few interesting tidbits.
Most often used post tags:
misc hacks 2327 Arduino Hacks 1792 news 1492 classic hacks 1291 robots hacks 1248 tool hacks 1200 home hacks 1024 led hacks 1024 Microcontrollers 893 Hackaday Columns 813 peripherals hacks 778 Featured 750 transportation hacks 742 slider 711 3d Printer hacks 696 hardware 661 security hacks 657 Raspberry Pi 634 digital cameras hacks 589 home entertainment hacks 587 Perhaps unsurprisingly, arduino hacks are near the top of the list.
If you look at the most prolific authors you get:
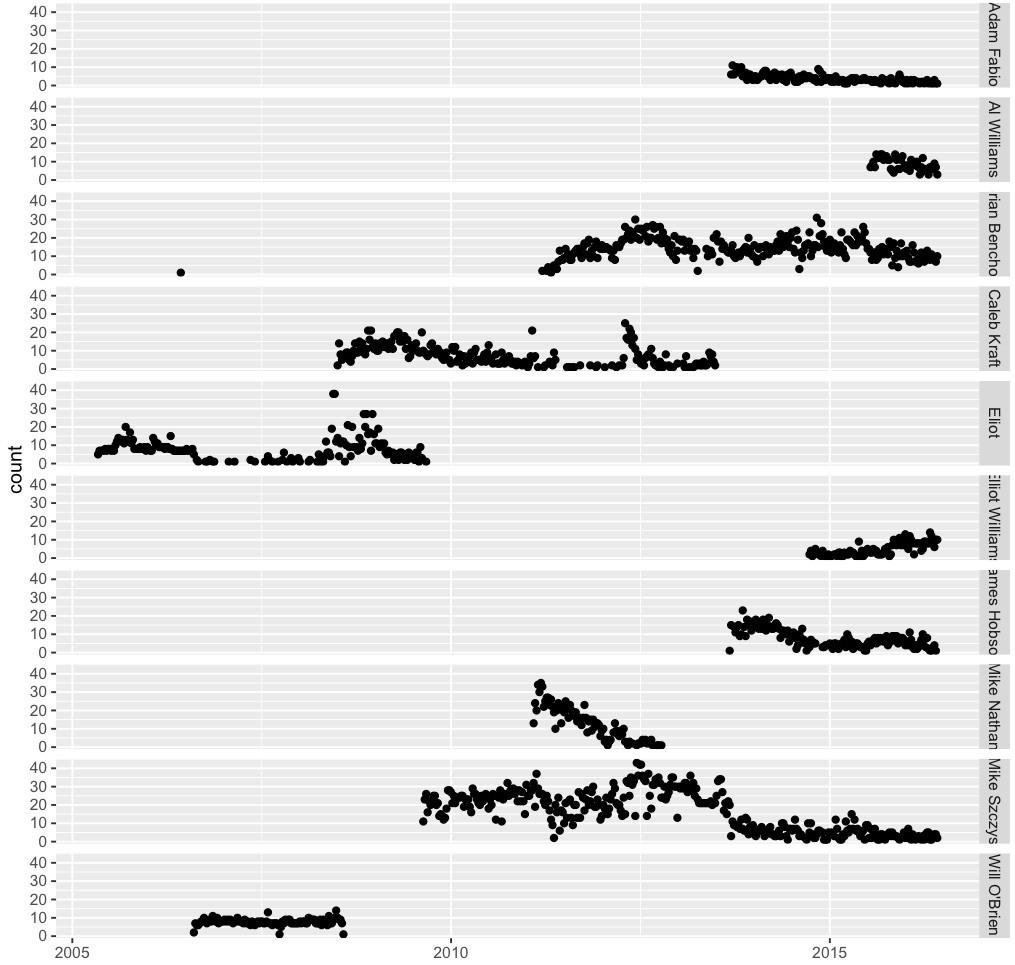
Mike Szczys 5716 Brian Benchoff 3834 Caleb Kraft 1567 Eliot 1332 James Hobson 1063 Mike Nathan 1039 Will O'Brien 805 Adam Fabio 530 Elliot Williams 405 Al Williams 401 Kristina Panos 322 Rich Bremer 290 Jakob Griffith 269 Eric Evenchick 265 Rick Osgood 225 Gerrit Coetzee 215 Marsh 213 Jeremy Cook 199 Dan Maloney 198 Bryan Cockfield 187 Kevin Dady 187 Mathieu Stephan 180 Anool Mahidharia 160 Juan Aguilar 160 Vine Veneziani 137 Plotting the number of articles per week, segregated by the top ten authors, over time gives the following picture:
![]()
You can clearly see where submitters became active and when when they stopped. Brian had a early submission somewhere in 2006 before he joined HAD. Mike Szczys was active early and then starting tailing off around 2013-- other behind the scenes activities I imagine.
-
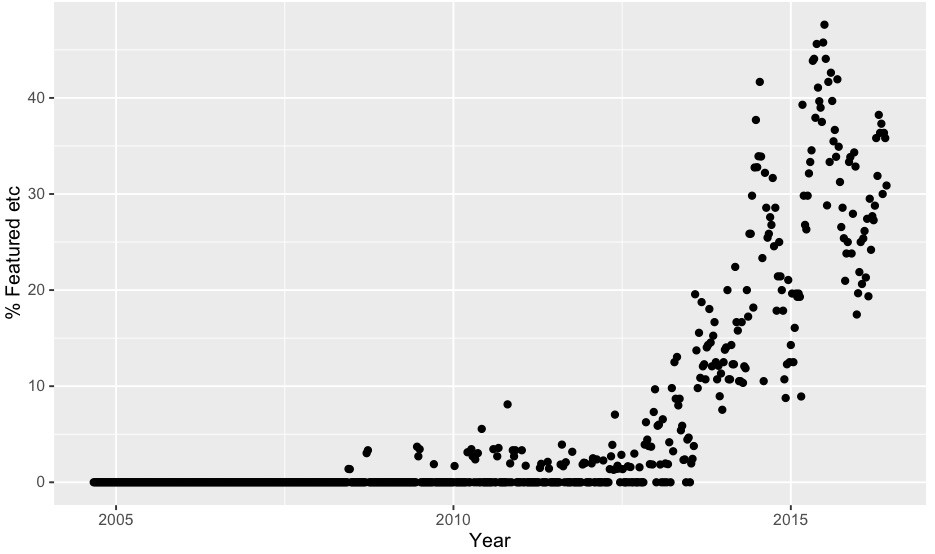
Featured articles over time
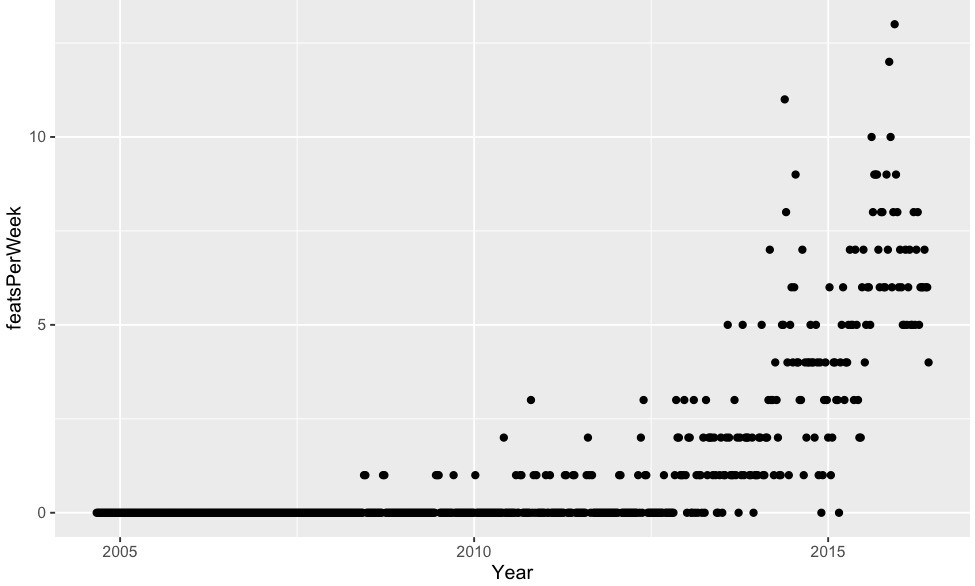
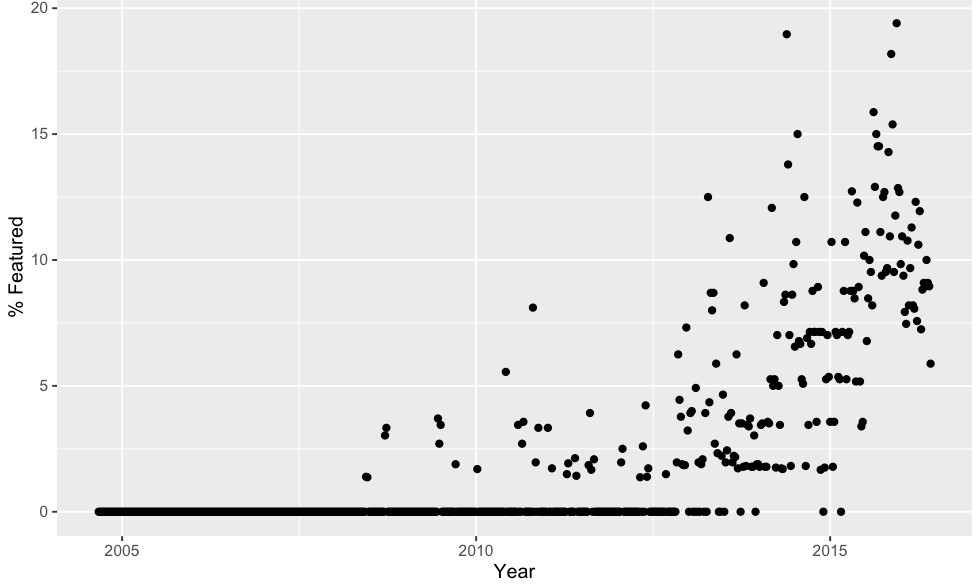
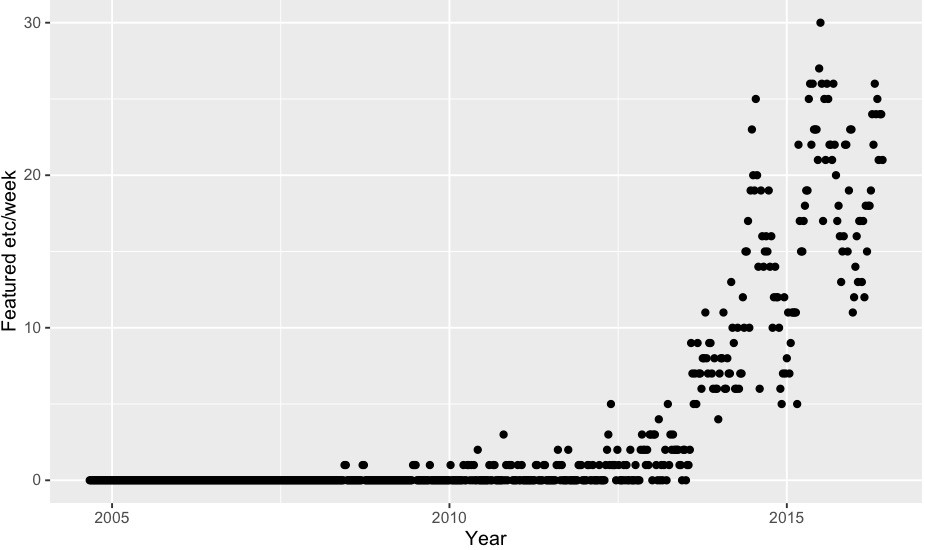
06/09/2016 at 18:08 • 0 commentsHere is the data requested: featured per week and %featured.
![]()
![]()
The above was for articles with the "Featured" post marker. If you include "Featured","Retrotechtacular","Hackaday Columns", "The Hackaday Prize", "Ask Hackaday", "Hackaday Store", "Interviews", that roughly triples the number of articles, but the overall shape looks the same.
![]()
![]()
-
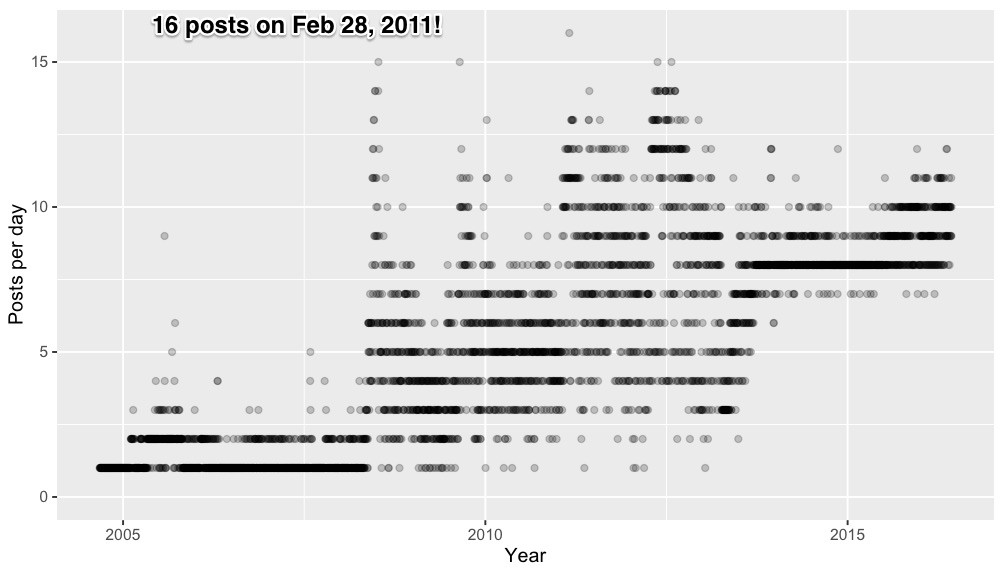
Fris Plot
06/09/2016 at 08:19 • 0 commentsOK, first plot of the data before I go to bed. I munged the data and plotted posts per day as a function of time. Not surprisingly, the number of posts per day have been going up since the early days. Somewhat surprisingly the maximum posts per day was way back in Feb 28, 2011 when there were no less than 16 posts! Here you go:
![]()
Staying true to its name, most days early on had one article per day. Now the mode appears to be 8 per day.
-
Scraping the HAD website
06/09/2016 at 06:48 • 1 commentI started off knowing nothing about web scraping. I found a good link which shows how to scrape using python:
http://docs.python-guide.org/en/latest/scenarios/scrape/
Found a few websites that explain the xtree syntax and I was off to the races. So a few baby steps first.
from lxml import html import requests page = requests.get('http://hackaday.com/blog/page/3000/') tree = html.fromstring(page.content) # get post titles tree.xpath('//article/header/h1/a/text()') # get post IDs tree.xpath('//article/@id') # get Date of publication tree.xpath('//article/header/div/span[@class="entry-date"]/a/text()')Eventually wrote a script to scrape the entire HAD archives. On Wednesday June 8th at 11PM Pacific time, it had 3223 pages. Decided to include article ID, date of publication, title, author, #comments, "posted ins", and tags. Here is a quick and dirty python script to output all data to a tab delimited file:
from lxml import html import requests fh = open("Hackaday.txt", 'w') for pageNum in xrange(1,3224,1): page = requests.get('http://hackaday.com/blog/page/%d/'%pageNum) tree = html.fromstring(page.content) titles = tree.xpath('//article/header/h1/a/text()') postIDs = tree.xpath('//article/@id') dates = tree.xpath('//article/header/div/span[@class="entry-date"]/a/text()') authors = tree.xpath('//article/header/div/a[@rel="author"]/text()') commentCounts = tree.xpath('//article/header/div/a[@class="comments-counts comments-counts-top"]/text()') commentCounts =[i.strip() for i in commentCounts] posts = [] tags = [] for i in xrange(len(titles)): posts.append(tree.xpath('//article[%d]/footer/span/a[@rel="category tag"]/text()'%(i+1))) tags.append(tree.xpath('//article[%d]/footer/span/a[@rel="tag"]/text()'%(i+1))) for i in xrange(len(titles)): #print postIDs[i] + '\t' + dates[i] +'\t' +titles[i] +'\t' + authors[i]+'\t'+commentCounts[i]+ '\t' + ",".join(posts[i]) + '\t' + ",".join(tags[i]) fh.write(postIDs[i] + '\t' + dates[i] +'\t' +titles[i] +'\t' + authors[i]+'\t'+commentCounts[i]+ '\t' + ",".join(posts[i]) + '\t' + ",".join(tags[i]) + '\n') fh.close()I felt a bit guilty about scraping the entire website but Brian said it was OK. The html file for each page is ~60KB times 3223 pages is about 193 MB of data. This was distilled down to 3.5 MB of data and took about 25 minutes.
The latested post is #207753 and the earliest is post # 7. The numbers are not sequential and there are total of 22556 articles. The file looks like this
post-207753 June 8, 2016 Hackaday Prize Entry: The Green Machine Anool Mahidharia 1 Comment The Hackaday Prize 2016 Hackaday Prize,arduino,Coating machine,grbl,Hackaday Prize,linear motion,motor,raspberry pi,Spraying machine,stepper driver,the hackaday prize post-208524 June 8, 2016 Rainbow Cats Announce Engagement Kristina Panos 1 Comment ATtiny Hacks attiny,because cats,blinkenlights,RGB LED,smd soldering,wedding announcements post-208544 June 8, 2016 Talking Star Trek Al Williams 8 Comments linux hacks,software hacks computer speech,natural language,speech recognition,star trek,text to speech,voice command,voice recognition ..... post-11 September 9, 2004 hack the dakota disposable camera Phillip Torrone 1 Comment digital cameras hacks post-10 September 8, 2004 mod the cuecat, and scan barcodes… Phillip Torrone 1 Comment misc hacks post-9 September 7, 2004 make a nintendo controller in to a usb joystick Phillip Torrone 22 Comments computer hacks,macs hacks post-8 September 6, 2004 change the voice of an aibo ers-7 Phillip Torrone 10 Comments robots hacks post-7 September 5, 2004 radioshack phone dialer – red box Phillip Torrone 38 Comments misc hacksI'll upload a zipped version. Hopefully this will save HAD from being scraped over and over again.I'll start slicing and dicing the data soon.Addendum: for whatever reason, two articles were missing the posts/tags fields. I fixed them manually and uploaded the corrected file.